 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDT: Hierarchical Document Transformer
Jul 11, 2024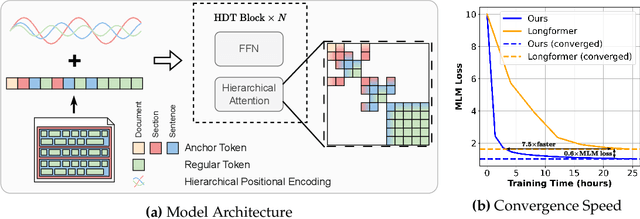

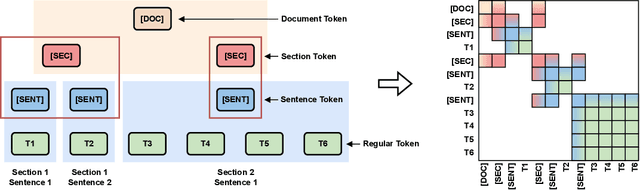

In this paper, we propose the Hierarchical Document Transformer (HDT), a novel sparse Transformer architecture tailored for structured hierarchical documents. Such documents are extremely important in numerous domains, including science, law or medicine. However, most existing solutions are inefficient and fail to make use of the structure inherent to documents. HDT exploits document structure by introducing auxiliary anchor tokens and redesigning the attention mechanism into a sparse multi-level hierarchy. This approach facilitates information exchange between tokens at different levels while maintaining sparsity, thereby enhancing computational and memory efficiency while exploiting the document structure as an inductive bias. We address the technical challenge of implementing HDT's sample-dependent hierarchical attention pattern by developing a novel sparse attention kernel that considers the hierarchical structure of documents. As demonstrated by our experiments, utilizing structural information present in documents leads to faster convergence, higher sample efficiency and better performance on downstream tasks.
Attribute or Abstain: Large Language Models as Long Document Assistants
Jul 10, 2024
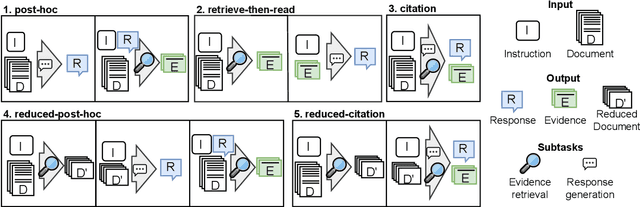
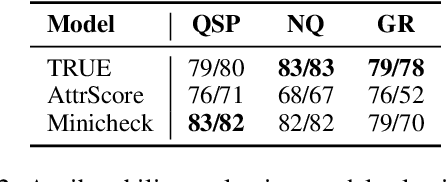
LLMs can help humans working with long documents, but are known to hallucinate. Attribution can increase trust in LLM responses: The LLM provides evidence that supports its response, which enhances verifiability. Existing approaches to attribution have only been evaluated in RAG settings, where the initial retrieval confounds LLM performance. This is crucially different from the long document setting, where retrieval is not needed, but could help. Thus, a long document specific evaluation of attribution is missing. To fill this gap, we present LAB, a benchmark of 6 diverse long document tasks with attribution, and experiment with different approaches to attribution on 4 LLMs of different sizes, both prompted and fine-tuned. We find that citation, i.e. response generation and evidence extraction in one step, mostly performs best. We investigate whether the ``Lost in the Middle'' phenomenon exists for attribution, but do not find this. We also find that evidence quality can predict response quality on datasets with simple responses, but not so for complex responses, as models struggle with providing evidence for complex claims. We release code and data for further investigation.
Document Structure in Long Document Transformers
Jan 31, 2024


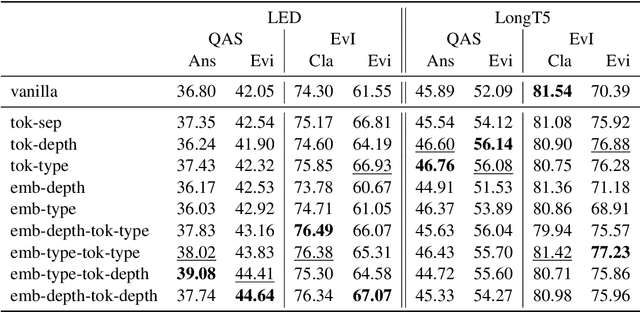
Long documents often exhibit structure with hierarchically organized elements of different functions, such as section headers and paragraphs. Despite the omnipresence of document structure, its role in natural language processing (NLP) remains opaque. Do long-document Transformer models acquire an internal representation of document structure during pre-training? How can structural information be communicated to a model after pre-training, and how does it influence downstream performance? To answer these questions, we develop a novel suite of probing tasks to assess structure-awareness of long-document Transformers, propose general-purpose structure infusion methods, and evaluate the effects of structure infusion on QASPER and Evidence Inference, two challenging long-document NLP tasks. Results on LED and LongT5 suggest that they acquire implicit understanding of document structure during pre-training, which can be further enhanced by structure infusion, leading to improved end-task performance. To foster research on the role of document structure in NLP modeling, we make our data and code publicly available.
CARE: Collaborative AI-Assisted Reading Environment
Feb 24, 2023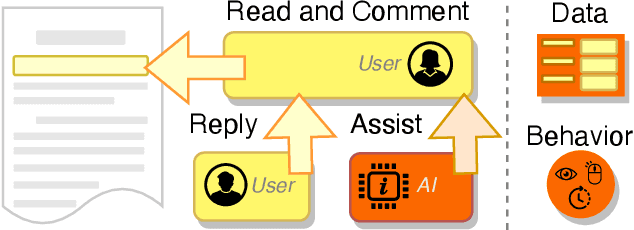

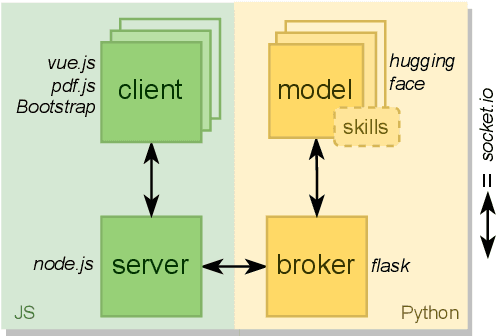
Recent years have seen impressive progress in AI-assisted writing, yet the developments in AI-assisted reading are lacking. We propose inline commentary as a natural vehicle for AI-based reading assistance, and present CARE: the first open integrated platform for the study of inline commentary and reading. CARE facilitates data collection for inline commentaries in a commonplace collaborative reading environment, and provides a framework for enhancing reading with NLP-based assistance, such as text classification, generation or question answering. The extensible behavioral logging allows unique insights into the reading and commenting behavior, and flexible configuration makes the platform easy to deploy in new scenarios. To evaluate CARE in action, we apply the platform in a user study dedicated to scholarly peer review. CARE facilitates the data collection and study of inline commentary in NLP, extrinsic evaluation of NLP assistance, and application prototyping. We invite the community to explore and build upon the open source implementation of CARE.
Revise and Resubmit: An Intertextual Model of Text-based Collaboration in Peer Review
Apr 22, 2022
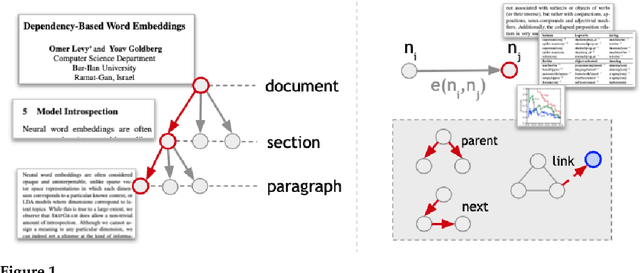

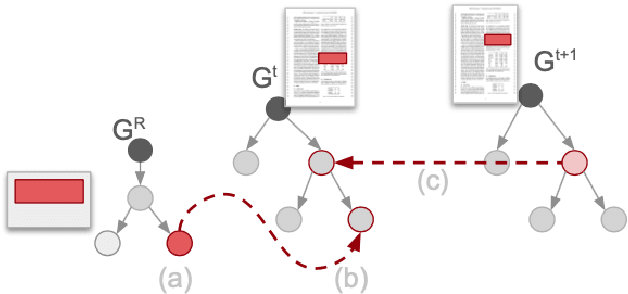
Peer review is a key component of the publishing process in most fields of science. The increasing submission rates put a strain on reviewing quality and efficiency, motivating the development of applications to support the reviewing and editorial work. While existing NLP studies focus on the analysis of individual texts, editorial assistance often requires modeling interactions between pairs of texts -- yet general frameworks and datasets to support this scenario are missing. Relationships between texts are the core object of the intertextuality theory -- a family of approaches in literary studies not yet operationalized in NLP. Inspired by prior theoretical work, we propose the first intertextual model of text-based collaboration, which encompasses three major phenomena that make up a full iteration of the review-revise-and-resubmit cycle: pragmatic tagging, linking and long-document version alignment. While peer review is used across the fields of science and publication formats, existing datasets solely focus on conference-style review in computer science. Addressing this, we instantiate our proposed model in the first annotated multi-domain corpus in journal-style post-publication open peer review, and provide detailed insights into the practical aspects of intertextual annotation. Our resource is a major step towards multi-domain, fine-grained applications of NLP in editorial support for peer review, and our intertextual framework paves the path for general-purpose modeling of text-based collaboration.