 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal inference and model explainability tools for retail
Dec 14, 2025Most major retailers today have multiple divisions focused on various aspects, such as marketing, supply chain, online customer experience, store customer experience, employee productivity, and vendor fulfillment. They also regularly collect data corresponding to all these aspects as dashboards and weekly/monthly/quarterly reports. Although several machine learning and statistical techniques have been in place to analyze and predict key metrics, such models typically lack interpretability. Moreover, such techniques also do not allow the validation or discovery of causal links. In this paper, we aim to provide a recipe for applying model interpretability and causal inference for deriving sales insights. In this paper, we review the existing literature on causal inference and interpretability in the context of problems in e-commerce and retail, and apply them to a real-world dataset. We find that an inherently explainable model has a lower variance of SHAP values, and show that including multiple confounders through a double machine learning approach allows us to get the correct sign of causal effect.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
OLAF: A Plug-and-Play Framework for Enhanced Multi-object Multi-part Scene Parsing
Nov 05, 2024Multi-object multi-part scene segmentation is a challenging task whose complexity scales exponentially with part granularity and number of scene objects. To address the task, we propose a plug-and-play approach termed OLAF. First, we augment the input (RGB) with channels containing object-based structural cues (fg/bg mask, boundary edge mask). We propose a weight adaptation technique which enables regular (RGB) pre-trained models to process the augmented (5-channel) input in a stable manner during optimization. In addition, we introduce an encoder module termed LDF to provide low-level dense feature guidance. This assists segmentation, particularly for smaller parts. OLAF enables significant mIoU gains of $\mathbf{3.3}$ (Pascal-Parts-58), $\mathbf{3.5}$ (Pascal-Parts-108) over the SOTA model. On the most challenging variant (Pascal-Parts-201), the gain is $\mathbf{4.0}$. Experimentally, we show that OLAF's broad applicability enables gains across multiple architectures (CNN, U-Net, Transformer) and datasets. The code is available at olafseg.github.io
VARS: Vision-based Assessment of Risk in Security Systems
Oct 25, 2024



The accurate prediction of danger levels in video content is critical for enhancing safety and security systems, particularly in environments where quick and reliable assessments are essential. In this study, we perform a comparative analysis of various machine learning and deep learning models to predict danger ratings in a custom dataset of 100 videos, each containing 50 frames, annotated with human-rated danger scores ranging from 0 to 10. The danger ratings are further classified into three categories: no alert (less than 7)and high alert (greater than equal to 7). Our evaluation covers classical machine learning models, such as Support Vector Machines, as well as Neural Networks, and transformer-based models. Model performance is assessed using standard metrics such as accuracy, F1-score, and mean absolute error (MAE), and the results are compared to identify the most robust approach. This research contributes to developing a more accurate and generalizable danger assessment framework for video-based risk detection.
CVCP-Fusion: On Implicit Depth Estimation for 3D Bounding Box Prediction
Oct 15, 2024


Combining LiDAR and Camera-view data has become a common approach for 3D Object Detection. However, previous approaches combine the two input streams at a point-level, throwing away semantic information derived from camera features. In this paper we propose Cross-View Center Point-Fusion, a state-of-the-art model to perform 3D object detection by combining camera and LiDAR-derived features in the BEV space to preserve semantic density from the camera stream while incorporating spacial data from the LiDAR stream. Our architecture utilizes aspects from previously established algorithms, Cross-View Transformers and CenterPoint, and runs their backbones in parallel, allowing efficient computation for real-time processing and application. In this paper we find that while an implicitly calculated depth-estimate may be sufficiently accurate in a 2D map-view representation, explicitly calculated geometric and spacial information is needed for precise bounding box prediction in the 3D world-view space.
ViDAS: Vision-based Danger Assessment and Scoring
Oct 01, 2024

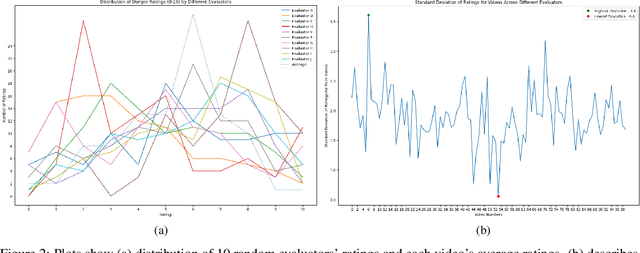

We present a novel dataset aimed at advancing danger analysis and assessment by addressing the challenge of quantifying danger in video content and identifying how human-like a Large Language Model (LLM) evaluator is for the same. This is achieved by compiling a collection of 100 YouTube videos featuring various events. Each video is annotated by human participants who provided danger ratings on a scale from 0 (no danger to humans) to 10 (life-threatening), with precise timestamps indicating moments of heightened danger. Additionally, we leverage LLMs to independently assess the danger levels in these videos using video summaries. We introduce Mean Squared Error (MSE) scores for multimodal meta-evaluation of the alignment between human and LLM danger assessments. Our dataset not only contributes a new resource for danger assessment in video content but also demonstrates the potential of LLMs in achieving human-like evaluations.
ECHO: Environmental Sound Classification with Hierarchical Ontology-guided Semi-Supervised Learning
Sep 21, 2024Environment Sound Classification has been a well-studied research problem in the field of signal processing and up till now more focus has been laid on fully supervised approaches. Over the last few years, focus has moved towards semi-supervised methods which concentrate on the utilization of unlabeled data, and self-supervised methods which learn the intermediate representation through pretext task or contrastive learning. However, both approaches require a vast amount of unlabelled data to improve performance. In this work, we propose a novel framework called Environmental Sound Classification with Hierarchical Ontology-guided semi-supervised Learning (ECHO) that utilizes label ontology-based hierarchy to learn semantic representation by defining a novel pretext task. In the pretext task, the model tries to predict coarse labels defined by the Large Language Model (LLM) based on ground truth label ontology. The trained model is further fine-tuned in a supervised way to predict the actual task. Our proposed novel semi-supervised framework achieves an accuracy improvement in the range of 1\% to 8\% over baseline systems across three datasets namely UrbanSound8K, ESC-10, and ESC-50.
Testing LLM performance on the Physics GRE: some observations
Dec 07, 2023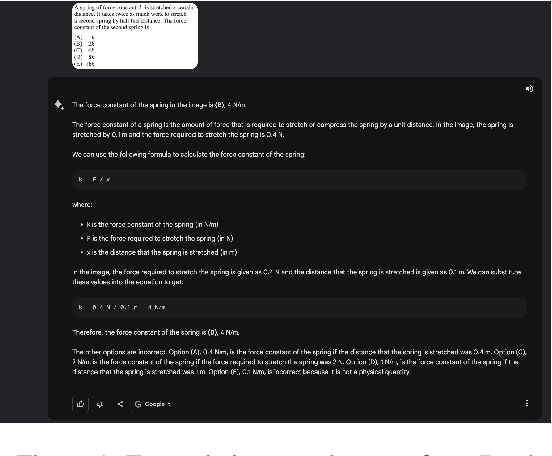

With the recent developments in large language models (LLMs) and their widespread availability through open source models and/or low-cost APIs, several exciting products and applications are emerging, many of which are in the field of STEM educational technology for K-12 and university students. There is a need to evaluate these powerful language models on several benchmarks, in order to understand their risks and limitations. In this short paper, we summarize and analyze the performance of Bard, a popular LLM-based conversational service made available by Google, on the standardized Physics GRE examination.
FLOAT: Factorized Learning of Object Attributes for Improved Multi-object Multi-part Scene Parsing
Mar 30, 2022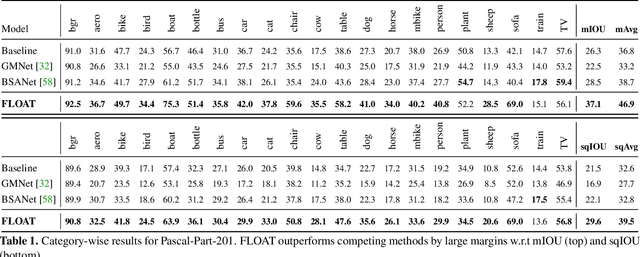
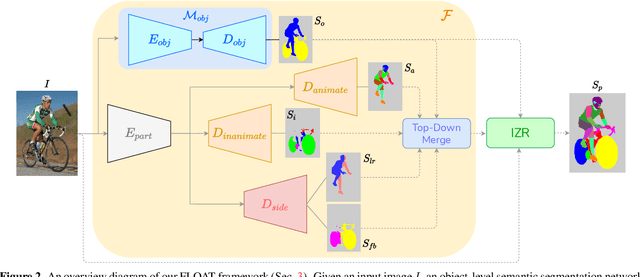
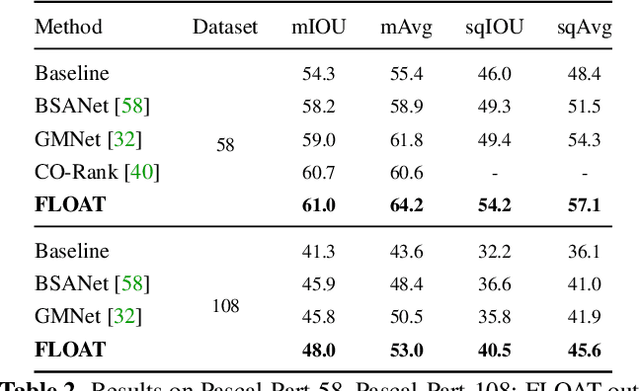
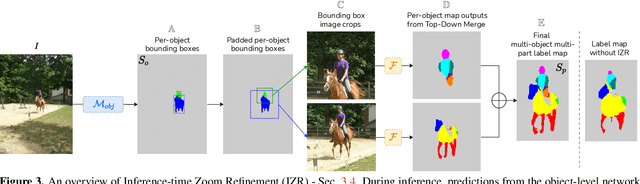
Multi-object multi-part scene parsing is a challenging task which requires detecting multiple object classes in a scene and segmenting the semantic parts within each object. In this paper, we propose FLOAT, a factorized label space framework for scalable multi-object multi-part parsing. Our framework involves independent dense prediction of object category and part attributes which increases scalability and reduces task complexity compared to the monolithic label space counterpart. In addition, we propose an inference-time 'zoom' refinement technique which significantly improves segmentation quality, especially for smaller objects/parts. Compared to state of the art, FLOAT obtains an absolute improvement of 2.0% for mean IOU (mIOU) and 4.8% for segmentation quality IOU (sqIOU) on the Pascal-Part-58 dataset. For the larger Pascal-Part-108 dataset, the improvements are 2.1% for mIOU and 3.9% for sqIOU. We incorporate previously excluded part attributes and other minor parts of the Pascal-Part dataset to create the most comprehensive and challenging version which we dub Pascal-Part-201. FLOAT obtains improvements of 8.6% for mIOU and 7.5% for sqIOU on the new dataset, demonstrating its parsing effectiveness across a challenging diversity of objects and parts. The code and datasets are available at floatseg.github.io.
An active inference model of collective intelligence
Apr 02, 2021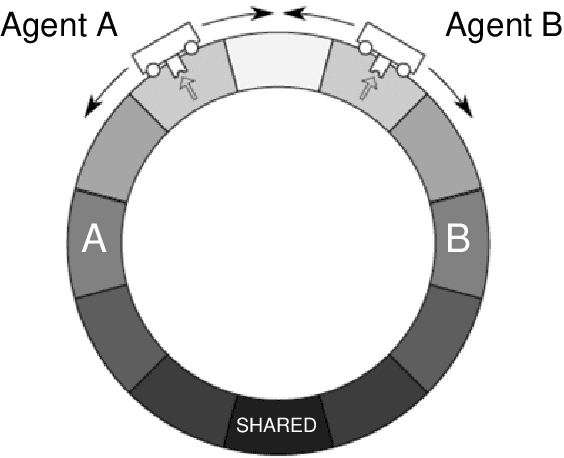

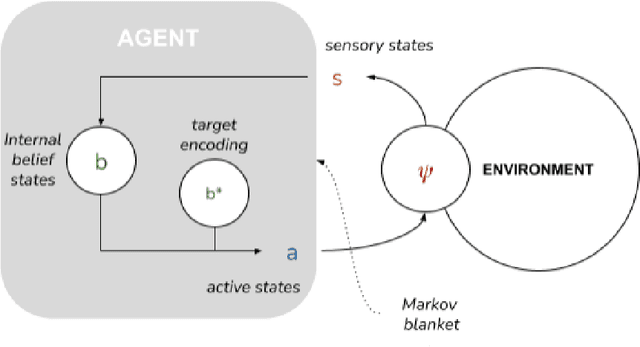
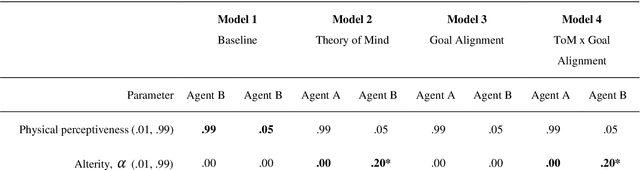
To date, formal models of collective intelligence have lacked a plausible mathematical description of the relationship between local-scale interactions between highly autonomous sub-system components (individuals) and global-scale behavior of the composite system (the collective). In this paper we use the Active Inference Formulation (AIF), a framework for explaining the behavior of any non-equilibrium steady state system at any scale, to posit a minimal agent-based model that simulates the relationship between local individual-level interaction and collective intelligence (operationalized as system-level performance). We explore the effects of providing baseline AIF agents (Model 1) with specific cognitive capabilities: Theory of Mind (Model 2); Goal Alignment (Model 3), and Theory of Mind with Goal Alignment (Model 4). These stepwise transitions in sophistication of cognitive ability are motivated by the types of advancements plausibly required for an AIF agent to persist and flourish in an environment populated by other AIF agents, and have also recently been shown to map naturally to canonical steps in human cognitive ability. Illustrative results show that stepwise cognitive transitions increase system performance by providing complementary mechanisms for alignment between agents' local and global optima. Alignment emerges endogenously from the dynamics of interacting AIF agents themselves, rather than being imposed exogenously by incentives to agents' behaviors (contra existing computational models of collective intelligence) or top-down priors for collective behavior (contra existing multiscale simulations of AIF). These results shed light on the types of generic information-theoretic patterns conducive to collective intelligence in human and other complex adaptive systems.