 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexDBTagger: Explainable Natural Language Interface to Databases Using Keyword Mappings and Schema Graph
Oct 07, 2022



Translating natural language queries (NLQ) into structured query language (SQL) in interfaces to relational databases is a challenging task that has been widely studied by researchers from both the database and natural language processing communities. Numerous works have been proposed to attack the natural language interfaces to databases (NLIDB) problem either as a conventional pipeline-based or an end-to-end deep-learning-based solution. Nevertheless, regardless of the approach preferred, such solutions exhibit black-box nature, which makes it difficult for potential users targeted by these systems to comprehend the decisions made to produce the translated SQL. To this end, we propose xDBTagger, an explainable hybrid translation pipeline that explains the decisions made along the way to the user both textually and visually. We also evaluate xDBTagger quantitatively in three real-world relational databases. The evaluation results indicate that in addition to being fully interpretable, xDBTagger is effective in terms of accuracy and translates the queries more efficiently compared to other state-of-the-art pipeline-based systems up to 10000 times.
DBTagger: Multi-Task Learning for Keyword Mapping in NLIDBs Using Bi-Directional Recurrent Neural Networks
Jan 11, 2021



Translating Natural Language Queries (NLQs) to Structured Query Language (SQL) in interfaces deployed in relational databases is a challenging task, which has been widely studied in database community recently. Conventional rule based systems utilize series of solutions as a pipeline to deal with each step of this task, namely stop word filtering, tokenization, stemming/lemmatization, parsing, tagging, and translation. Recent works have mostly focused on the translation step overlooking the earlier steps by using ad-hoc solutions. In the pipeline, one of the most critical and challenging problems is keyword mapping; constructing a mapping between tokens in the query and relational database elements (tables, attributes, values, etc.). We define the keyword mapping problem as a sequence tagging problem, and propose a novel deep learning based supervised approach that utilizes POS tags of NLQs. Our proposed approach, called \textit{DBTagger} (DataBase Tagger), is an end-to-end and schema independent solution, which makes it practical for various relational databases. We evaluate our approach on eight different datasets, and report new state-of-the-art accuracy results, $92.4\%$ on the average. Our results also indicate that DBTagger is faster than its counterparts up to $10000$ times and scalable for bigger databases.
An End-to-end Neural Natural Language Interface for Databases
Apr 02, 2018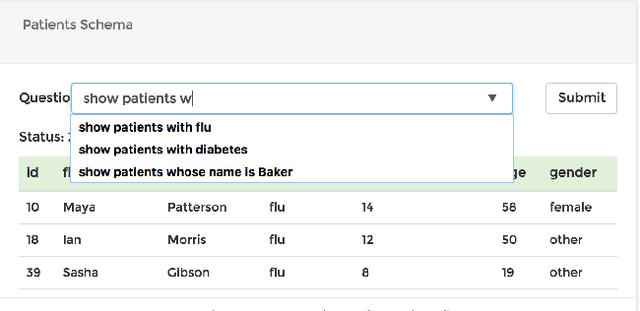

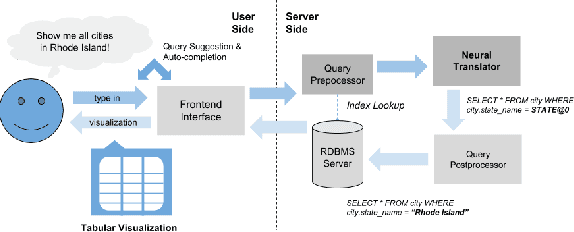
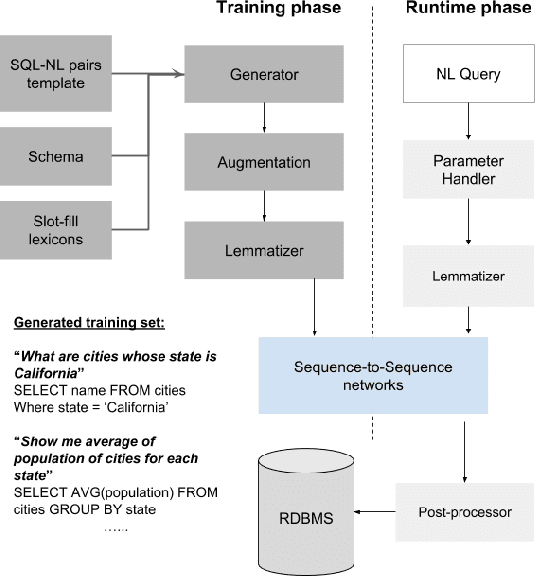
The ability to extract insights from new data sets is critical for decision making. Visual interactive tools play an important role in data exploration since they provide non-technical users with an effective way to visually compose queries and comprehend the results. Natural language has recently gained traction as an alternative query interface to databases with the potential to enable non-expert users to formulate complex questions and information needs efficiently and effectively. However, understanding natural language questions and translating them accurately to SQL is a challenging task, and thus Natural Language Interfaces for Databases (NLIDBs) have not yet made their way into practical tools and commercial products. In this paper, we present DBPal, a novel data exploration tool with a natural language interface. DBPal leverages recent advances in deep models to make query understanding more robust in the following ways: First, DBPal uses a deep model to translate natural language statements to SQL, making the translation process more robust to paraphrasing and other linguistic variations. Second, to support the users in phrasing questions without knowing the database schema and the query features, DBPal provides a learned auto-completion model that suggests partial query extensions to users during query formulation and thus helps to write complex queries.