 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVARS: Vision-based Assessment of Risk in Security Systems
Oct 25, 2024



The accurate prediction of danger levels in video content is critical for enhancing safety and security systems, particularly in environments where quick and reliable assessments are essential. In this study, we perform a comparative analysis of various machine learning and deep learning models to predict danger ratings in a custom dataset of 100 videos, each containing 50 frames, annotated with human-rated danger scores ranging from 0 to 10. The danger ratings are further classified into three categories: no alert (less than 7)and high alert (greater than equal to 7). Our evaluation covers classical machine learning models, such as Support Vector Machines, as well as Neural Networks, and transformer-based models. Model performance is assessed using standard metrics such as accuracy, F1-score, and mean absolute error (MAE), and the results are compared to identify the most robust approach. This research contributes to developing a more accurate and generalizable danger assessment framework for video-based risk detection.
ViDAS: Vision-based Danger Assessment and Scoring
Oct 01, 2024

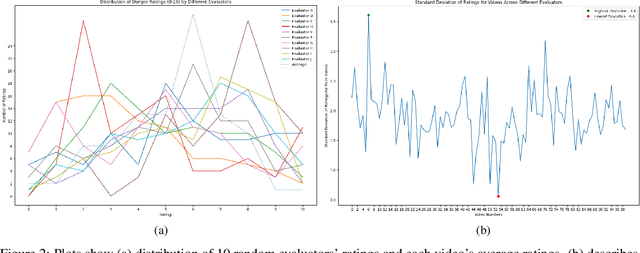

We present a novel dataset aimed at advancing danger analysis and assessment by addressing the challenge of quantifying danger in video content and identifying how human-like a Large Language Model (LLM) evaluator is for the same. This is achieved by compiling a collection of 100 YouTube videos featuring various events. Each video is annotated by human participants who provided danger ratings on a scale from 0 (no danger to humans) to 10 (life-threatening), with precise timestamps indicating moments of heightened danger. Additionally, we leverage LLMs to independently assess the danger levels in these videos using video summaries. We introduce Mean Squared Error (MSE) scores for multimodal meta-evaluation of the alignment between human and LLM danger assessments. Our dataset not only contributes a new resource for danger assessment in video content but also demonstrates the potential of LLMs in achieving human-like evaluations.