 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRADE: Generalizable Reasoning-Aware Dialogue Evaluation for AI Tutors
May 27, 2026Evaluating AI tutor responses requires more than factual correctness: tutors must identify mistakes, locate errors, provide guidance, and offer actionable next steps. We present GRADE, a systematic study of open-source models for pedagogical ability assessment in student-tutor dialogues. Building on the BEA 2025 TutorMind setting, we evaluate 120 configurations across five language models, zero-shot inference, LoRA fine-tuning, synthetic augmentation, CoT+Reasoning, and single-task versus multitask formulations. Gemma3-12B performs best for single-task evaluation, while Gemma3-27B in 8-bit precision is more reliable for multitask prediction. We find that augmentation helps models that struggle with the original data, verification adds limited gains despite higher cost, and CoT+Reasoning is more useful for synthetic data generation than direct classification. We further show that LoRA fine-tuning on structured classification objectives interferes with instruction-following behavior under thinking mode, redirecting generation away from the required evaluation format. Carbon analysis shows that model choice and reasoning mode substantially affect emissions. Overall, GRADE shows that carefully selected open-source LoRA pipelines can match or surpass proprietary and ensemble-based systems on key pedagogical dimensions, with code and data available at https://github.com/pvbgeek/GRADE.
Beyond Factual QA: Mentorship-Oriented Question Answering over Long-Form Multilingual Content
Jan 23, 2026Question answering systems are typically evaluated on factual correctness, yet many real-world applications-such as education and career guidance-require mentorship: responses that provide reflection and guidance. Existing QA benchmarks rarely capture this distinction, particularly in multilingual and long-form settings. We introduce MentorQA, the first multilingual dataset and evaluation framework for mentorship-focused question answering from long-form videos, comprising nearly 9,000 QA pairs from 180 hours of content across four languages. We define mentorship-focused evaluation dimensions that go beyond factual accuracy, capturing clarity, alignment, and learning value. Using MentorQA, we compare Single-Agent, Dual-Agent, RAG, and Multi-Agent QA architectures under controlled conditions. Multi-Agent pipelines consistently produce higher-quality mentorship responses, with especially strong gains for complex topics and lower-resource languages. We further analyze the reliability of automated LLM-based evaluation, observing substantial variation in alignment with human judgments. Overall, this work establishes mentorship-focused QA as a distinct research problem and provides a multilingual benchmark for studying agentic architectures and evaluation design in educational AI. The dataset and evaluation framework are released at https://github.com/AIM-SCU/MentorQA.
Beyond Translation: Cross-Cultural Meme Transcreation with Vision-Language Models
Jan 23, 2026Memes are a pervasive form of online communication, yet their cultural specificity poses significant challenges for cross-cultural adaptation. We study cross-cultural meme transcreation, a multimodal generation task that aims to preserve communicative intent and humor while adapting culture-specific references. We propose a hybrid transcreation framework based on vision-language models and introduce a large-scale bidirectional dataset of Chinese and US memes. Using both human judgments and automated evaluation, we analyze 6,315 meme pairs and assess transcreation quality across cultural directions. Our results show that current vision-language models can perform cross-cultural meme transcreation to a limited extent, but exhibit clear directional asymmetries: US-Chinese transcreation consistently achieves higher quality than Chinese-US. We further identify which aspects of humor and visual-textual design transfer across cultures and which remain challenging, and propose an evaluation framework for assessing cross-cultural multimodal generation. Our code and dataset are publicly available at https://github.com/AIM-SCU/MemeXGen.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
Multi-Agent Multimodal Models for Multicultural Text to Image Generation
Feb 21, 2025
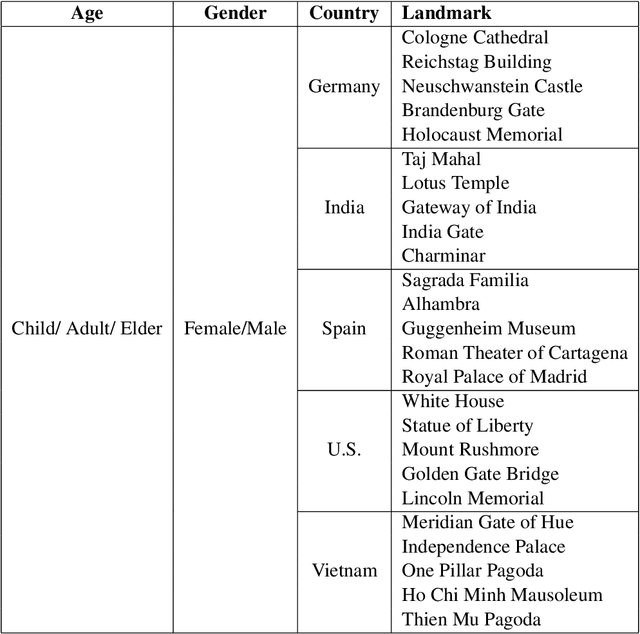
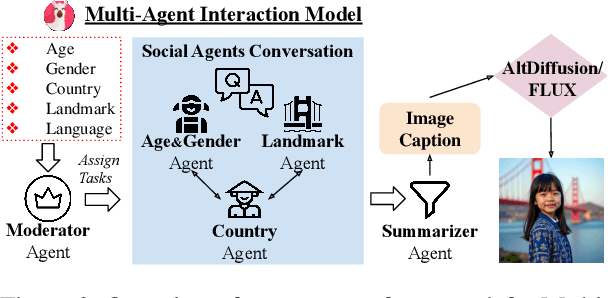
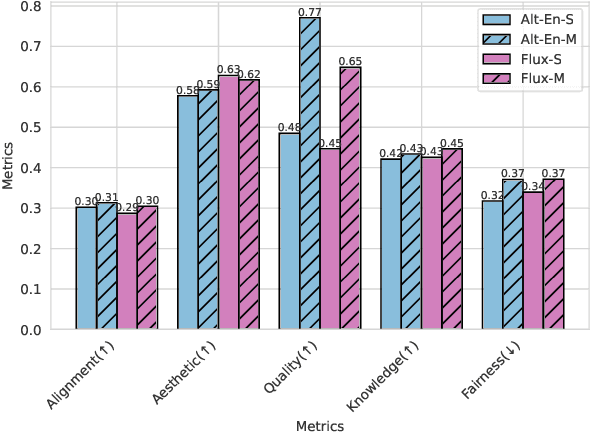
Large Language Models (LLMs) demonstrate impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of existing data and models. Meanwhile, multi-agent models have shown strong capabilities in solving complex tasks. In this paper, we evaluate the performance of LLMs in a multi-agent interaction setting for the novel task of multicultural image generation. Our key contributions are: (1) We introduce MosAIG, a Multi-Agent framework that enhances multicultural Image Generation by leveraging LLMs with distinct cultural personas; (2) We provide a dataset of 9,000 multicultural images spanning five countries, three age groups, two genders, 25 historical landmarks, and five languages; and (3) We demonstrate that multi-agent interactions outperform simple, no-agent models across multiple evaluation metrics, offering valuable insights for future research. Our dataset and models are available at https://github.com/OanaIgnat/MosAIG.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
The Power of Many: Multi-Agent Multimodal Models for Cultural Image Captioning
Nov 18, 2024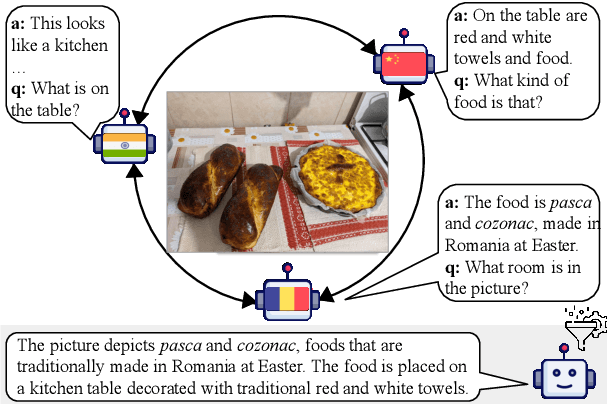
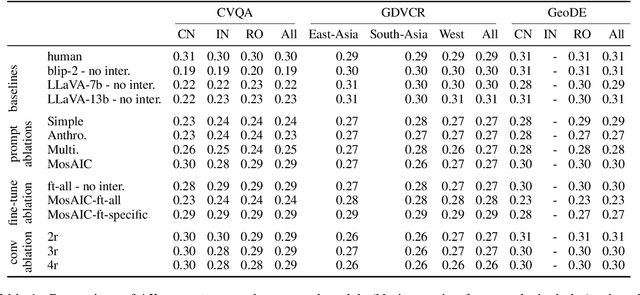
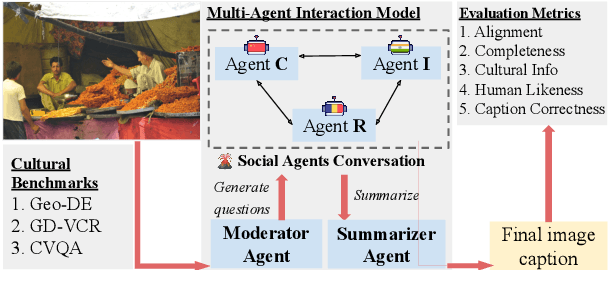
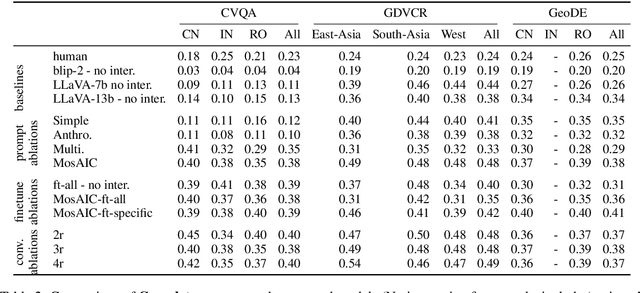
Large Multimodal Models (LMMs) exhibit impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of most data and models. Conversely, multi-agent models have shown significant capability in solving complex tasks. Our study evaluates the collective performance of LMMs in a multi-agent interaction setting for the novel task of cultural image captioning. Our contributions are as follows: (1) We introduce MosAIC, a Multi-Agent framework to enhance cross-cultural Image Captioning using LMMs with distinct cultural personas; (2) We provide a dataset of culturally enriched image captions in English for images from China, India, and Romania across three datasets: GeoDE, GD-VCR, CVQA; (3) We propose a culture-adaptable metric for evaluating cultural information within image captions; and (4) We show that the multi-agent interaction outperforms single-agent models across different metrics, and offer valuable insights for future research. Our dataset and models can be accessed at https://github.com/MichiganNLP/MosAIC.
Uplifting Lower-Income Data: Strategies for Socioeconomic Perspective Shifts in Vision-Language Models
Jul 02, 2024



To address this issue, we formulate translated non-English, geographic, and socioeconomic integrated prompts and evaluate their impact on VL model performance for data from different countries and income groups. Our findings show that geographic and socioeconomic integrated prompts improve VL performance on lower-income data and favor the retrieval of topic appearances commonly found in data from low-income households. From our analyses, we identify and highlight contexts where these strategies yield the most improvements. Our model analysis code is publicly available at https://github.com/Anniejoan/Uplifting-Lower-income-data .
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.