 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Students Don't Use LLMs Like You Wish They Did
Apr 26, 2026Educational NLP systems are typically evaluated using engagement metrics and satisfaction surveys, which are at best a proxy for meeting pedagogical goals. We introduce six computational metrics for automated evaluation of pedagogical alignment in student-AI dialogue. We validate our metrics through analysis of 12,650 messages across 500 conversations from four courses. Using our metrics, we identify a fundamental misalignment: educators design conversational tutors for sustained learning dialogue, but students mainly use them for answer-extraction. Deployment context is the strongest predictor of usage patterns, outweighing student preference or system design: when AI tools are optional, usage concentrates around deadlines; when integrated into course structure, students ask for solutions to verbatim assignment questions. Whole-dialogue evaluation misses these turn-by-turn patterns. Our metrics will enable researchers building educational dialogue systems to measure whether they are achieving their pedagogical goals.
An Empirical Analysis of Static Analysis Methods for Detection and Mitigation of Code Library Hallucinations
Apr 09, 2026Despite extensive research, Large Language Models continue to hallucinate when generating code, particularly when using libraries. On NL-to-code benchmarks that require library use, we find that LLMs generate code that uses non-existent library features in 8.1-40% of responses.One intuitive approach for detection and mitigation of hallucinations is static analysis. In this paper, we analyse the potential of static analysis tools, both in terms of what they can solve and what they cannot. We find that static analysis tools can detect 16-70% of all errors, and 14-85% of library hallucinations, with performance varying by LLM and dataset. Through manual analysis, we identify cases a static method could not plausibly catch, which gives an upper bound on their potential from 48.5% to 77%. Overall, we show that static analysis methods are cheap method for addressing some forms of hallucination, and we quantify how far short of solving the problem they will always be.
Simple and Effective Baselines for Code Summarisation Evaluation
May 26, 2025Code documentation is useful, but writing it is time-consuming. Different techniques for generating code summaries have emerged, but comparing them is difficult because human evaluation is expensive and automatic metrics are unreliable. In this paper, we introduce a simple new baseline in which we ask an LLM to give an overall score to a summary. Unlike n-gram and embedding-based baselines, our approach is able to consider the code when giving a score. This allows us to also make a variant that does not consider the reference summary at all, which could be used for other tasks, e.g., to evaluate the quality of documentation in code bases. We find that our method is as good or better than prior metrics, though we recommend using it in conjunction with embedding-based methods to avoid the risk of LLM-specific bias.
Should I Trust You? Detecting Deception in Negotiations using Counterfactual RL
Feb 18, 2025An increasingly prevalent socio-technical problem is people being taken in by offers that sound ``too good to be true'', where persuasion and trust shape decision-making. This paper investigates how \abr{ai} can help detect these deceptive scenarios. We analyze how humans strategically deceive each other in \textit{Diplomacy}, a board game that requires both natural language communication and strategic reasoning. This requires extracting logical forms of proposed agreements in player communications and computing the relative rewards of the proposal using agents' value functions. Combined with text-based features, this can improve our deception detection. Our method detects human deception with a high precision when compared to a Large Language Model approach that flags many true messages as deceptive. Future human-\abr{ai} interaction tools can build on our methods for deception detection by triggering \textit{friction} to give users a chance of interrogating suspicious proposals.
Aligning AI Research with the Needs of Clinical Coding Workflows: Eight Recommendations Based on US Data Analysis and Critical Review
Dec 23, 2024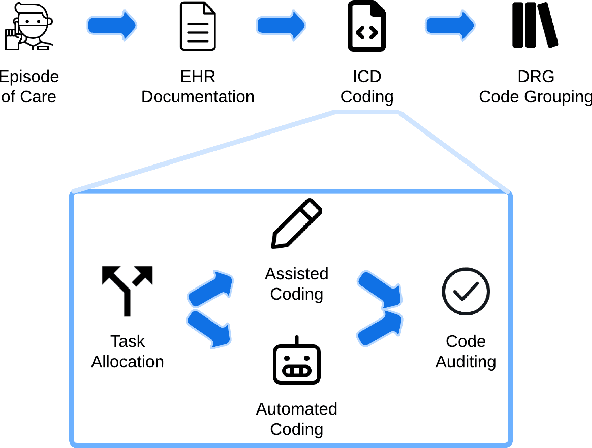
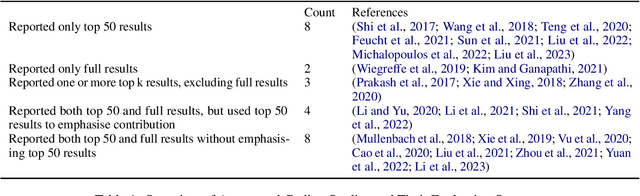
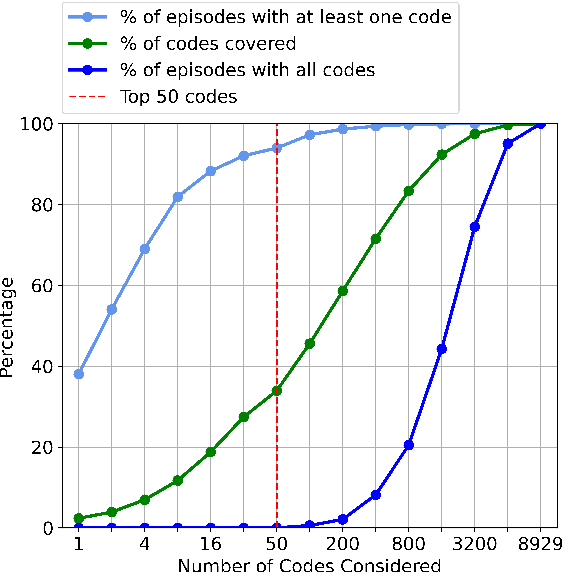

Clinical coding is crucial for healthcare billing and data analysis. Manual clinical coding is labour-intensive and error-prone, which has motivated research towards full automation of the process. However, our analysis, based on US English electronic health records and automated coding research using these records, shows that widely used evaluation methods are not aligned with real clinical contexts. For example, evaluations that focus on the top 50 most common codes are an oversimplification, as there are thousands of codes used in practice. This position paper aims to align AI coding research more closely with practical challenges of clinical coding. Based on our analysis, we offer eight specific recommendations, suggesting ways to improve current evaluation methods. Additionally, we propose new AI-based methods beyond automated coding, suggesting alternative approaches to assist clinical coders in their workflows.
Personalized Help for Optimizing Low-Skilled Users' Strategy
Nov 14, 2024AIs can beat humans in game environments; however, how helpful those agents are to human remains understudied. We augment CICERO, a natural language agent that demonstrates superhuman performance in Diplomacy, to generate both move and message advice based on player intentions. A dozen Diplomacy games with novice and experienced players, with varying advice settings, show that some of the generated advice is beneficial. It helps novices compete with experienced players and in some instances even surpass them. The mere presence of advice can be advantageous, even if players do not follow it.
SQLucid: Grounding Natural Language Database Queries with Interactive Explanations
Sep 10, 2024



Though recent advances in machine learning have led to significant improvements in natural language interfaces for databases, the accuracy and reliability of these systems remain limited, especially in high-stakes domains. This paper introduces SQLucid, a novel user interface that bridges the gap between non-expert users and complex database querying processes. SQLucid addresses existing limitations by integrating visual correspondence, intermediate query results, and editable step-by-step SQL explanations in natural language to facilitate user understanding and engagement. This unique blend of features empowers users to understand and refine SQL queries easily and precisely. Two user studies and one quantitative experiment were conducted to validate SQLucid's effectiveness, showing significant improvement in task completion accuracy and user confidence compared to existing interfaces. Our code is available at https://github.com/magic-YuanTian/SQLucid.
Do Text-to-Vis Benchmarks Test Real Use of Visualisations?
Jul 29, 2024



Large language models are able to generate code for visualisations in response to user requests. This is a useful application, and an appealing one for NLP research because plots of data provide grounding for language. However, there are relatively few benchmarks, and it is unknown whether those that exist are representative of what people do in practice. This paper aims to answer that question through an empirical study comparing benchmark datasets and code from public repositories. Our findings reveal a substantial gap in datasets, with evaluations not testing the same distribution of chart types, attributes, and the number of actions. The only representative dataset requires modification to become an end-to-end and practical benchmark. This shows that new, more benchmarks are needed to support the development of systems that truly address users' visualisation needs. These observations will guide future data creation, highlighting which features hold genuine significance for users.
More Victories, Less Cooperation: Assessing Cicero's Diplomacy Play
Jun 07, 2024The boardgame Diplomacy is a challenging setting for communicative and cooperative artificial intelligence. The most prominent communicative Diplomacy AI, Cicero, has excellent strategic abilities, exceeding human players. However, the best Diplomacy players master communication, not just tactics, which is why the game has received attention as an AI challenge. This work seeks to understand the degree to which Cicero succeeds at communication. First, we annotate in-game communication with abstract meaning representation to separate in-game tactics from general language. Second, we run two dozen games with humans and Cicero, totaling over 200 human-player hours of competition. While AI can consistently outplay human players, AI-Human communication is still limited because of AI's difficulty with deception and persuasion. This shows that Cicero relies on strategy and has not yet reached the full promise of communicative and cooperative AI.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.