 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Multimodal Models for Multicultural Text to Image Generation
Feb 21, 2025
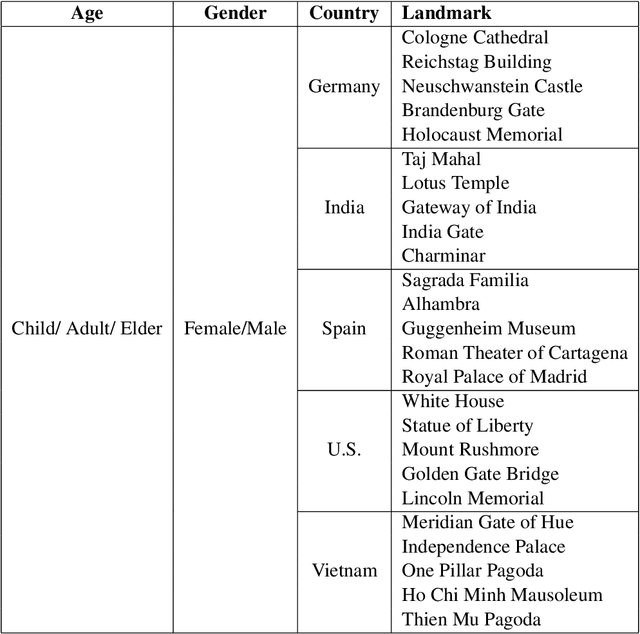
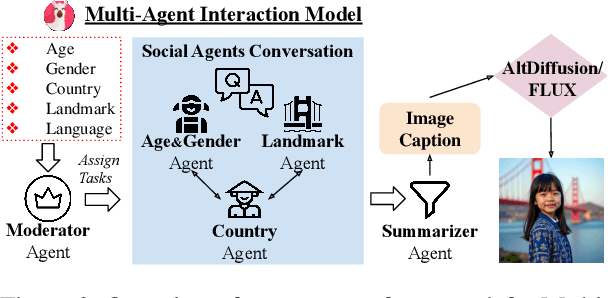
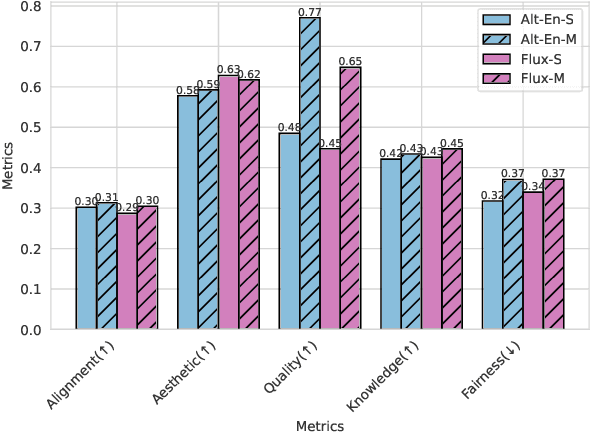
Large Language Models (LLMs) demonstrate impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of existing data and models. Meanwhile, multi-agent models have shown strong capabilities in solving complex tasks. In this paper, we evaluate the performance of LLMs in a multi-agent interaction setting for the novel task of multicultural image generation. Our key contributions are: (1) We introduce MosAIG, a Multi-Agent framework that enhances multicultural Image Generation by leveraging LLMs with distinct cultural personas; (2) We provide a dataset of 9,000 multicultural images spanning five countries, three age groups, two genders, 25 historical landmarks, and five languages; and (3) We demonstrate that multi-agent interactions outperform simple, no-agent models across multiple evaluation metrics, offering valuable insights for future research. Our dataset and models are available at https://github.com/OanaIgnat/MosAIG.