 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloating or Suggesting Ideas? A Large-Scale Contrastive Analysis of Metaphorical and Literal Verb-Object Constructions
Apr 09, 2026Metaphor pervades everyday language, allowing speakers to express abstract concepts via concrete domains. While prior work has studied metaphors cognitively and psycholinguistically, large-scale comparisons with literal language remain limited, especially for near-synonymous expressions. We analyze 297 English verb-object pairs (e.g., float idea vs. suggest idea) in ~2M corpus sentences, examining their contextual usage. Using five NLP tools, we extract 2,293 cognitive and linguistic features capturing affective, lexical, syntactic, and discourse-level properties. We address: (i) whether features differ between metaphorical and literal contexts (cross-pair analysis), and (ii) whether individual VO pairs diverge internally (within-pair analysis). Cross-pair results show literal contexts have higher lexical frequency, cohesion, and structural regularity, while metaphorical contexts show greater affective load, imageability, lexical diversity, and constructional specificity. Within-pair analyses reveal substantial heterogeneity, with most pairs showing non-uniform effects. These results suggest no single, consistent distributional pattern that distinguishes metaphorical from literal usage. Instead, differences are largely construction-specific. Overall, large-scale data combined with diverse features provides a fine-grained understanding of metaphor-literal contrasts in VO usage.
Explainable Semantic Textual Similarity via Dissimilar Span Detection
Mar 22, 2026Semantic Textual Similarity (STS) is a crucial component of many Natural Language Processing (NLP) applications. However, existing approaches typically reduce semantic nuances to a single score, limiting interpretability. To address this, we introduce the task of Dissimilar Span Detection (DSD), which aims to identify semantically differing spans between pairs of texts. This can help users understand which particular words or tokens negatively affect the similarity score, or be used to improve performance in STS-dependent downstream tasks. Furthermore, we release a new dataset suitable for the task, the Span Similarity Dataset (SSD), developed through a semi-automated pipeline combining large language models (LLMs) with human verification. We propose and evaluate different baseline methods for DSD, both unsupervised, based on LIME, SHAP, LLMs, and our own method, as well as an additional supervised approach. While LLMs and supervised models achieve the highest performance, overall results remain low, highlighting the complexity of the task. Finally, we set up an additional experiment that shows how DSD can lead to increased performance in the specific task of paraphrase detection.
FactNet: A Billion-Scale Knowledge Graph for Multilingual Factual Grounding
Feb 03, 2026While LLMs exhibit remarkable fluency, their utility is often compromised by factual hallucinations and a lack of traceable provenance. Existing resources for grounding mitigate this but typically enforce a dichotomy: they offer either structured knowledge without textual context (e.g., knowledge bases) or grounded text with limited scale and linguistic coverage. To bridge this gap, we introduce FactNet, a massive, open-source resource designed to unify 1.7 billion atomic assertions with 3.01 billion auditable evidence pointers derived exclusively from 316 Wikipedia editions. Unlike recent synthetic approaches, FactNet employs a strictly deterministic construction pipeline, ensuring that every evidence unit is recoverable with byte-level precision. Extensive auditing confirms a high grounding precision of 92.1%, even in long-tail languages. Furthermore, we establish FactNet-Bench, a comprehensive evaluation suite for Knowledge Graph Completion, Question Answering, and Fact Checking. FactNet provides the community with a foundational, reproducible resource for training and evaluating trustworthy, verifiable multilingual systems.
Mask and You Shall Receive: Optimizing Masked Language Modeling For Pretraining BabyLMs
Oct 23, 2025We describe our strategy for the 2025 edition of the BabyLM Challenge. Our main contribution is that of an improved form of Masked Language Modeling (MLM), which adapts the probabilities of the tokens masked according to the model's ability to predict them. The results show a substantial increase in performance on (Super)GLUE tasks over the standard MLM. We also incorporate sub-token embeddings, finding that this increases the model's morphological generalization capabilities. Our submission beats the baseline in the strict-small track.
EmoBench-UA: A Benchmark Dataset for Emotion Detection in Ukrainian
May 29, 2025While Ukrainian NLP has seen progress in many texts processing tasks, emotion classification remains an underexplored area with no publicly available benchmark to date. In this work, we introduce EmoBench-UA, the first annotated dataset for emotion detection in Ukrainian texts. Our annotation schema is adapted from the previous English-centric works on emotion detection (Mohammad et al., 2018; Mohammad, 2022) guidelines. The dataset was created through crowdsourcing using the Toloka.ai platform ensuring high-quality of the annotation process. Then, we evaluate a range of approaches on the collected dataset, starting from linguistic-based baselines, synthetic data translated from English, to large language models (LLMs). Our findings highlight the challenges of emotion classification in non-mainstream languages like Ukrainian and emphasize the need for further development of Ukrainian-specific models and training resources.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
EXECUTE: A Multilingual Benchmark for LLM Token Understanding
May 23, 2025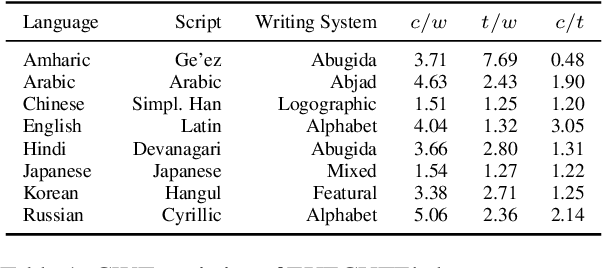
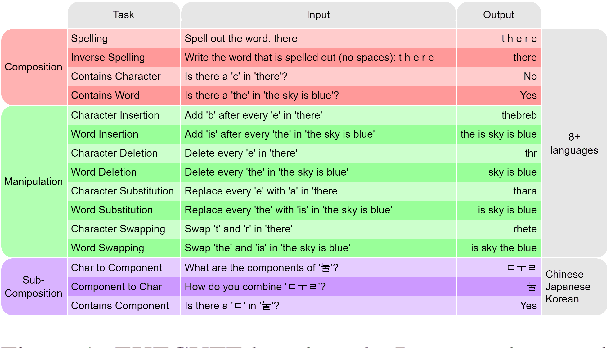
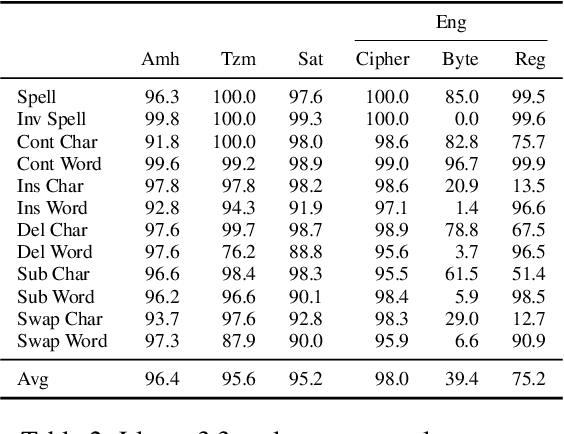
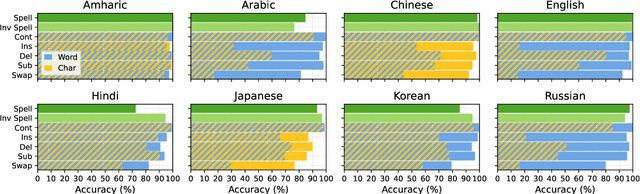
The CUTE benchmark showed that LLMs struggle with character understanding in English. We extend it to more languages with diverse scripts and writing systems, introducing EXECUTE. Our simplified framework allows easy expansion to any language. Tests across multiple LLMs reveal that challenges in other languages are not always on the character level as in English. Some languages show word-level processing issues, some show no issues at all. We also examine sub-character tasks in Chinese, Japanese, and Korean to assess LLMs' understanding of character components.
Data-Efficient Hate Speech Detection via Cross-Lingual Nearest Neighbor Retrieval with Limited Labeled Data
May 20, 2025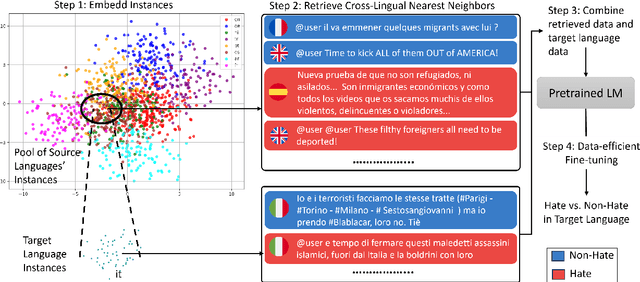
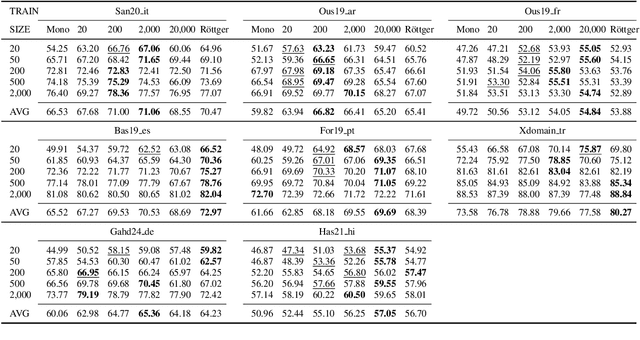
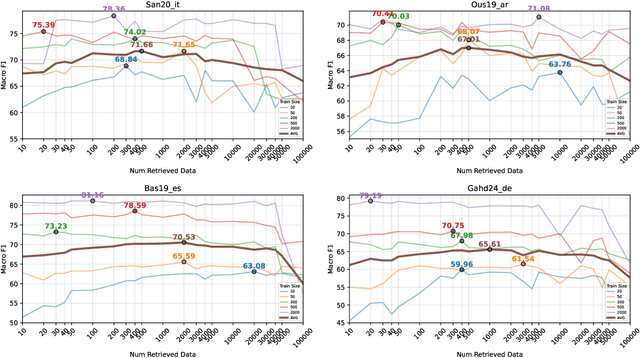
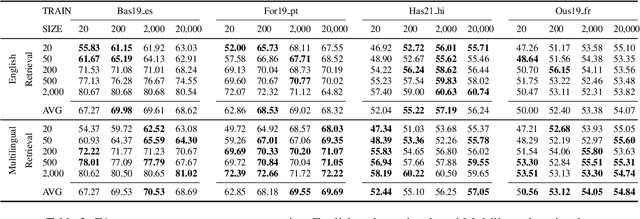
Considering the importance of detecting hateful language, labeled hate speech data is expensive and time-consuming to collect, particularly for low-resource languages. Prior work has demonstrated the effectiveness of cross-lingual transfer learning and data augmentation in improving performance on tasks with limited labeled data. To develop an efficient and scalable cross-lingual transfer learning approach, we leverage nearest-neighbor retrieval to augment minimal labeled data in the target language, thereby enhancing detection performance. Specifically, we assume access to a small set of labeled training instances in the target language and use these to retrieve the most relevant labeled examples from a large multilingual hate speech detection pool. We evaluate our approach on eight languages and demonstrate that it consistently outperforms models trained solely on the target language data. Furthermore, in most cases, our method surpasses the current state-of-the-art. Notably, our approach is highly data-efficient, retrieving as small as 200 instances in some cases while maintaining superior performance. Moreover, it is scalable, as the retrieval pool can be easily expanded, and the method can be readily adapted to new languages and tasks. We also apply maximum marginal relevance to mitigate redundancy and filter out highly similar retrieved instances, resulting in improvements in some languages.
From Unaligned to Aligned: Scaling Multilingual LLMs with Multi-Way Parallel Corpora
May 20, 2025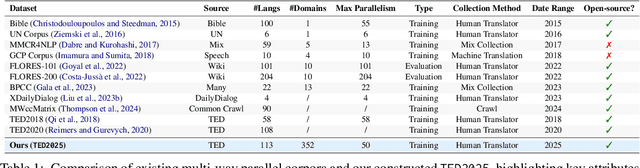

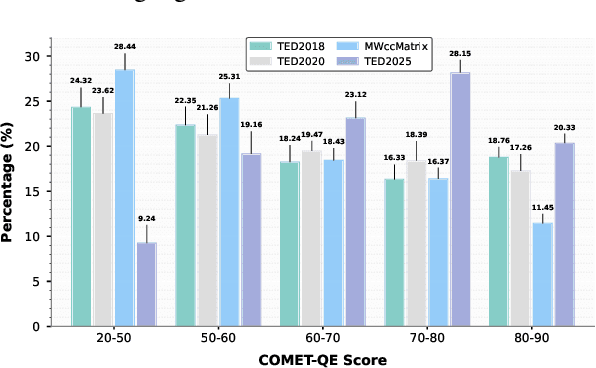
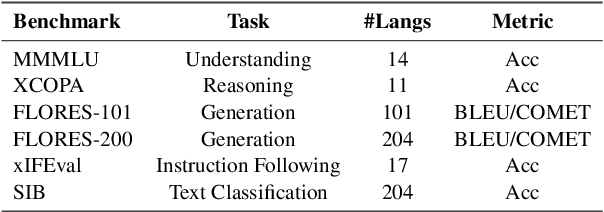
Continued pretraining and instruction tuning on large-scale multilingual data have proven to be effective in scaling large language models (LLMs) to low-resource languages. However, the unaligned nature of such data limits its ability to effectively capture cross-lingual semantics. In contrast, multi-way parallel data, where identical content is aligned across multiple languages, provides stronger cross-lingual consistency and offers greater potential for improving multilingual performance. In this paper, we introduce a large-scale, high-quality multi-way parallel corpus, TED2025, based on TED Talks. The corpus spans 113 languages, with up to 50 languages aligned in parallel, ensuring extensive multilingual coverage. Using this dataset, we investigate best practices for leveraging multi-way parallel data to enhance LLMs, including strategies for continued pretraining, instruction tuning, and the analysis of key influencing factors. Experiments on six multilingual benchmarks show that models trained on multiway parallel data consistently outperform those trained on unaligned multilingual data.
Can Prompting LLMs Unlock Hate Speech Detection across Languages? A Zero-shot and Few-shot Study
May 09, 2025Despite growing interest in automated hate speech detection, most existing approaches overlook the linguistic diversity of online content. Multilingual instruction-tuned large language models such as LLaMA, Aya, Qwen, and BloomZ offer promising capabilities across languages, but their effectiveness in identifying hate speech through zero-shot and few-shot prompting remains underexplored. This work evaluates LLM prompting-based detection across eight non-English languages, utilizing several prompting techniques and comparing them to fine-tuned encoder models. We show that while zero-shot and few-shot prompting lag behind fine-tuned encoder models on most of the real-world evaluation sets, they achieve better generalization on functional tests for hate speech detection. Our study also reveals that prompt design plays a critical role, with each language often requiring customized prompting techniques to maximize performance.