 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Making with Deliberation: Meta-reviewing as a Document-grounded Dialogue
Aug 07, 2025Meta-reviewing is a pivotal stage in the peer-review process, serving as the final step in determining whether a paper is recommended for acceptance. Prior research on meta-reviewing has treated this as a summarization problem over review reports. However, complementary to this perspective, meta-reviewing is a decision-making process that requires weighing reviewer arguments and placing them within a broader context. Prior research has demonstrated that decision-makers can be effectively assisted in such scenarios via dialogue agents. In line with this framing, we explore the practical challenges for realizing dialog agents that can effectively assist meta-reviewers. Concretely, we first address the issue of data scarcity for training dialogue agents by generating synthetic data using Large Language Models (LLMs) based on a self-refinement strategy to improve the relevance of these dialogues to expert domains. Our experiments demonstrate that this method produces higher-quality synthetic data and can serve as a valuable resource towards training meta-reviewing assistants. Subsequently, we utilize this data to train dialogue agents tailored for meta-reviewing and find that these agents outperform \emph{off-the-shelf} LLM-based assistants for this task. Finally, we apply our agents in real-world meta-reviewing scenarios and confirm their effectiveness in enhancing the efficiency of meta-reviewing.\footnote{Code and Data: https://github.com/UKPLab/arxiv2025-meta-review-as-dialog
Diagnostic Reasoning in Natural Language: Computational Model and Application
Sep 09, 2024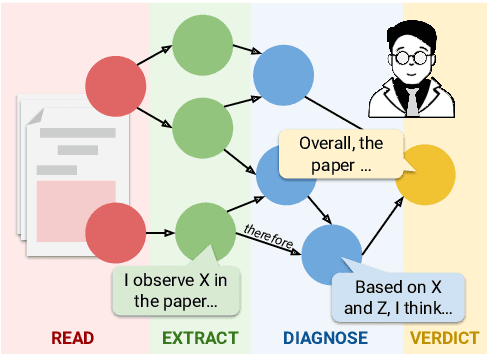
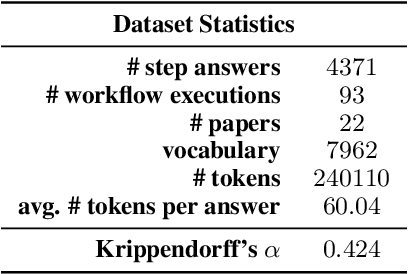
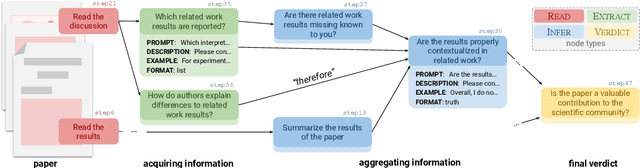

Diagnostic reasoning is a key component of expert work in many domains. It is a hard, time-consuming activity that requires expertise, and AI research has investigated the ways automated systems can support this process. Yet, due to the complexity of natural language, the applications of AI for diagnostic reasoning to language-related tasks are lacking. To close this gap, we investigate diagnostic abductive reasoning (DAR) in the context of language-grounded tasks (NL-DAR). We propose a novel modeling framework for NL-DAR based on Pearl's structural causal models and instantiate it in a comprehensive study of scientific paper assessment in the biomedical domain. We use the resulting dataset to investigate the human decision-making process in NL-DAR and determine the potential of LLMs to support structured decision-making over text. Our framework, open resources and tools lay the groundwork for the empirical study of collaborative diagnostic reasoning in the age of LLMs, in the scholarly domain and beyond.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
CARE: Collaborative AI-Assisted Reading Environment
Feb 24, 2023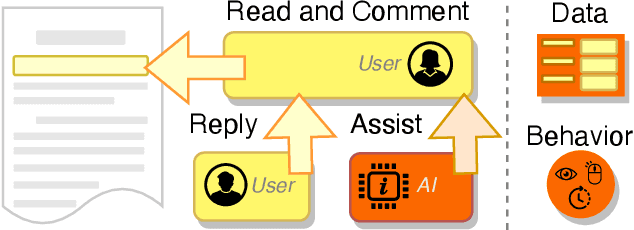

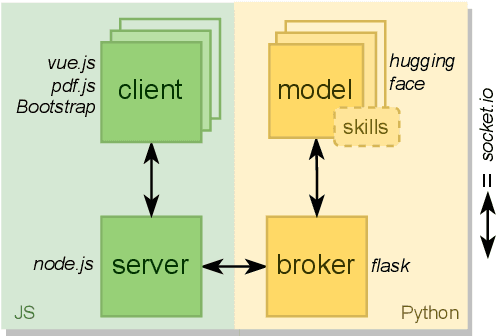
Recent years have seen impressive progress in AI-assisted writing, yet the developments in AI-assisted reading are lacking. We propose inline commentary as a natural vehicle for AI-based reading assistance, and present CARE: the first open integrated platform for the study of inline commentary and reading. CARE facilitates data collection for inline commentaries in a commonplace collaborative reading environment, and provides a framework for enhancing reading with NLP-based assistance, such as text classification, generation or question answering. The extensible behavioral logging allows unique insights into the reading and commenting behavior, and flexible configuration makes the platform easy to deploy in new scenarios. To evaluate CARE in action, we apply the platform in a user study dedicated to scholarly peer review. CARE facilitates the data collection and study of inline commentary in NLP, extrinsic evaluation of NLP assistance, and application prototyping. We invite the community to explore and build upon the open source implementation of CARE.
NLPeer: A Unified Resource for the Computational Study of Peer Review
Nov 12, 2022Peer review is a core component of scholarly publishing, yet it is time-consuming, requires considerable expertise, and is prone to error. The applications of NLP for peer reviewing assistance aim to mitigate those issues, but the lack of clearly licensed datasets and multi-domain corpora prevent the systematic study of NLP for peer review. To remedy this, we introduce NLPeer -- the first ethically sourced multidomain corpus of more than 5k papers and 11k review reports from five different venues. In addition to the new datasets of paper drafts, camera-ready versions and peer reviews from the NLP community, we establish a unified data representation, and augment previous peer review datasets to include parsed, structured paper representations, rich metadata and versioning information. Our work paves the path towards systematic, multi-faceted, evidence-based study of peer review in NLP and beyond. We make NLPeer publicly available.
Yes-Yes-Yes: Donation-based Peer Reviewing Data Collection for ACL Rolling Review and Beyond
Jan 27, 2022
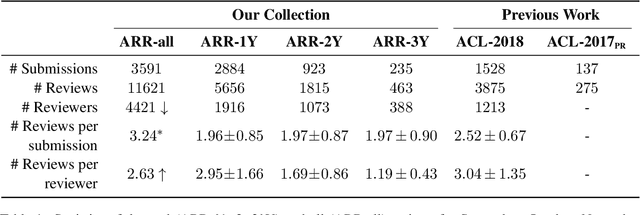
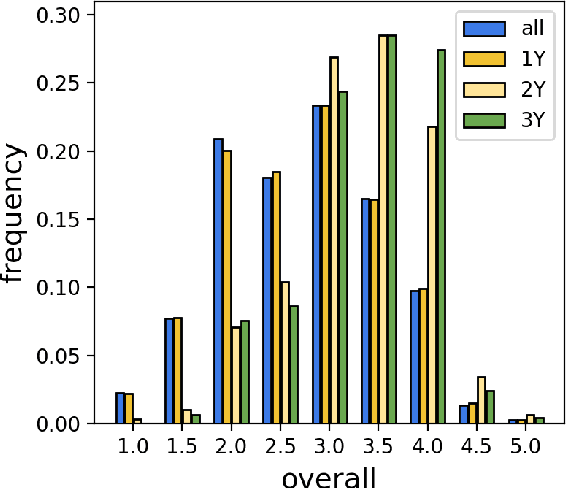
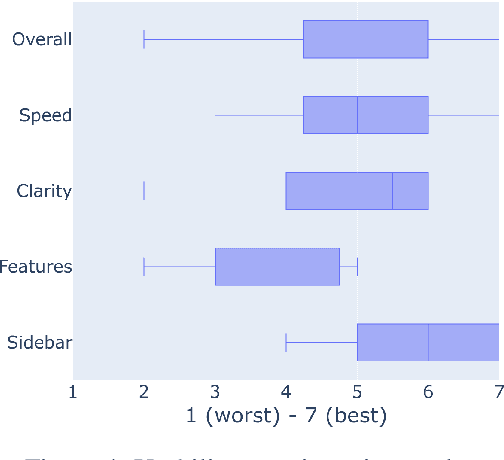
Peer review is the primary gatekeeper of scientific merit and quality, yet it is prone to bias and suffers from low efficiency. This demands cross-disciplinary scrutiny of the processes that underlie peer reviewing; however, quantitative research is limited by the data availability, as most of the peer reviewing data across research disciplines is never made public. Existing data collection efforts focus on few scientific domains and do not address a range of ethical, license- and confidentiality-related issues associated with peer reviewing data, preventing wide-scale research and application development. While recent methods for peer review analysis and processing show promise, a solid data foundation for computational research in peer review is still missing. To address this, we present an in-depth discussion of peer reviewing data, outline the ethical and legal desiderata for peer reviewing data collection, and propose the first continuous, donation-based data collection workflow that meets these requirements. We report on the ongoing implementation of this workflow at the ACL Rolling Review and deliver the first insights obtained with the newly collected data.
Ranking Scientific Papers Using Preference Learning
Sep 02, 2021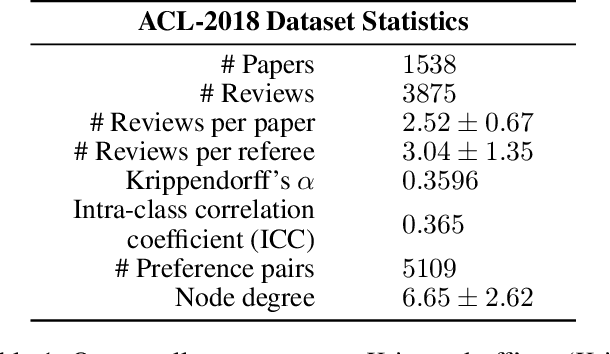
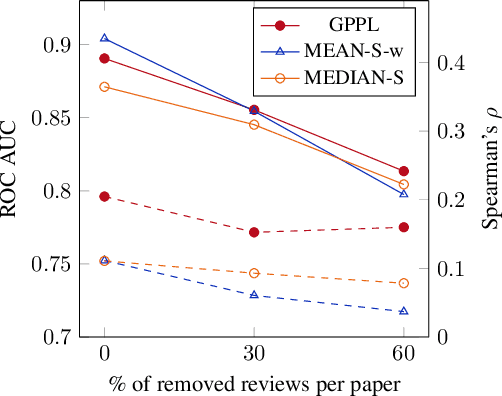
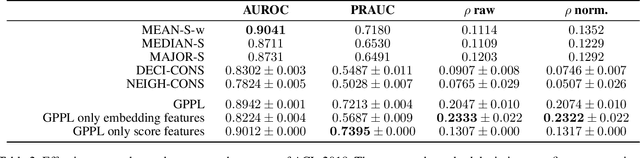
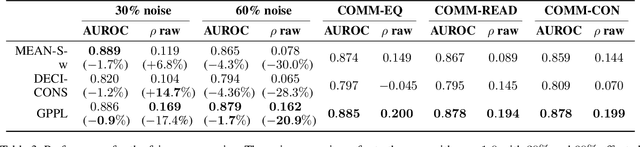
Peer review is the main quality control mechanism in academia. Quality of scientific work has many dimensions; coupled with the subjective nature of the reviewing task, this makes final decision making based on the reviews and scores therein very difficult and time-consuming. To assist with this important task, we cast it as a paper ranking problem based on peer review texts and reviewer scores. We introduce a novel, multi-faceted generic evaluation framework for making final decisions based on peer reviews that takes into account effectiveness, efficiency and fairness of the evaluated system. We propose a novel approach to paper ranking based on Gaussian Process Preference Learning (GPPL) and evaluate it on peer review data from the ACL-2018 conference. Our experiments demonstrate the superiority of our GPPL-based approach over prior work, while highlighting the importance of using both texts and review scores for paper ranking during peer review aggregation.