 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-survey Challenge
Paper and Code
Oct 10, 2023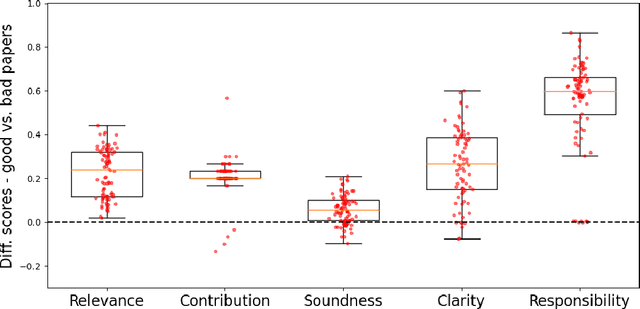

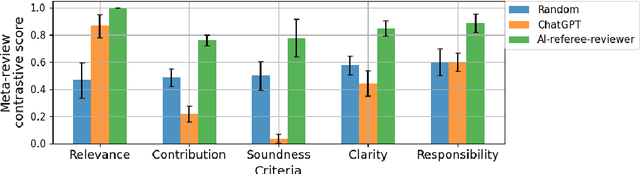
We present a novel platform for evaluating the capability of Large Language Models (LLMs) to autonomously compose and critique survey papers spanning a vast array of disciplines including sciences, humanities, education, and law. Within this framework, AI systems undertake a simulated peer-review mechanism akin to traditional scholarly journals, with human organizers serving in an editorial oversight capacity. Within this framework, we organized a competition for the AutoML conference 2023. Entrants are tasked with presenting stand-alone models adept at authoring articles from designated prompts and subsequently appraising them. Assessment criteria include clarity, reference appropriateness, accountability, and the substantive value of the content. This paper presents the design of the competition, including the implementation baseline submissions and methods of evaluation.