 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Sockpuppetry on Wikipedia Using Meta-Learning
Jun 12, 2025Malicious sockpuppet detection on Wikipedia is critical to preserving access to reliable information on the internet and preventing the spread of disinformation. Prior machine learning approaches rely on stylistic and meta-data features, but do not prioritise adaptability to author-specific behaviours. As a result, they struggle to effectively model the behaviour of specific sockpuppet-groups, especially when text data is limited. To address this, we propose the application of meta-learning, a machine learning technique designed to improve performance in data-scarce settings by training models across multiple tasks. Meta-learning optimises a model for rapid adaptation to the writing style of a new sockpuppet-group. Our results show that meta-learning significantly enhances the precision of predictions compared to pre-trained models, marking an advancement in combating sockpuppetry on open editing platforms. We release a new dataset of sockpuppet investigations to foster future research in both sockpuppetry and meta-learning fields.
SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection
Mar 10, 2025We present our shared task on text-based emotion detection, covering more than 30 languages from seven distinct language families. These languages are predominantly low-resource and spoken across various continents. The data instances are multi-labeled into six emotional classes, with additional datasets in 11 languages annotated for emotion intensity. Participants were asked to predict labels in three tracks: (a) emotion labels in monolingual settings, (b) emotion intensity scores, and (c) emotion labels in cross-lingual settings. The task attracted over 700 participants. We received final submissions from more than 200 teams and 93 system description papers. We report baseline results, as well as findings on the best-performing systems, the most common approaches, and the most effective methods across various tracks and languages. The datasets for this task are publicly available.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024

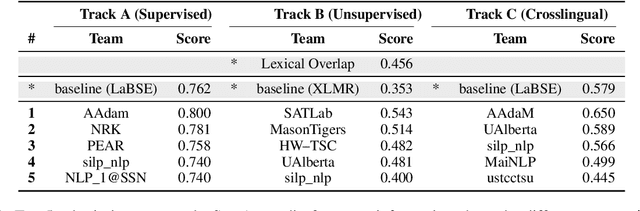
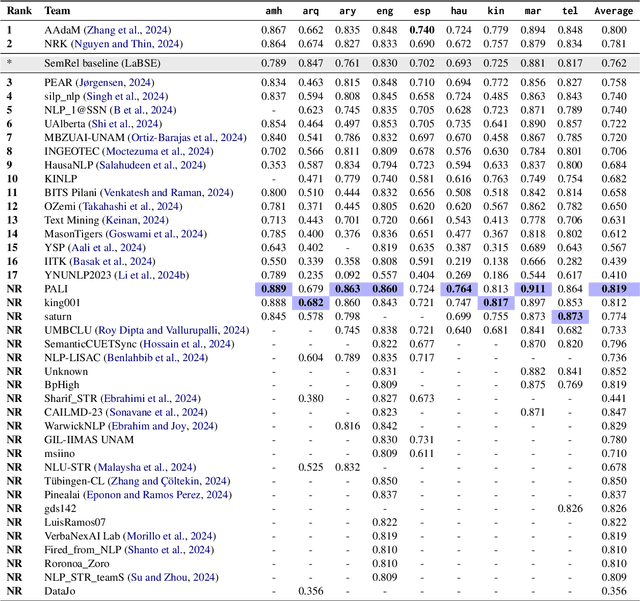
We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.