 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Structure in Long Document Transformers
Jan 31, 2024


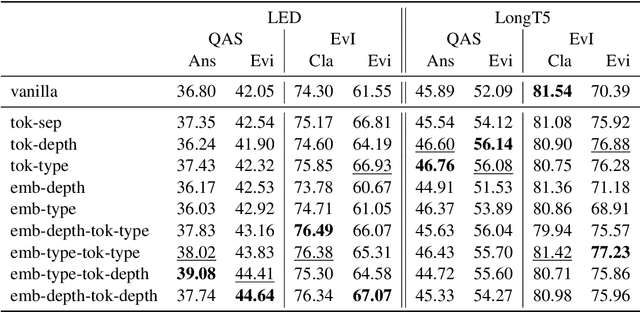
Long documents often exhibit structure with hierarchically organized elements of different functions, such as section headers and paragraphs. Despite the omnipresence of document structure, its role in natural language processing (NLP) remains opaque. Do long-document Transformer models acquire an internal representation of document structure during pre-training? How can structural information be communicated to a model after pre-training, and how does it influence downstream performance? To answer these questions, we develop a novel suite of probing tasks to assess structure-awareness of long-document Transformers, propose general-purpose structure infusion methods, and evaluate the effects of structure infusion on QASPER and Evidence Inference, two challenging long-document NLP tasks. Results on LED and LongT5 suggest that they acquire implicit understanding of document structure during pre-training, which can be further enhanced by structure infusion, leading to improved end-task performance. To foster research on the role of document structure in NLP modeling, we make our data and code publicly available.
ASET: Ad-hoc Structured Exploration of Text Collections
Mar 09, 2022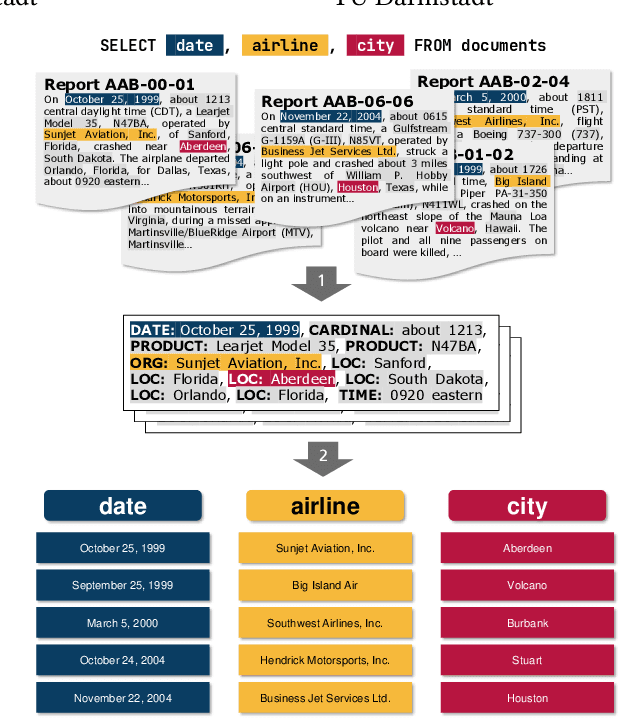
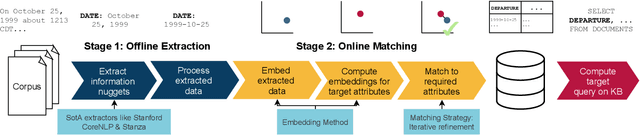

In this paper, we propose a new system called ASET that allows users to perform structured explorations of text collections in an ad-hoc manner. The main idea of ASET is to use a new two-phase approach that first extracts a superset of information nuggets from the texts using existing extractors such as named entity recognizers and then matches the extractions to a structured table definition as requested by the user based on embeddings. In our evaluation, we show that ASET is thus able to extract structured data from real-world text collections in high quality without the need to design extraction pipelines upfront.