 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardBench: A Benchmark for Learned Cardinality Estimation in Relational Databases
Aug 28, 2024Cardinality estimation is crucial for enabling high query performance in relational databases. Recently learned cardinality estimation models have been proposed to improve accuracy but there is no systematic benchmark or datasets which allows researchers to evaluate the progress made by new learned approaches and even systematically develop new learned approaches. In this paper, we are releasing a benchmark, containing thousands of queries over 20 distinct real-world databases for learned cardinality estimation. In contrast to other initial benchmarks, our benchmark is much more diverse and can be used for training and testing learned models systematically. Using this benchmark, we explored whether learned cardinality estimation can be transferred to an unseen dataset in a zero-shot manner. We trained GNN-based and transformer-based models to study the problem in three setups: 1-) instance-based, 2-) zero-shot, and 3-) fine-tuned. Our results show that while we get promising results for zero-shot cardinality estimation on simple single table queries; as soon as we add joins, the accuracy drops. However, we show that with fine-tuning, we can still utilize pre-trained models for cardinality estimation, significantly reducing training overheads compared to instance specific models. We are open sourcing our scripts to collect statistics, generate queries and training datasets to foster more extensive research, also from the ML community on the important problem of cardinality estimation and in particular improve on recent directions such as pre-trained cardinality estimation.
COSTREAM: Learned Cost Models for Operator Placement in Edge-Cloud Environments
Mar 13, 2024In this work, we present COSTREAM, a novel learned cost model for Distributed Stream Processing Systems that provides accurate predictions of the execution costs of a streaming query in an edge-cloud environment. The cost model can be used to find an initial placement of operators across heterogeneous hardware, which is particularly important in these environments. In our evaluation, we demonstrate that COSTREAM can produce highly accurate cost estimates for the initial operator placement and even generalize to unseen placements, queries, and hardware. When using COSTREAM to optimize the placements of streaming operators, a median speed-up of around 21x can be achieved compared to baselines.
SPARE: A Single-Pass Neural Model for Relational Databases
Oct 20, 2023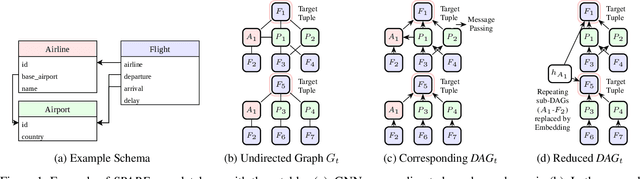
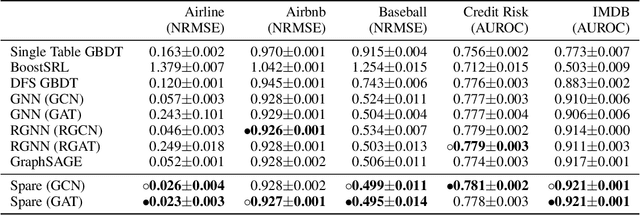

While there has been extensive work on deep neural networks for images and text, deep learning for relational databases (RDBs) is still a rather unexplored field. One direction that recently gained traction is to apply Graph Neural Networks (GNNs) to RBDs. However, training GNNs on large relational databases (i.e., data stored in multiple database tables) is rather inefficient due to multiple rounds of training and potentially large and inefficient representations. Hence, in this paper we propose SPARE (Single-Pass Relational models), a new class of neural models that can be trained efficiently on RDBs while providing similar accuracies as GNNs. For enabling efficient training, different from GNNs, SPARE makes use of the fact that data in RDBs has a regular structure, which allows one to train these models in a single pass while exploiting symmetries at the same time. Our extensive empirical evaluation demonstrates that SPARE can significantly speedup both training and inference while offering competitive predictive performance over numerous baselines.
Towards Foundation Models for Relational Databases [Vision Paper]
May 24, 2023Tabular representation learning has recently gained a lot of attention. However, existing approaches only learn a representation from a single table, and thus ignore the potential to learn from the full structure of relational databases, including neighboring tables that can contain important information for a contextualized representation. Moreover, current models are significantly limited in scale, which prevents that they learn from large databases. In this paper, we thus introduce our vision of relational representation learning, that can not only learn from the full relational structure, but also can scale to larger database sizes that are commonly found in real-world. Moreover, we also discuss opportunities and challenges we see along the way to enable this vision and present initial very promising results. Overall, we argue that this direction can lead to foundation models for relational databases that are today only available for text and images.
Towards Multi-Modal DBMSs for Seamless Querying of Texts and Tables
Apr 28, 2023In this paper, we propose Multi-Modal Databases (MMDBs), which is a new class of database systems that can seamlessly query text and tables using SQL. To enable seamless querying of textual data using SQL in an MMDB, we propose to extend relational databases with so-called multi-modal operators (MMOps) which are based on the advances of recent large language models such as GPT-3. The main idea of MMOps is that they allow text collections to be treated as tables without the need to manually transform the data. As we show in our evaluation, our MMDB prototype can not only outperform state-of-the-art approaches such as text-to-table in terms of accuracy and performance but it also requires significantly less training data to fine-tune the model for an unseen text collection.
DiffML: End-to-end Differentiable ML Pipelines
Jul 05, 2022



In this paper, we present our vision of differentiable ML pipelines called DiffML to automate the construction of ML pipelines in an end-to-end fashion. The idea is that DiffML allows to jointly train not just the ML model itself but also the entire pipeline including data preprocessing steps, e.g., data cleaning, feature selection, etc. Our core idea is to formulate all pipeline steps in a differentiable way such that the entire pipeline can be trained using backpropagation. However, this is a non-trivial problem and opens up many new research questions. To show the feasibility of this direction, we demonstrate initial ideas and a general principle of how typical preprocessing steps such as data cleaning, feature selection and dataset selection can be formulated as differentiable programs and jointly learned with the ML model. Moreover, we discuss a research roadmap and core challenges that have to be systematically tackled to enable fully differentiable ML pipelines.
Demonstrating CAT: Synthesizing Data-Aware Conversational Agents for Transactional Databases
Mar 26, 2022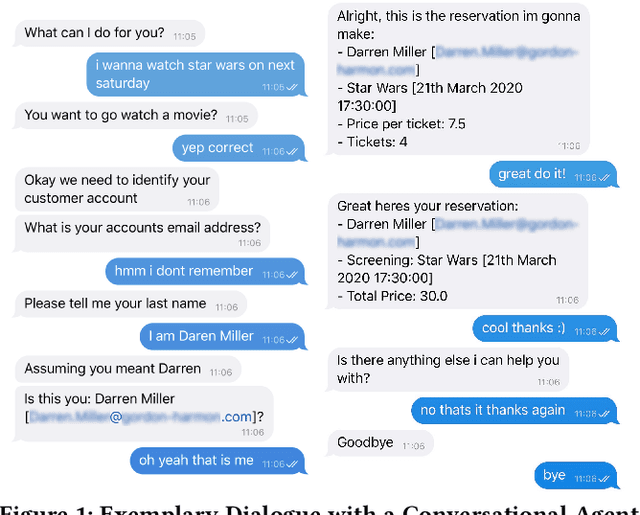

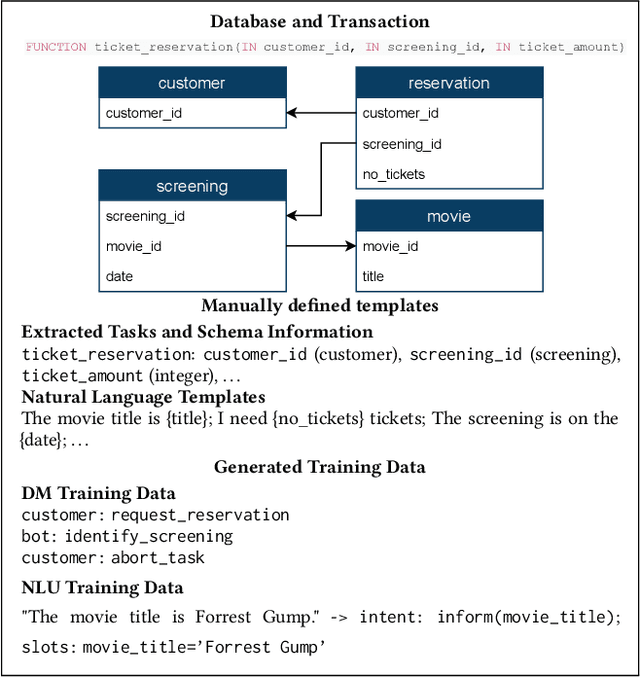

Databases for OLTP are often the backbone for applications such as hotel room or cinema ticket booking applications. However, developing a conversational agent (i.e., a chatbot-like interface) to allow end-users to interact with an application using natural language requires both immense amounts of training data and NLP expertise. This motivates CAT, which can be used to easily create conversational agents for transactional databases. The main idea is that, for a given OLTP database, CAT uses weak supervision to synthesize the required training data to train a state-of-the-art conversational agent, allowing users to interact with the OLTP database. Furthermore, CAT provides an out-of-the-box integration of the resulting agent with the database. As a major difference to existing conversational agents, agents synthesized by CAT are data-aware. This means that the agent decides which information should be requested from the user based on the current data distributions in the database, which typically results in markedly more efficient dialogues compared with non-data-aware agents. We publish the code for CAT as open source.
ASET: Ad-hoc Structured Exploration of Text Collections
Mar 09, 2022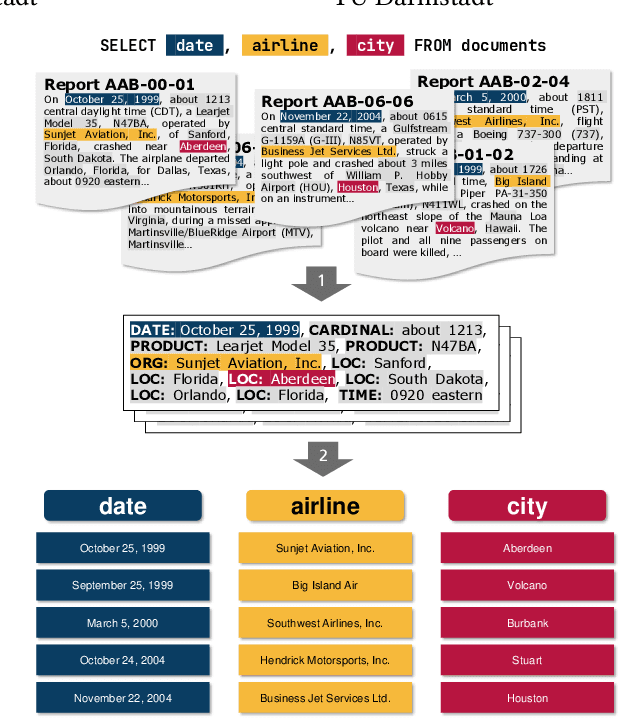
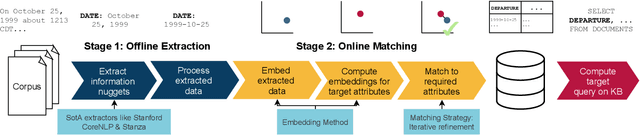

In this paper, we propose a new system called ASET that allows users to perform structured explorations of text collections in an ad-hoc manner. The main idea of ASET is to use a new two-phase approach that first extracts a superset of information nuggets from the texts using existing extractors such as named entity recognizers and then matches the extractions to a structured table definition as requested by the user based on embeddings. In our evaluation, we show that ASET is thus able to extract structured data from real-world text collections in high quality without the need to design extraction pipelines upfront.
It's AI Match: A Two-Step Approach for Schema Matching Using Embeddings
Mar 08, 2022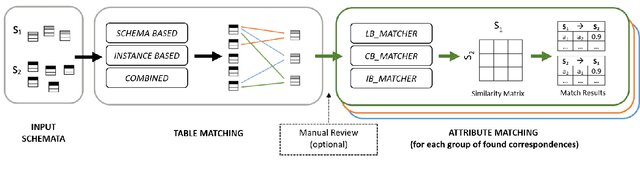
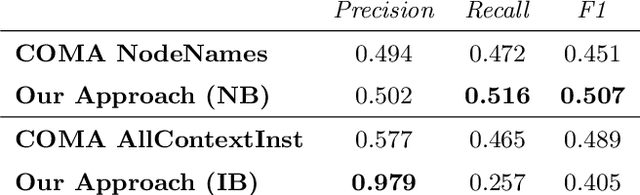
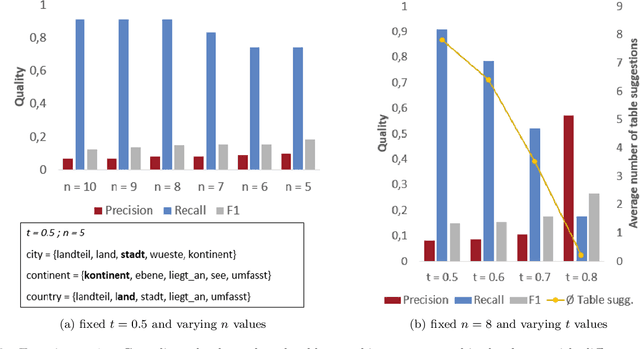
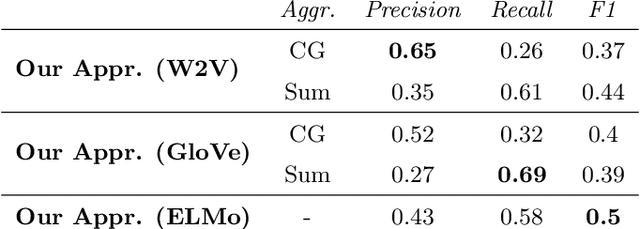
Since data is often stored in different sources, it needs to be integrated to gather a global view that is required in order to create value and derive knowledge from it. A critical step in data integration is schema matching which aims to find semantic correspondences between elements of two schemata. In order to reduce the manual effort involved in schema matching, many solutions for the automatic determination of schema correspondences have already been developed. In this paper, we propose a novel end-to-end approach for schema matching based on neural embeddings. The main idea is to use a two-step approach consisting of a table matching step followed by an attribute matching step. In both steps we use embeddings on different levels either representing the whole table or single attributes. Our results show that our approach is able to determine correspondences in a robust and reliable way and compared to traditional schema matching approaches can find non-trivial correspondences.
Zero-Shot Cost Models for Out-of-the-box Learned Cost Prediction
Jan 03, 2022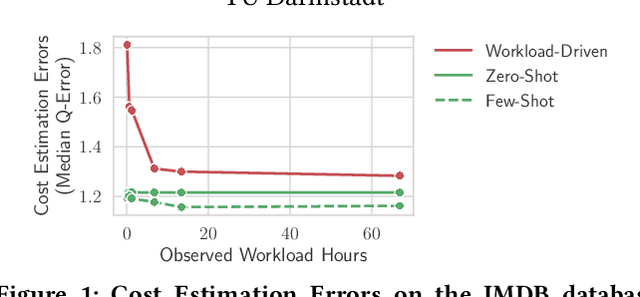

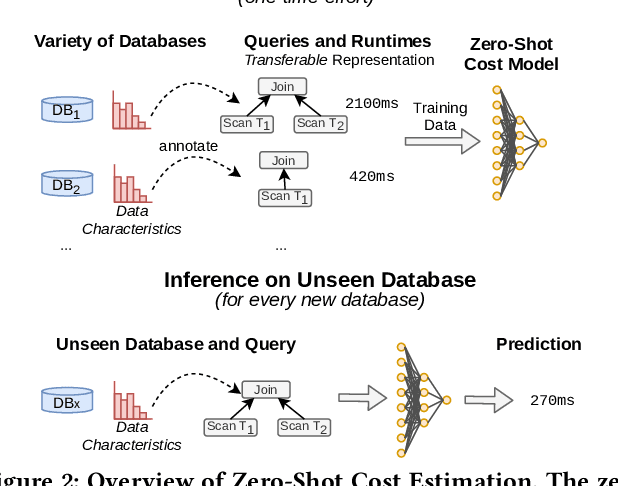

In this paper, we introduce zero-shot cost models which enable learned cost estimation that generalizes to unseen databases. In contrast to state-of-the-art workload-driven approaches which require to execute a large set of training queries on every new database, zero-shot cost models thus allow to instantiate a learned cost model out-of-the-box without expensive training data collection. To enable such zero-shot cost models, we suggest a new learning paradigm based on pre-trained cost models. As core contributions to support the transfer of such a pre-trained cost model to unseen databases, we introduce a new model architecture and representation technique for encoding query workloads as input to those models. As we will show in our evaluation, zero-shot cost estimation can provide more accurate cost estimates than state-of-the-art models for a wide range of (real-world) databases without requiring any query executions on unseen databases. Furthermore, we show that zero-shot cost models can be used in a few-shot mode that further improves their quality by retraining them just with a small number of additional training queries on the unseen database.