 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Uchaguzi-2022: A Dataset of Citizen Reports on the 2022 Kenyan Election
Dec 17, 2024



Online reporting platforms have enabled citizens around the world to collectively share their opinions and report in real time on events impacting their local communities. Systematically organizing (e.g., categorizing by attributes) and geotagging large amounts of crowdsourced information is crucial to ensuring that accurate and meaningful insights can be drawn from this data and used by policy makers to bring about positive change. These tasks, however, typically require extensive manual annotation efforts. In this paper we present Uchaguzi-2022, a dataset of 14k categorized and geotagged citizen reports related to the 2022 Kenyan General Election containing mentions of election-related issues such as official misconduct, vote count irregularities, and acts of violence. We use this dataset to investigate whether language models can assist in scalably categorizing and geotagging reports, thus highlighting its potential application in the AI for Social Good space.
Towards a Framework for Evaluating Explanations in Automated Fact Verification
Mar 29, 2024As deep neural models in NLP become more complex, and as a consequence opaque, the necessity to interpret them becomes greater. A burgeoning interest has emerged in rationalizing explanations to provide short and coherent justifications for predictions. In this position paper, we advocate for a formal framework for key concepts and properties about rationalizing explanations to support their evaluation systematically. We also outline one such formal framework, tailored to rationalizing explanations of increasingly complex structures, from free-form explanations to deductive explanations, to argumentative explanations (with the richest structure). Focusing on the automated fact verification task, we provide illustrations of the use and usefulness of our formalization for evaluating explanations, tailored to their varying structures.
Little Giants: Exploring the Potential of Small LLMs as Evaluation Metrics in Summarization in the Eval4NLP 2023 Shared Task
Nov 01, 2023



This paper describes and analyzes our participation in the 2023 Eval4NLP shared task, which focuses on assessing the effectiveness of prompt-based techniques to empower Large Language Models to handle the task of quality estimation, particularly in the context of evaluating machine translations and summaries. We conducted systematic experiments with various prompting techniques, including standard prompting, prompts informed by annotator instructions, and innovative chain-of-thought prompting. In addition, we integrated these approaches with zero-shot and one-shot learning methods to maximize the efficacy of our evaluation procedures. Our work reveals that combining these approaches using a "small", open source model (orca_mini_v3_7B) yields competitive results.
Policy Compliance Detection via Expression Tree Inference
May 24, 2022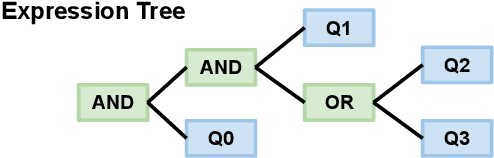

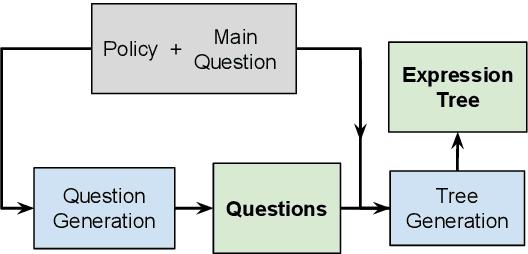
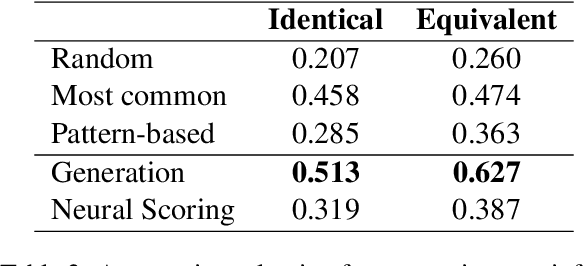
Policy Compliance Detection (PCD) is a task we encounter when reasoning over texts, e.g. legal frameworks. Previous work to address PCD relies heavily on modeling the task as a special case of Recognizing Textual Entailment. Entailment is applicable to the problem of PCD, however viewing the policy as a single proposition, as opposed to multiple interlinked propositions, yields poor performance and lacks explainability. To address this challenge, more recent proposals for PCD have argued for decomposing policies into expression trees consisting of questions connected with logic operators. Question answering is used to obtain answers to these questions with respect to a scenario. Finally, the expression tree is evaluated in order to arrive at an overall solution. However, this work assumes expression trees are provided by experts, thus limiting its applicability to new policies. In this work, we learn how to infer expression trees automatically from policy texts. We ensure the validity of the inferred trees by introducing constrained decoding using a finite state automaton to ensure the generation of valid trees. We determine through automatic evaluation that 63% of the expression trees generated by our constrained generation model are logically equivalent to gold trees. Human evaluation shows that 88% of trees generated by our model are correct.
Graph Reasoning with Context-Aware Linearization for Interpretable Fact Extraction and Verification
Sep 25, 2021
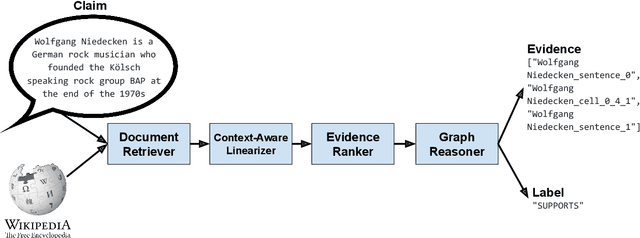

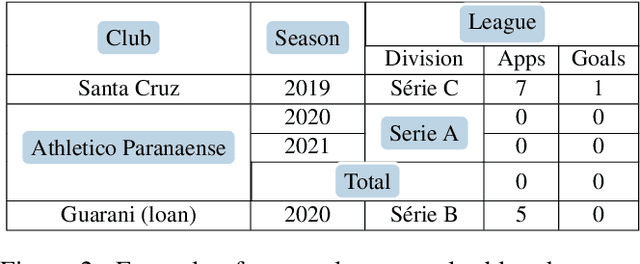
This paper presents an end-to-end system for fact extraction and verification using textual and tabular evidence, the performance of which we demonstrate on the FEVEROUS dataset. We experiment with both a multi-task learning paradigm to jointly train a graph attention network for both the task of evidence extraction and veracity prediction, as well as a single objective graph model for solely learning veracity prediction and separate evidence extraction. In both instances, we employ a framework for per-cell linearization of tabular evidence, thus allowing us to treat evidence from tables as sequences. The templates we employ for linearizing tables capture the context as well as the content of table data. We furthermore provide a case study to show the interpretability our approach. Our best performing system achieves a FEVEROUS score of 0.23 and 53% label accuracy on the blind test data.
Explainable Automated Fact-Checking: A Survey
Nov 07, 2020
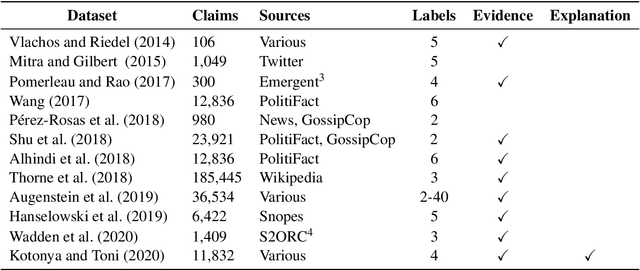
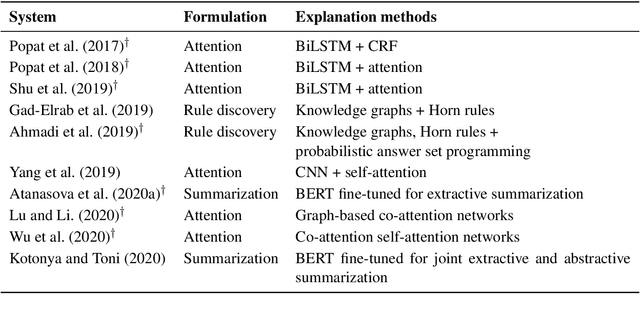
A number of exciting advances have been made in automated fact-checking thanks to increasingly larger datasets and more powerful systems, leading to improvements in the complexity of claims which can be accurately fact-checked. However, despite these advances, there are still desirable functionalities missing from the fact-checking pipeline. In this survey, we focus on the explanation functionality -- that is fact-checking systems providing reasons for their predictions. We summarize existing methods for explaining the predictions of fact-checking systems and we explore trends in this topic. Further, we consider what makes for good explanations in this specific domain through a comparative analysis of existing fact-checking explanations against some desirable properties. Finally, we propose further research directions for generating fact-checking explanations, and describe how these may lead to improvements in the research area.
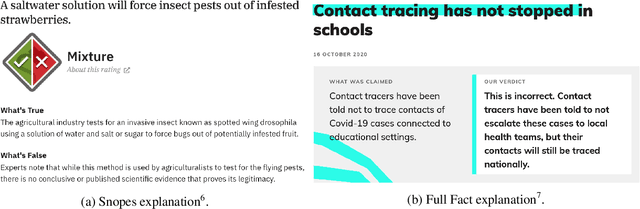
Explainable Automated Fact-Checking for Public Health Claims
Oct 19, 2020
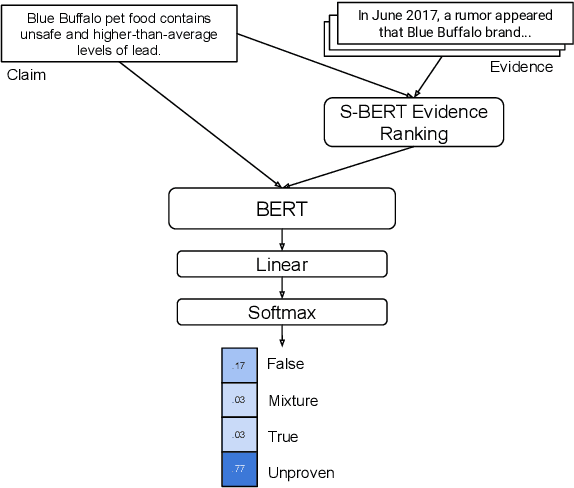
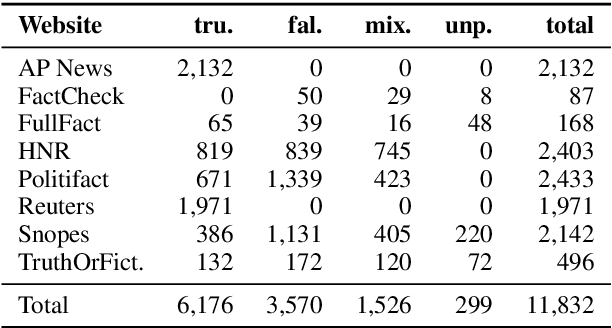

Fact-checking is the task of verifying the veracity of claims by assessing their assertions against credible evidence. The vast majority of fact-checking studies focus exclusively on political claims. Very little research explores fact-checking for other topics, specifically subject matters for which expertise is required. We present the first study of explainable fact-checking for claims which require specific expertise. For our case study we choose the setting of public health. To support this case study we construct a new dataset PUBHEALTH of 11.8K claims accompanied by journalist crafted, gold standard explanations (i.e., judgments) to support the fact-check labels for claims. We explore two tasks: veracity prediction and explanation generation. We also define and evaluate, with humans and computationally, three coherence properties of explanation quality. Our results indicate that, by training on in-domain data, gains can be made in explainable, automated fact-checking for claims which require specific expertise.