 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing a Human-AI Teaming Approach to Create and Curate Scientific Datasets with the SCILIRE System
Mar 13, 2026The rapid growth of scientific literature has made manual extraction of structured knowledge increasingly impractical. To address this challenge, we introduce SCILIRE, a system for creating datasets from scientific literature. SCILIRE has been designed around Human-AI teaming principles centred on workflows for verifying and curating data. It facilitates an iterative workflow in which researchers can review and correct AI outputs. Furthermore, this interaction is used as a feedback signal to improve future LLM-based inference. We evaluate our design using a combination of intrinsic benchmarking outcomes together with real-world case studies across multiple domains. The results demonstrate that SCILIRE improves extraction fidelity and facilitates efficient dataset creation.
Aligning AI Research with the Needs of Clinical Coding Workflows: Eight Recommendations Based on US Data Analysis and Critical Review
Dec 23, 2024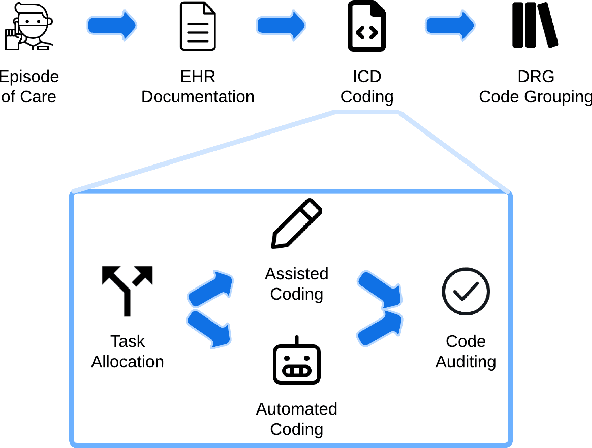
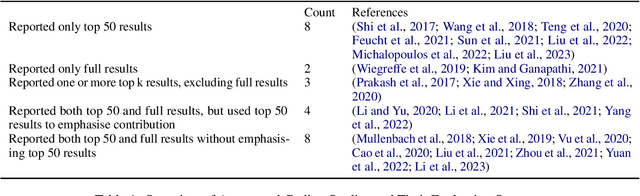
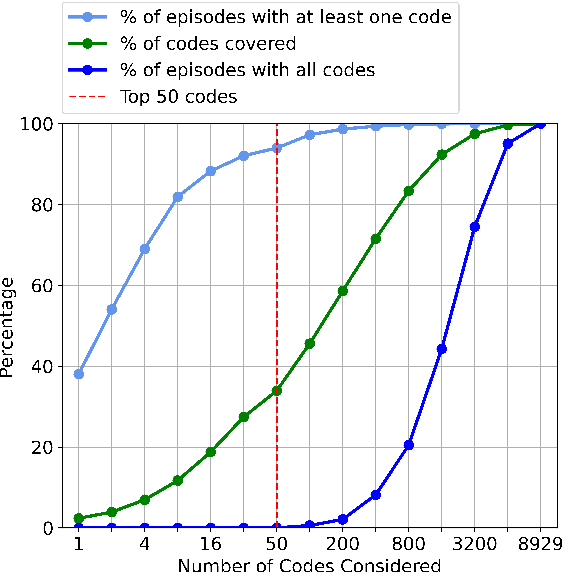

Clinical coding is crucial for healthcare billing and data analysis. Manual clinical coding is labour-intensive and error-prone, which has motivated research towards full automation of the process. However, our analysis, based on US English electronic health records and automated coding research using these records, shows that widely used evaluation methods are not aligned with real clinical contexts. For example, evaluations that focus on the top 50 most common codes are an oversimplification, as there are thousands of codes used in practice. This position paper aims to align AI coding research more closely with practical challenges of clinical coding. Based on our analysis, we offer eight specific recommendations, suggesting ways to improve current evaluation methods. Additionally, we propose new AI-based methods beyond automated coding, suggesting alternative approaches to assist clinical coders in their workflows.
Query-Focused Extractive Summarisation for Finding Ideal Answers to Biomedical and COVID-19 Questions
Aug 31, 2021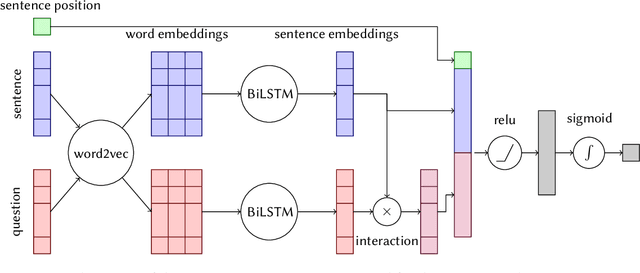
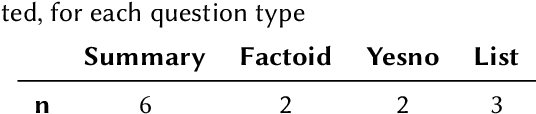
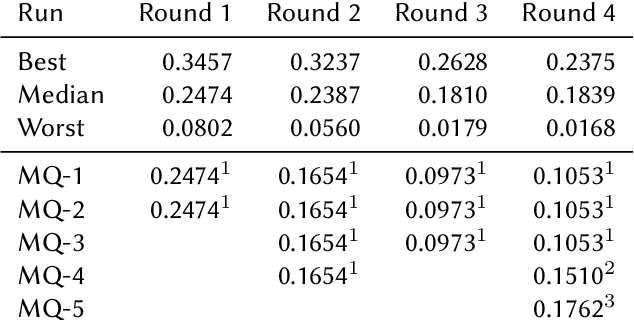
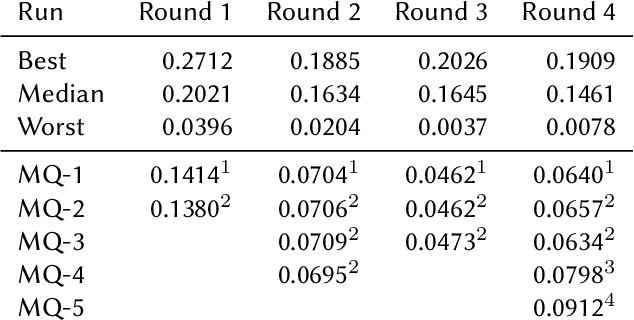
This paper presents Macquarie University's participation to the BioASQ Synergy Task, and BioASQ9b Phase B. In each of these tasks, our participation focused on the use of query-focused extractive summarisation to obtain the ideal answers to medical questions. The Synergy Task is an end-to-end question answering task on COVID-19 where systems are required to return relevant documents, snippets, and answers to a given question. Given the absence of training data, we used a query-focused summarisation system that was trained with the BioASQ8b training data set and we experimented with methods to retrieve the documents and snippets. Considering the poor quality of the documents and snippets retrieved by our system, we observed reasonably good quality in the answers returned. For phase B of the BioASQ9b task, the relevant documents and snippets were already included in the test data. Our system split the snippets into candidate sentences and used BERT variants under a sentence classification setup. The system used the question and candidate sentence as input and was trained to predict the likelihood of the candidate sentence being part of the ideal answer. The runs obtained either the best or second best ROUGE-F1 results of all participants to all batches of BioASQ9b. This shows that using BERT in a classification setup is a very strong baseline for the identification of ideal answers.