 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposía: Academic Writing Assessment of Exposés and Peer Feedback
Jan 10, 2026We present Exposía, the first public dataset that connects writing and feedback assessment in higher education, enabling research on educationally grounded approaches to academic writing evaluation. Exposía includes student research project proposals and peer and instructor feedback consisting of comments and free-text reviews. The dataset was collected in the "Introduction to Scientific Work" course of the Computer Science undergraduate program that focuses on teaching academic writing skills and providing peer feedback on academic writing. Exposía reflects the multi-stage nature of the academic writing process that includes drafting, providing and receiving feedback, and revising the writing based on the feedback received. Both the project proposals and peer feedback are accompanied by human assessment scores based on a fine-grained, pedagogically-grounded schema for writing and feedback assessment that we develop. We use Exposía to benchmark state-of-the-art open-source large language models (LLMs) for two tasks: automated scoring of (1) the proposals and (2) the student reviews. The strongest LLMs attain high agreement on scoring aspects that require little domain knowledge but degrade on dimensions evaluating content, in line with human agreement values. We find that LLMs align better with the human instructors giving high scores. Finally, we establish that a prompting strategy that scores multiple aspects of the writing together is the most effective, an important finding for classroom deployment.
CARE: Collaborative AI-Assisted Reading Environment
Feb 24, 2023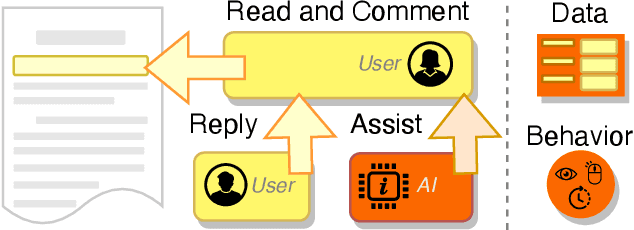

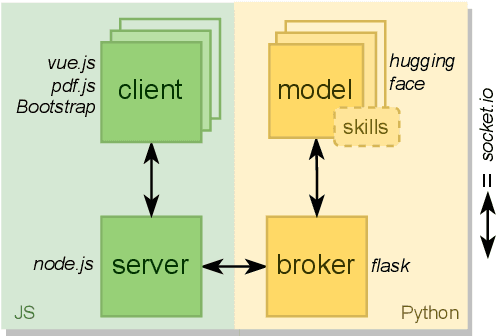
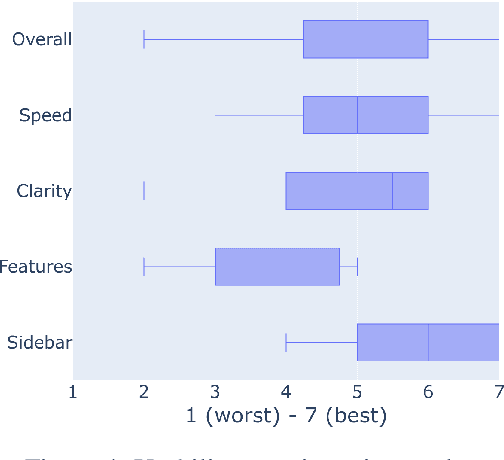
Recent years have seen impressive progress in AI-assisted writing, yet the developments in AI-assisted reading are lacking. We propose inline commentary as a natural vehicle for AI-based reading assistance, and present CARE: the first open integrated platform for the study of inline commentary and reading. CARE facilitates data collection for inline commentaries in a commonplace collaborative reading environment, and provides a framework for enhancing reading with NLP-based assistance, such as text classification, generation or question answering. The extensible behavioral logging allows unique insights into the reading and commenting behavior, and flexible configuration makes the platform easy to deploy in new scenarios. To evaluate CARE in action, we apply the platform in a user study dedicated to scholarly peer review. CARE facilitates the data collection and study of inline commentary in NLP, extrinsic evaluation of NLP assistance, and application prototyping. We invite the community to explore and build upon the open source implementation of CARE.