 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Peer Review Really in Decline? Analyzing Review Quality across Venues and Time
Jan 21, 2026Peer review is at the heart of modern science. As submission numbers rise and research communities grow, the decline in review quality is a popular narrative and a common concern. Yet, is it true? Review quality is difficult to measure, and the ongoing evolution of reviewing practices makes it hard to compare reviews across venues and time. To address this, we introduce a new framework for evidence-based comparative study of review quality and apply it to major AI and machine learning conferences: ICLR, NeurIPS and *ACL. We document the diversity of review formats and introduce a new approach to review standardization. We propose a multi-dimensional schema for quantifying review quality as utility to editors and authors, coupled with both LLM-based and lightweight measurements. We study the relationships between measurements of review quality, and its evolution over time. Contradicting the popular narrative, our cross-temporal analysis reveals no consistent decline in median review quality across venues and years. We propose alternative explanations, and outline recommendations to facilitate future empirical studies of review quality.
Exposía: Academic Writing Assessment of Exposés and Peer Feedback
Jan 10, 2026We present Exposía, the first public dataset that connects writing and feedback assessment in higher education, enabling research on educationally grounded approaches to academic writing evaluation. Exposía includes student research project proposals and peer and instructor feedback consisting of comments and free-text reviews. The dataset was collected in the "Introduction to Scientific Work" course of the Computer Science undergraduate program that focuses on teaching academic writing skills and providing peer feedback on academic writing. Exposía reflects the multi-stage nature of the academic writing process that includes drafting, providing and receiving feedback, and revising the writing based on the feedback received. Both the project proposals and peer feedback are accompanied by human assessment scores based on a fine-grained, pedagogically-grounded schema for writing and feedback assessment that we develop. We use Exposía to benchmark state-of-the-art open-source large language models (LLMs) for two tasks: automated scoring of (1) the proposals and (2) the student reviews. The strongest LLMs attain high agreement on scoring aspects that require little domain knowledge but degrade on dimensions evaluating content, in line with human agreement values. We find that LLMs align better with the human instructors giving high scores. Finally, we establish that a prompting strategy that scores multiple aspects of the writing together is the most effective, an important finding for classroom deployment.
Identifying Aspects in Peer Reviews
Apr 09, 2025



Peer review is central to academic publishing, but the growing volume of submissions is straining the process. This motivates the development of computational approaches to support peer review. While each review is tailored to a specific paper, reviewers often make assessments according to certain aspects such as Novelty, which reflect the values of the research community. This alignment creates opportunities for standardizing the reviewing process, improving quality control, and enabling computational support. While prior work has demonstrated the potential of aspect analysis for peer review assistance, the notion of aspect remains poorly formalized. Existing approaches often derive aspect sets from review forms and guidelines of major NLP venues, yet data-driven methods for aspect identification are largely underexplored. To address this gap, our work takes a bottom-up approach: we propose an operational definition of aspect and develop a data-driven schema for deriving fine-grained aspects from a corpus of peer reviews. We introduce a dataset of peer reviews augmented with aspects and show how it can be used for community-level review analysis. We further show how the choice of aspects can impact downstream applications, such as LLM-generated review detection. Our results lay a foundation for a principled and data-driven investigation of review aspects, and pave the path for new applications of NLP to support peer review.
Are Large Language Models Good Classifiers? A Study on Edit Intent Classification in Scientific Document Revisions
Oct 02, 2024
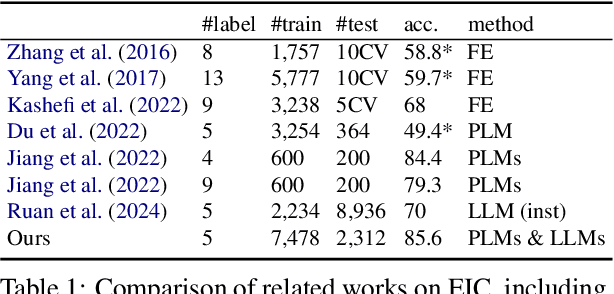


Classification is a core NLP task architecture with many potential applications. While large language models (LLMs) have brought substantial advancements in text generation, their potential for enhancing classification tasks remains underexplored. To address this gap, we propose a framework for thoroughly investigating fine-tuning LLMs for classification, including both generation- and encoding-based approaches. We instantiate this framework in edit intent classification (EIC), a challenging and underexplored classification task. Our extensive experiments and systematic comparisons with various training approaches and a representative selection of LLMs yield new insights into their application for EIC. We investigate the generalizability of these findings on five further classification tasks. To demonstrate the proposed methods and address the data shortage for empirical edit analysis, we use our best-performing EIC model to create Re3-Sci2.0, a new large-scale dataset of 1,780 scientific document revisions with over 94k labeled edits. The quality of the dataset is assessed through human evaluation. The new dataset enables an in-depth empirical study of human editing behavior in academic writing. We make our experimental framework, models and data publicly available.
Diagnostic Reasoning in Natural Language: Computational Model and Application
Sep 09, 2024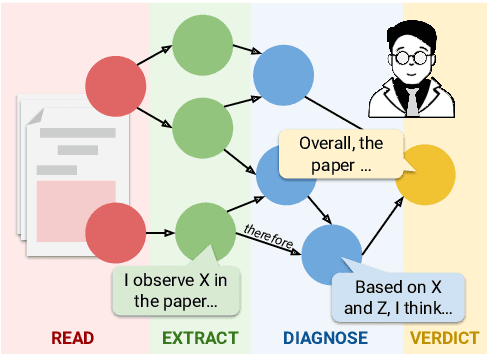
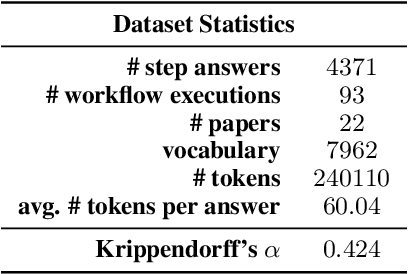
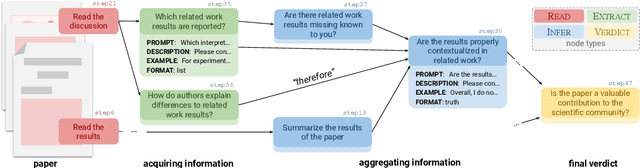

Diagnostic reasoning is a key component of expert work in many domains. It is a hard, time-consuming activity that requires expertise, and AI research has investigated the ways automated systems can support this process. Yet, due to the complexity of natural language, the applications of AI for diagnostic reasoning to language-related tasks are lacking. To close this gap, we investigate diagnostic abductive reasoning (DAR) in the context of language-grounded tasks (NL-DAR). We propose a novel modeling framework for NL-DAR based on Pearl's structural causal models and instantiate it in a comprehensive study of scientific paper assessment in the biomedical domain. We use the resulting dataset to investigate the human decision-making process in NL-DAR and determine the potential of LLMs to support structured decision-making over text. Our framework, open resources and tools lay the groundwork for the empirical study of collaborative diagnostic reasoning in the age of LLMs, in the scholarly domain and beyond.
Systematic Task Exploration with LLMs: A Study in Citation Text Generation
Jul 04, 2024
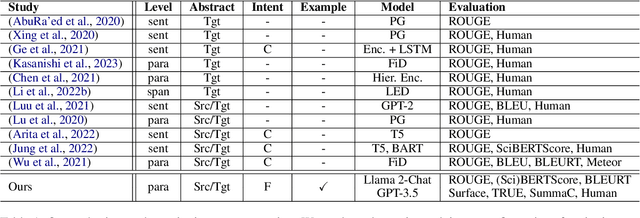


Large language models (LLMs) bring unprecedented flexibility in defining and executing complex, creative natural language generation (NLG) tasks. Yet, this flexibility brings new challenges, as it introduces new degrees of freedom in formulating the task inputs and instructions and in evaluating model performance. To facilitate the exploration of creative NLG tasks, we propose a three-component research framework that consists of systematic input manipulation, reference data, and output measurement. We use this framework to explore citation text generation -- a popular scholarly NLP task that lacks consensus on the task definition and evaluation metric and has not yet been tackled within the LLM paradigm. Our results highlight the importance of systematically investigating both task instruction and input configuration when prompting LLMs, and reveal non-trivial relationships between different evaluation metrics used for citation text generation. Additional human generation and human evaluation experiments provide new qualitative insights into the task to guide future research in citation text generation. We make our code and data publicly available.
M2QA: Multi-domain Multilingual Question Answering
Jul 01, 2024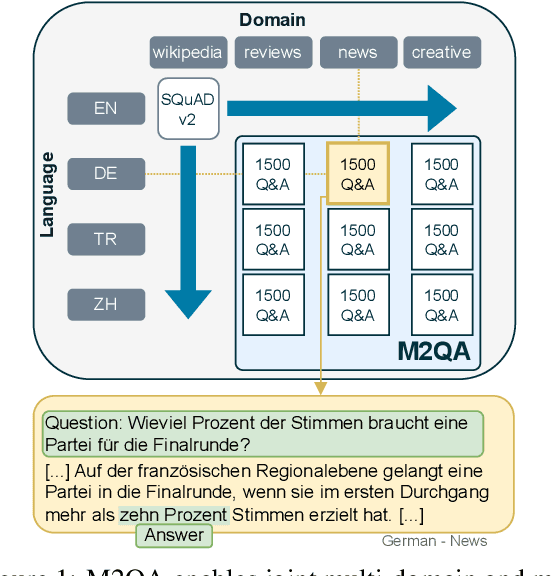

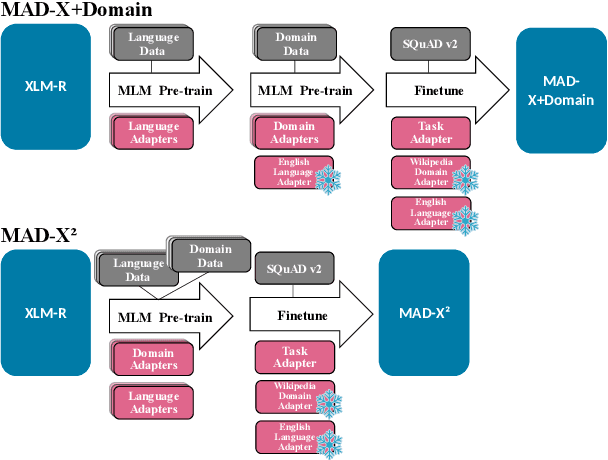

Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Re3: A Holistic Framework and Dataset for Modeling Collaborative Document Revision
May 31, 2024



Collaborative review and revision of textual documents is the core of knowledge work and a promising target for empirical analysis and NLP assistance. Yet, a holistic framework that would allow modeling complex relationships between document revisions, reviews and author responses is lacking. To address this gap, we introduce Re3, a framework for joint analysis of collaborative document revision. We instantiate this framework in the scholarly domain, and present Re3-Sci, a large corpus of aligned scientific paper revisions manually labeled according to their action and intent, and supplemented with the respective peer reviews and human-written edit summaries. We use the new data to provide first empirical insights into collaborative document revision in the academic domain, and to assess the capabilities of state-of-the-art LLMs at automating edit analysis and facilitating text-based collaboration. We make our annotation environment and protocols, the resulting data and experimental code publicly available.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
Document Structure in Long Document Transformers
Jan 31, 2024


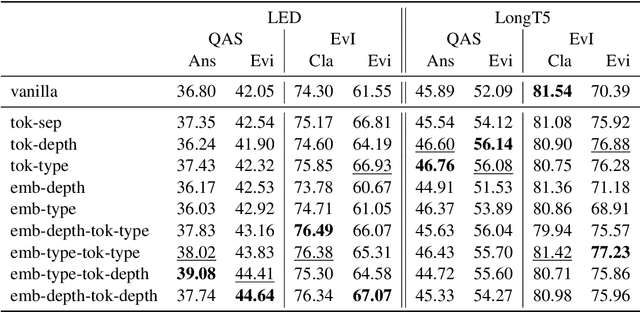
Long documents often exhibit structure with hierarchically organized elements of different functions, such as section headers and paragraphs. Despite the omnipresence of document structure, its role in natural language processing (NLP) remains opaque. Do long-document Transformer models acquire an internal representation of document structure during pre-training? How can structural information be communicated to a model after pre-training, and how does it influence downstream performance? To answer these questions, we develop a novel suite of probing tasks to assess structure-awareness of long-document Transformers, propose general-purpose structure infusion methods, and evaluate the effects of structure infusion on QASPER and Evidence Inference, two challenging long-document NLP tasks. Results on LED and LongT5 suggest that they acquire implicit understanding of document structure during pre-training, which can be further enhanced by structure infusion, leading to improved end-task performance. To foster research on the role of document structure in NLP modeling, we make our data and code publicly available.