 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating CAT: Synthesizing Data-Aware Conversational Agents for Transactional Databases
Mar 26, 2022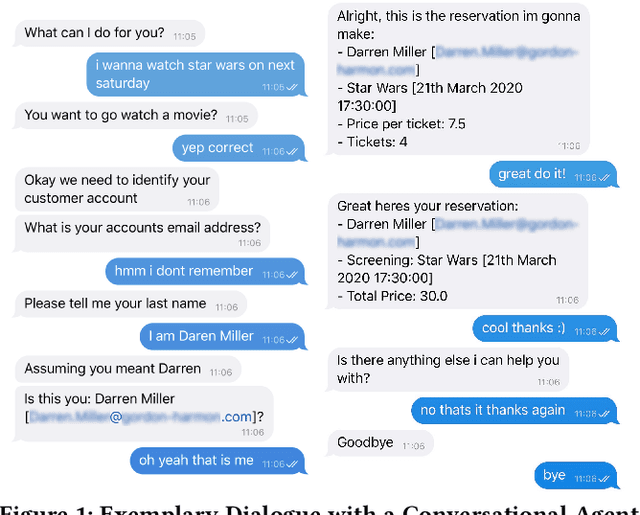

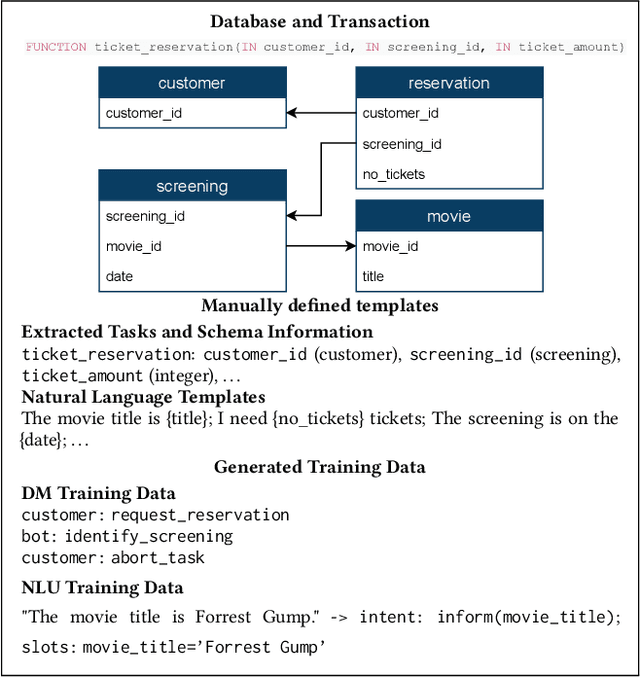

Databases for OLTP are often the backbone for applications such as hotel room or cinema ticket booking applications. However, developing a conversational agent (i.e., a chatbot-like interface) to allow end-users to interact with an application using natural language requires both immense amounts of training data and NLP expertise. This motivates CAT, which can be used to easily create conversational agents for transactional databases. The main idea is that, for a given OLTP database, CAT uses weak supervision to synthesize the required training data to train a state-of-the-art conversational agent, allowing users to interact with the OLTP database. Furthermore, CAT provides an out-of-the-box integration of the resulting agent with the database. As a major difference to existing conversational agents, agents synthesized by CAT are data-aware. This means that the agent decides which information should be requested from the user based on the current data distributions in the database, which typically results in markedly more efficient dialogues compared with non-data-aware agents. We publish the code for CAT as open source.
ASET: Ad-hoc Structured Exploration of Text Collections
Mar 09, 2022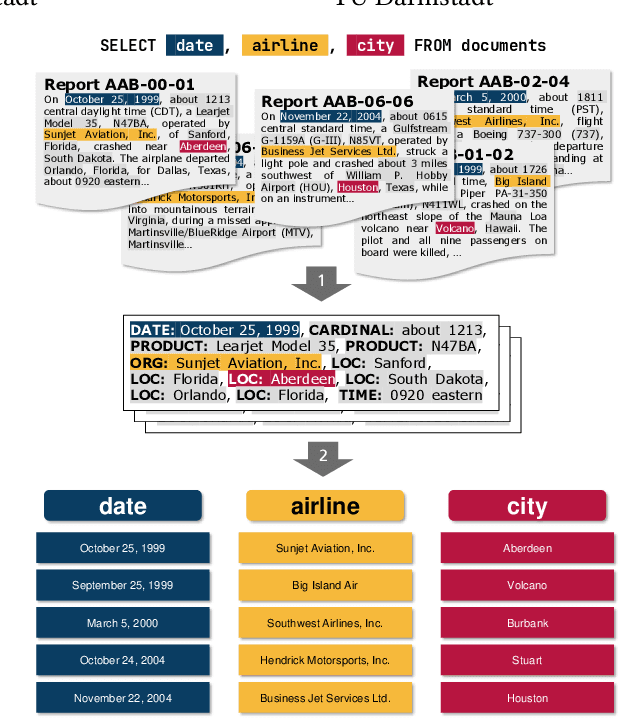
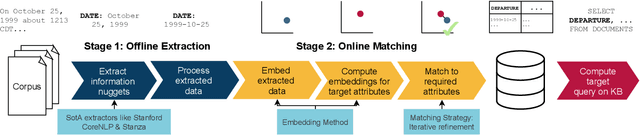
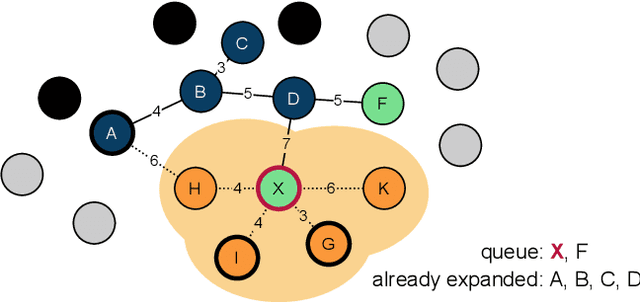

In this paper, we propose a new system called ASET that allows users to perform structured explorations of text collections in an ad-hoc manner. The main idea of ASET is to use a new two-phase approach that first extracts a superset of information nuggets from the texts using existing extractors such as named entity recognizers and then matches the extractions to a structured table definition as requested by the user based on embeddings. In our evaluation, we show that ASET is thus able to extract structured data from real-world text collections in high quality without the need to design extraction pipelines upfront.
It's AI Match: A Two-Step Approach for Schema Matching Using Embeddings
Mar 08, 2022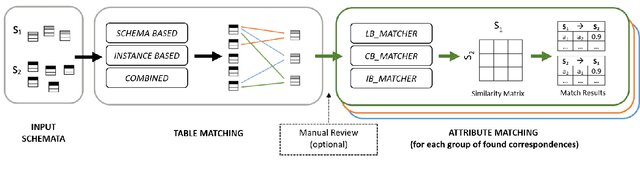
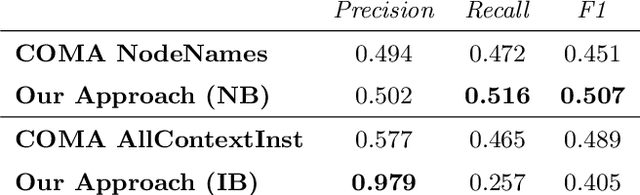
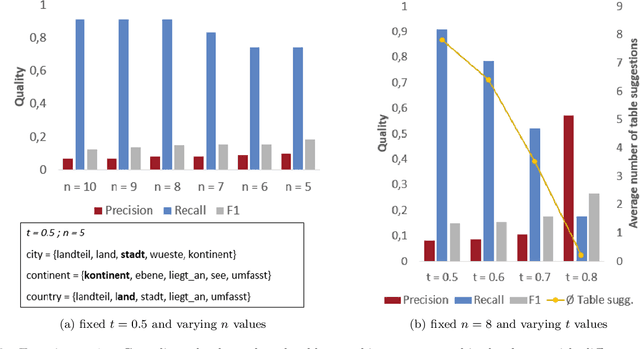
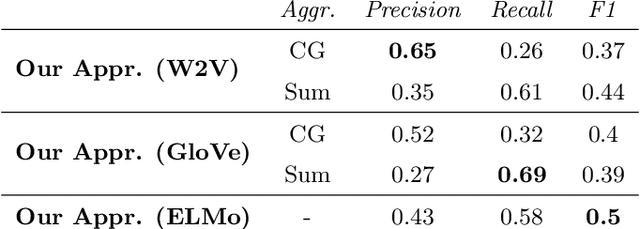
Since data is often stored in different sources, it needs to be integrated to gather a global view that is required in order to create value and derive knowledge from it. A critical step in data integration is schema matching which aims to find semantic correspondences between elements of two schemata. In order to reduce the manual effort involved in schema matching, many solutions for the automatic determination of schema correspondences have already been developed. In this paper, we propose a novel end-to-end approach for schema matching based on neural embeddings. The main idea is to use a two-step approach consisting of a table matching step followed by an attribute matching step. In both steps we use embeddings on different levels either representing the whole table or single attributes. Our results show that our approach is able to determine correspondences in a robust and reliable way and compared to traditional schema matching approaches can find non-trivial correspondences.
An End-to-end Neural Natural Language Interface for Databases
Apr 02, 2018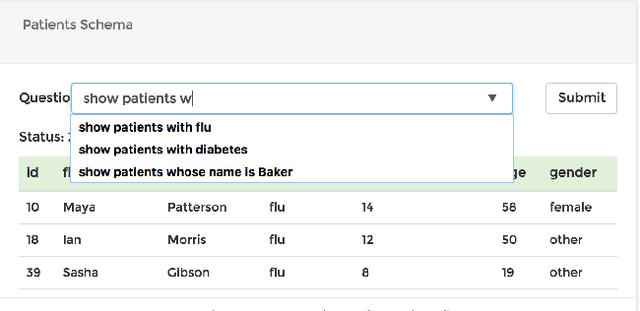

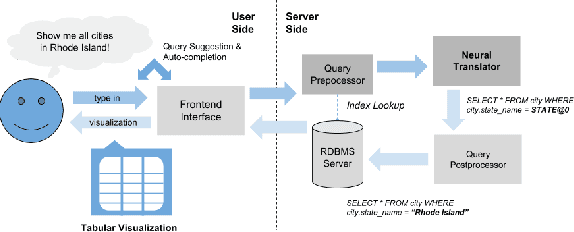
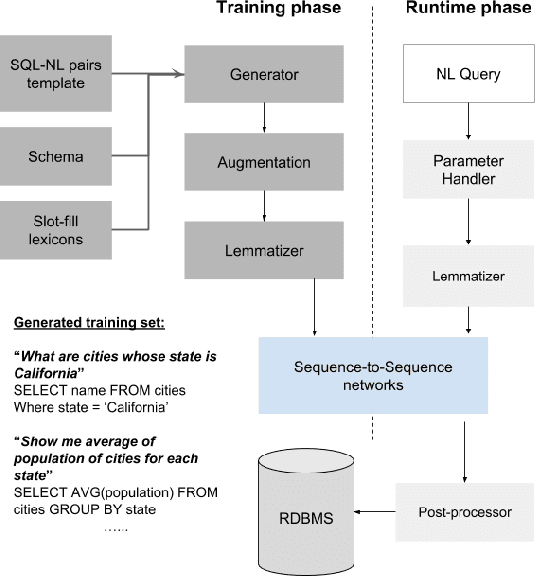
The ability to extract insights from new data sets is critical for decision making. Visual interactive tools play an important role in data exploration since they provide non-technical users with an effective way to visually compose queries and comprehend the results. Natural language has recently gained traction as an alternative query interface to databases with the potential to enable non-expert users to formulate complex questions and information needs efficiently and effectively. However, understanding natural language questions and translating them accurately to SQL is a challenging task, and thus Natural Language Interfaces for Databases (NLIDBs) have not yet made their way into practical tools and commercial products. In this paper, we present DBPal, a novel data exploration tool with a natural language interface. DBPal leverages recent advances in deep models to make query understanding more robust in the following ways: First, DBPal uses a deep model to translate natural language statements to SQL, making the translation process more robust to paraphrasing and other linguistic variations. Second, to support the users in phrasing questions without knowing the database schema and the query features, DBPal provides a learned auto-completion model that suggests partial query extensions to users during query formulation and thus helps to write complex queries.