 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is a Better Matchmaker? Human vs. Algorithmic Judge Assignment in a High-Stakes Startup Competition
Oct 14, 2025



There is growing interest in applying artificial intelligence (AI) to automate and support complex decision-making tasks. However, it remains unclear how algorithms compare to human judgment in contexts requiring semantic understanding and domain expertise. We examine this in the context of the judge assignment problem, matching submissions to suitably qualified judges. Specifically, we tackled this problem at the Harvard President's Innovation Challenge, the university's premier venture competition awarding over \$500,000 to student and alumni startups. This represents a real-world environment where high-quality judge assignment is essential. We developed an AI-based judge-assignment algorithm, Hybrid Lexical-Semantic Similarity Ensemble (HLSE), and deployed it at the competition. We then evaluated its performance against human expert assignments using blinded match-quality scores from judges on $309$ judge-venture pairs. Using a Mann-Whitney U statistic based test, we found no statistically significant difference in assignment quality between the two approaches ($AUC=0.48, p=0.40$); on average, algorithmic matches are rated $3.90$ and manual matches $3.94$ on a 5-point scale, where 5 indicates an excellent match. Furthermore, manual assignments that previously required a full week could be automated in several hours by the algorithm during deployment. These results demonstrate that HLSE achieves human-expert-level matching quality while offering greater scalability and efficiency, underscoring the potential of AI-driven solutions to support and enhance human decision-making for judge assignment in high-stakes settings.
The More You Automate, the Less You See: Hidden Pitfalls of AI Scientist Systems
Sep 10, 2025AI scientist systems, capable of autonomously executing the full research workflow from hypothesis generation and experimentation to paper writing, hold significant potential for accelerating scientific discovery. However, the internal workflow of these systems have not been closely examined. This lack of scrutiny poses a risk of introducing flaws that could undermine the integrity, reliability, and trustworthiness of their research outputs. In this paper, we identify four potential failure modes in contemporary AI scientist systems: inappropriate benchmark selection, data leakage, metric misuse, and post-hoc selection bias. To examine these risks, we design controlled experiments that isolate each failure mode while addressing challenges unique to evaluating AI scientist systems. Our assessment of two prominent open-source AI scientist systems reveals the presence of several failures, across a spectrum of severity, which can be easily overlooked in practice. Finally, we demonstrate that access to trace logs and code from the full automated workflow enables far more effective detection of such failures than examining the final paper alone. We thus recommend journals and conferences evaluating AI-generated research to mandate submission of these artifacts alongside the paper to ensure transparency, accountability, and reproducibility.
Identity Theft in AI Conference Peer Review
Aug 06, 2025We discuss newly uncovered cases of identity theft in the scientific peer-review process within artificial intelligence (AI) research, with broader implications for other academic procedures. We detail how dishonest researchers exploit the peer-review system by creating fraudulent reviewer profiles to manipulate paper evaluations, leveraging weaknesses in reviewer recruitment workflows and identity verification processes. The findings highlight the critical need for stronger safeguards against identity theft in peer review and academia at large, and to this end, we also propose mitigating strategies.
Detecting LLM-Written Peer Reviews
Mar 20, 2025Editors of academic journals and program chairs of conferences require peer reviewers to write their own reviews. However, there is growing concern about the rise of lazy reviewing practices, where reviewers use large language models (LLMs) to generate reviews instead of writing them independently. Existing tools for detecting LLM-generated content are not designed to differentiate between fully LLM-generated reviews and those merely polished by an LLM. In this work, we employ a straightforward approach to identify LLM-generated reviews - doing an indirect prompt injection via the paper PDF to ask the LLM to embed a watermark. Our focus is on presenting watermarking schemes and statistical tests that maintain a bounded family-wise error rate, when a venue evaluates multiple reviews, with a higher power as compared to standard methods like Bonferroni correction. These guarantees hold without relying on any assumptions about human-written reviews. We also consider various methods for prompt injection including font embedding and jailbreaking. We evaluate the effectiveness and various tradeoffs of these methods, including different reviewer defenses. We find a high success rate in the embedding of our watermarks in LLM-generated reviews across models. We also find that our approach is resilient to common reviewer defenses, and that the bounds on error rates in our statistical tests hold in practice while having the power to flag LLM-generated reviews, while Bonferroni correction is infeasible.
Vulnerability of Text-Matching in ML/AI Conference Reviewer Assignments to Collusions
Dec 09, 2024



In the peer review process of top-tier machine learning (ML) and artificial intelligence (AI) conferences, reviewers are assigned to papers through automated methods. These assignment algorithms consider two main factors: (1) reviewers' expressed interests indicated by their bids for papers, and (2) reviewers' domain expertise inferred from the similarity between the text of their previously published papers and the submitted manuscripts. A significant challenge these conferences face is the existence of collusion rings, where groups of researchers manipulate the assignment process to review each other's papers, providing positive evaluations regardless of their actual quality. Most efforts to combat collusion rings have focused on preventing bid manipulation, under the assumption that the text similarity component is secure. In this paper, we demonstrate that even in the absence of bidding, colluding reviewers and authors can exploit the machine learning based text-matching component of reviewer assignment used at top ML/AI venues to get assigned their target paper. We also highlight specific vulnerabilities within this system and offer suggestions to enhance its robustness.
Usefulness of LLMs as an Author Checklist Assistant for Scientific Papers: NeurIPS'24 Experiment
Nov 05, 2024
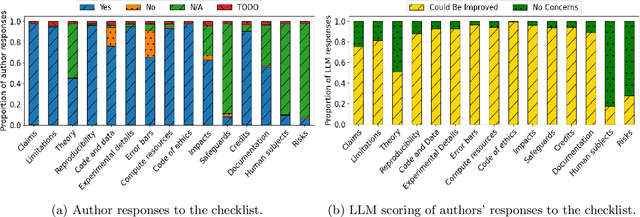
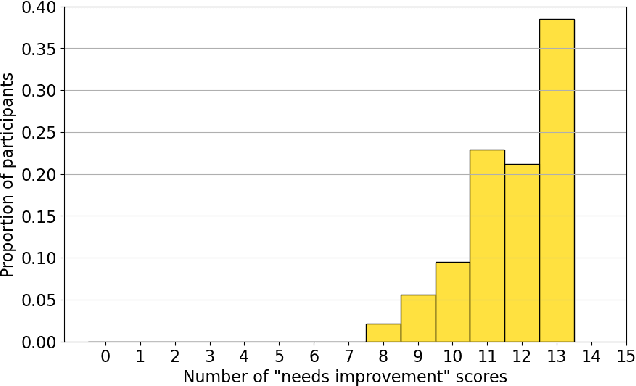

Large language models (LLMs) represent a promising, but controversial, tool in aiding scientific peer review. This study evaluates the usefulness of LLMs in a conference setting as a tool for vetting paper submissions against submission standards. We conduct an experiment at the 2024 Neural Information Processing Systems (NeurIPS) conference, where 234 papers were voluntarily submitted to an "LLM-based Checklist Assistant." This assistant validates whether papers adhere to the author checklist used by NeurIPS, which includes questions to ensure compliance with research and manuscript preparation standards. Evaluation of the assistant by NeurIPS paper authors suggests that the LLM-based assistant was generally helpful in verifying checklist completion. In post-usage surveys, over 70% of authors found the assistant useful, and 70% indicate that they would revise their papers or checklist responses based on its feedback. While causal attribution to the assistant is not definitive, qualitative evidence suggests that the LLM contributed to improving some submissions. Survey responses and analysis of re-submissions indicate that authors made substantive revisions to their submissions in response to specific feedback from the LLM. The experiment also highlights common issues with LLMs: inaccuracy (20/52) and excessive strictness (14/52) were the most frequent issues flagged by authors. We also conduct experiments to understand potential gaming of the system, which reveal that the assistant could be manipulated to enhance scores through fabricated justifications, highlighting potential vulnerabilities of automated review tools.
Enhancing Peer Review in Astronomy: A Machine Learning and Optimization Approach to Reviewer Assignments for ALMA
Oct 13, 2024The increasing volume of papers and proposals undergoing peer review emphasizes the pressing need for greater automation to effectively manage the growing scale. In this study, we present the deployment and evaluation of machine learning and optimization techniques for assigning proposals to reviewers that was developed for the Atacama Large Millimeter/submillimeter Array (ALMA) during the Cycle 10 Call for Proposals issued in 2023. By utilizing topic modeling algorithms, we identify the proposal topics and assess reviewers' expertise based on their historical ALMA proposal submissions. We then apply an adapted version of the assignment optimization algorithm from PeerReview4All (Stelmakh et al. 2021a) to maximize the alignment between proposal topics and reviewer expertise. Our evaluation shows a significant improvement in matching reviewer expertise: the median similarity score between the proposal topic and reviewer expertise increased by 51 percentage points compared to the previous cycle, and the percentage of reviewers reporting expertise in their assigned proposals rose by 20 percentage points. Furthermore, the assignment process proved highly effective in that no proposals required reassignment due to significant mismatches, resulting in a savings of 3 to 5 days of manual effort.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
On the Detection of Reviewer-Author Collusion Rings From Paper Bidding
Feb 12, 2024A major threat to the peer-review systems of computer science conferences is the existence of "collusion rings" between reviewers. In such collusion rings, reviewers who have also submitted their own papers to the conference work together to manipulate the conference's paper assignment, with the aim of being assigned to review each other's papers. The most straightforward way that colluding reviewers can manipulate the paper assignment is by indicating their interest in each other's papers through strategic paper bidding. One potential approach to solve this important problem would be to detect the colluding reviewers from their manipulated bids, after which the conference can take appropriate action. While prior work has has developed effective techniques to detect other kinds of fraud, no research has yet established that detecting collusion rings is even possible. In this work, we tackle the question of whether it is feasible to detect collusion rings from the paper bidding. To answer this question, we conduct empirical analysis of two realistic conference bidding datasets, including evaluations of existing algorithms for fraud detection in other applications. We find that collusion rings can achieve considerable success at manipulating the paper assignment while remaining hidden from detection: for example, in one dataset, undetected colluders are able to achieve assignment to up to 30% of the papers authored by other colluders. In addition, when 10 colluders bid on all of each other's papers, no detection algorithm outputs a group of reviewers with more than 31% overlap with the true colluders. These results suggest that collusion cannot be effectively detected from the bidding, demonstrating the need to develop more complex detection algorithms that leverage additional metadata.
ReviewerGPT? An Exploratory Study on Using Large Language Models for Paper Reviewing
Jun 01, 2023Given the rapid ascent of large language models (LLMs), we study the question: (How) can large language models help in reviewing of scientific papers or proposals? We first conduct some pilot studies where we find that (i) GPT-4 outperforms other LLMs (Bard, Vicuna, Koala, Alpaca, LLaMa, Dolly, OpenAssistant, StableLM), and (ii) prompting with a specific question (e.g., to identify errors) outperforms prompting to simply write a review. With these insights, we study the use of LLMs (specifically, GPT-4) for three tasks: 1. Identifying errors: We construct 13 short computer science papers each with a deliberately inserted error, and ask the LLM to check for the correctness of these papers. We observe that the LLM finds errors in 7 of them, spanning both mathematical and conceptual errors. 2. Verifying checklists: We task the LLM to verify 16 closed-ended checklist questions in the respective sections of 15 NeurIPS 2022 papers. We find that across 119 {checklist question, paper} pairs, the LLM had an 86.6% accuracy. 3. Choosing the "better" paper: We generate 10 pairs of abstracts, deliberately designing each pair in such a way that one abstract was clearly superior than the other. The LLM, however, struggled to discern these relatively straightforward distinctions accurately, committing errors in its evaluations for 6 out of the 10 pairs. Based on these experiments, we think that LLMs have a promising use as reviewing assistants for specific reviewing tasks, but not (yet) for complete evaluations of papers or proposals.