 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Meta-Album: Group-bias injection with style transfer to study robustness against distribution shifts
Dec 10, 2025We introduce Stylized Meta-Album (SMA), a new image classification meta-dataset comprising 24 datasets (12 content datasets, and 12 stylized datasets), designed to advance studies on out-of-distribution (OOD) generalization and related topics. Created using style transfer techniques from 12 subject classification datasets, SMA provides a diverse and extensive set of 4800 groups, combining various subjects (objects, plants, animals, human actions, textures) with multiple styles. SMA enables flexible control over groups and classes, allowing us to configure datasets to reflect diverse benchmark scenarios. While ideally, data collection would capture extensive group diversity, practical constraints often make this infeasible. SMA addresses this by enabling large and configurable group structures through flexible control over styles, subject classes, and domains-allowing datasets to reflect a wide range of real-world benchmark scenarios. This design not only expands group and class diversity, but also opens new methodological directions for evaluating model performance across diverse group and domain configurations-including scenarios with many minority groups, varying group imbalance, and complex domain shifts-and for studying fairness, robustness, and adaptation under a broader range of realistic conditions. To demonstrate SMA's effectiveness, we implemented two benchmarks: (1) a novel OOD generalization and group fairness benchmark leveraging SMA's domain, class, and group diversity to evaluate existing benchmarks. Our findings reveal that while simple balancing and algorithms utilizing group information remain competitive as claimed in previous benchmarks, increasing group diversity significantly impacts fairness, altering the superiority and relative rankings of algorithms. We also propose to use \textit{Top-M worst group accuracy} as a new hyperparameter tuning metric, demonstrating broader fairness during optimization and delivering better final worst-group accuracy for larger group diversity. (2) An unsupervised domain adaptation (UDA) benchmark utilizing SMA's group diversity to evaluate UDA algorithms across more scenarios, offering a more comprehensive benchmark with lower error bars (reduced by 73\% and 28\% in closed-set setting and UniDA setting, respectively) compared to existing efforts. These use cases highlight SMA's potential to significantly impact the outcomes of conventional benchmarks.
Usefulness of LLMs as an Author Checklist Assistant for Scientific Papers: NeurIPS'24 Experiment
Nov 05, 2024
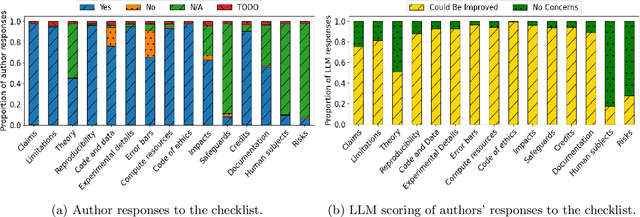
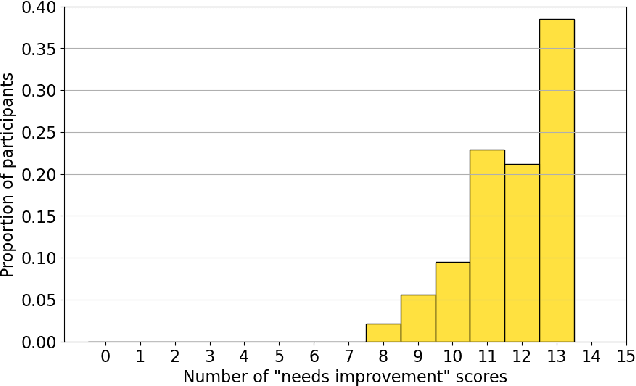

Large language models (LLMs) represent a promising, but controversial, tool in aiding scientific peer review. This study evaluates the usefulness of LLMs in a conference setting as a tool for vetting paper submissions against submission standards. We conduct an experiment at the 2024 Neural Information Processing Systems (NeurIPS) conference, where 234 papers were voluntarily submitted to an "LLM-based Checklist Assistant." This assistant validates whether papers adhere to the author checklist used by NeurIPS, which includes questions to ensure compliance with research and manuscript preparation standards. Evaluation of the assistant by NeurIPS paper authors suggests that the LLM-based assistant was generally helpful in verifying checklist completion. In post-usage surveys, over 70% of authors found the assistant useful, and 70% indicate that they would revise their papers or checklist responses based on its feedback. While causal attribution to the assistant is not definitive, qualitative evidence suggests that the LLM contributed to improving some submissions. Survey responses and analysis of re-submissions indicate that authors made substantive revisions to their submissions in response to specific feedback from the LLM. The experiment also highlights common issues with LLMs: inaccuracy (20/52) and excessive strictness (14/52) were the most frequent issues flagged by authors. We also conduct experiments to understand potential gaming of the system, which reveal that the assistant could be manipulated to enhance scores through fabricated justifications, highlighting potential vulnerabilities of automated review tools.
RelevAI-Reviewer: A Benchmark on AI Reviewers for Survey Paper Relevance
Jun 13, 2024



Recent advancements in Artificial Intelligence (AI), particularly the widespread adoption of Large Language Models (LLMs), have significantly enhanced text analysis capabilities. This technological evolution offers considerable promise for automating the review of scientific papers, a task traditionally managed through peer review by fellow researchers. Despite its critical role in maintaining research quality, the conventional peer-review process is often slow and subject to biases, potentially impeding the swift propagation of scientific knowledge. In this paper, we propose RelevAI-Reviewer, an automatic system that conceptualizes the task of survey paper review as a classification problem, aimed at assessing the relevance of a paper in relation to a specified prompt, analogous to a "call for papers". To address this, we introduce a novel dataset comprised of 25,164 instances. Each instance contains one prompt and four candidate papers, each varying in relevance to the prompt. The objective is to develop a machine learning (ML) model capable of determining the relevance of each paper and identifying the most pertinent one. We explore various baseline approaches, including traditional ML classifiers like Support Vector Machine (SVM) and advanced language models such as BERT. Preliminary findings indicate that the BERT-based end-to-end classifier surpasses other conventional ML methods in performance. We present this problem as a public challenge to foster engagement and interest in this area of research.
Auto-survey Challenge
Oct 10, 2023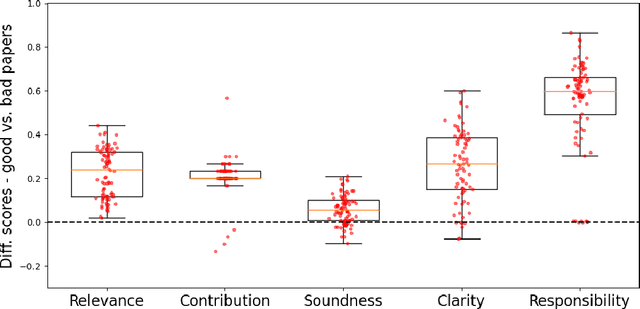

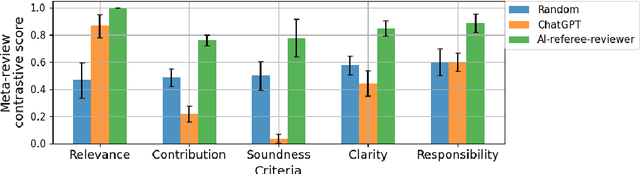
We present a novel platform for evaluating the capability of Large Language Models (LLMs) to autonomously compose and critique survey papers spanning a vast array of disciplines including sciences, humanities, education, and law. Within this framework, AI systems undertake a simulated peer-review mechanism akin to traditional scholarly journals, with human organizers serving in an editorial oversight capacity. Within this framework, we organized a competition for the AutoML conference 2023. Entrants are tasked with presenting stand-alone models adept at authoring articles from designated prompts and subsequently appraising them. Assessment criteria include clarity, reference appropriateness, accountability, and the substantive value of the content. This paper presents the design of the competition, including the implementation baseline submissions and methods of evaluation.