 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsefulness of LLMs as an Author Checklist Assistant for Scientific Papers: NeurIPS'24 Experiment
Nov 05, 2024
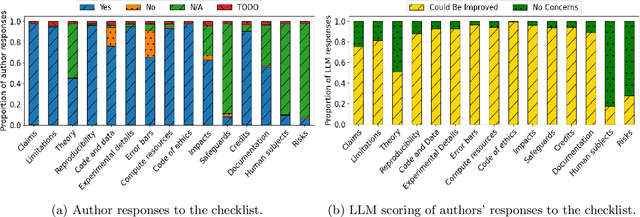
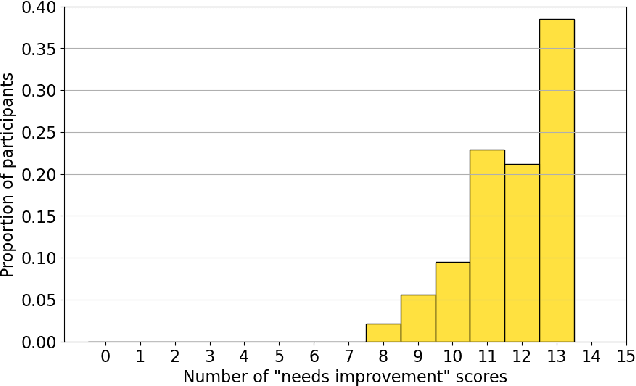

Large language models (LLMs) represent a promising, but controversial, tool in aiding scientific peer review. This study evaluates the usefulness of LLMs in a conference setting as a tool for vetting paper submissions against submission standards. We conduct an experiment at the 2024 Neural Information Processing Systems (NeurIPS) conference, where 234 papers were voluntarily submitted to an "LLM-based Checklist Assistant." This assistant validates whether papers adhere to the author checklist used by NeurIPS, which includes questions to ensure compliance with research and manuscript preparation standards. Evaluation of the assistant by NeurIPS paper authors suggests that the LLM-based assistant was generally helpful in verifying checklist completion. In post-usage surveys, over 70% of authors found the assistant useful, and 70% indicate that they would revise their papers or checklist responses based on its feedback. While causal attribution to the assistant is not definitive, qualitative evidence suggests that the LLM contributed to improving some submissions. Survey responses and analysis of re-submissions indicate that authors made substantive revisions to their submissions in response to specific feedback from the LLM. The experiment also highlights common issues with LLMs: inaccuracy (20/52) and excessive strictness (14/52) were the most frequent issues flagged by authors. We also conduct experiments to understand potential gaming of the system, which reveal that the assistant could be manipulated to enhance scores through fabricated justifications, highlighting potential vulnerabilities of automated review tools.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.