 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
Fine-grained Contract NER using instruction based model
Jan 24, 2024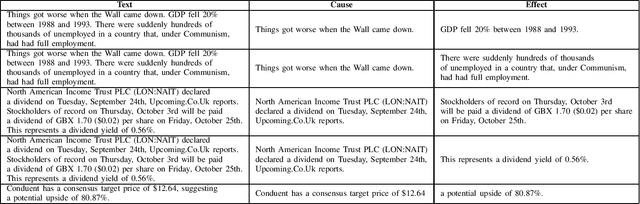


Lately, instruction-based techniques have made significant strides in improving performance in few-shot learning scenarios. They achieve this by bridging the gap between pre-trained language models and fine-tuning for specific downstream tasks. Despite these advancements, the performance of Large Language Models (LLMs) in information extraction tasks like Named Entity Recognition (NER), using prompts or instructions, still falls short of supervised baselines. The reason for this performance gap can be attributed to the fundamental disparity between NER and LLMs. NER is inherently a sequence labeling task, where the model must assign entity-type labels to individual tokens within a sentence. In contrast, LLMs are designed as a text generation task. This distinction between semantic labeling and text generation leads to subpar performance. In this paper, we transform the NER task into a text-generation task that can be readily adapted by LLMs. This involves enhancing source sentences with task-specific instructions and answer choices, allowing for the identification of entities and their types within natural language. We harness the strength of LLMs by integrating supervised learning within them. The goal of this combined strategy is to boost the performance of LLMs in extraction tasks like NER while simultaneously addressing hallucination issues often observed in LLM-generated content. A novel corpus Contract NER comprising seven frequently observed contract categories, encompassing named entities associated with 18 distinct legal entity types is released along with our baseline models. Our models and dataset are available to the community for future research * .
Unsupervised Approach to Evaluate Sentence-Level Fluency: Do We Really Need Reference?
Dec 03, 2023



Fluency is a crucial goal of all Natural Language Generation (NLG) systems. Widely used automatic evaluation metrics fall short in capturing the fluency of machine-generated text. Assessing the fluency of NLG systems poses a challenge since these models are not limited to simply reusing words from the input but may also generate abstractions. Existing reference-based fluency evaluations, such as word overlap measures, often exhibit weak correlations with human judgments. This paper adapts an existing unsupervised technique for measuring text fluency without the need for any reference. Our approach leverages various word embeddings and trains language models using Recurrent Neural Network (RNN) architectures. We also experiment with other available multilingual Language Models (LMs). To assess the performance of the models, we conduct a comparative analysis across 10 Indic languages, correlating the obtained fluency scores with human judgments. Our code and human-annotated benchmark test-set for fluency is available at https://github.com/AnanyaCoder/TextFluencyForIndicLanaguges.