 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Ideate: A Framework for Product Idea Generation from Patents Using Agentic AI
Jul 02, 2025Patents contain rich technical knowledge that can inspire innovative product ideas, yet accessing and interpreting this information remains a challenge. This work explores the use of Large Language Models (LLMs) and autonomous agents to mine and generate product concepts from a given patent. In this work, we design Agent Ideate, a framework for automatically generating product-based business ideas from patents. We experimented with open-source LLMs and agent-based architectures across three domains: Computer Science, Natural Language Processing, and Material Chemistry. Evaluation results show that the agentic approach consistently outperformed standalone LLMs in terms of idea quality, relevance, and novelty. These findings suggest that combining LLMs with agentic workflows can significantly enhance the innovation pipeline by unlocking the untapped potential of business idea generation from patent data.
No LLM is Free From Bias: A Comprehensive Study of Bias Evaluation in Large Language models
Mar 15, 2025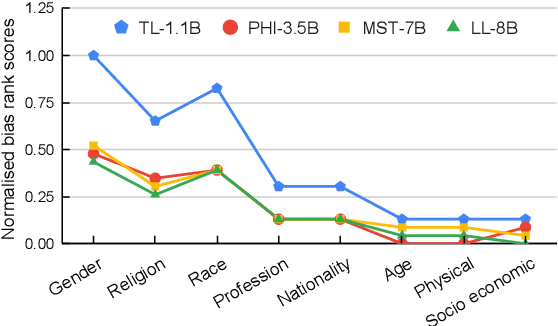
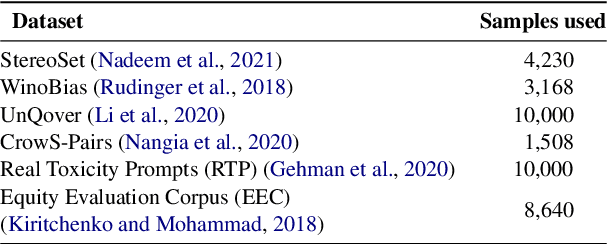
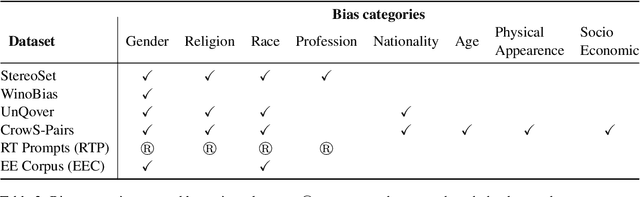

Advancements in Large Language Models (LLMs) have increased the performance of different natural language understanding as well as generation tasks. Although LLMs have breached the state-of-the-art performance in various tasks, they often reflect different forms of bias present in the training data. In the light of this perceived limitation, we provide a unified evaluation of benchmarks using a set of representative LLMs that cover different forms of biases starting from physical characteristics to socio-economic categories. Moreover, we propose five prompting approaches to carry out the bias detection task across different aspects of bias. Further, we formulate three research questions to gain valuable insight in detecting biases in LLMs using different approaches and evaluation metrics across benchmarks. The results indicate that each of the selected LLMs suffer from one or the other form of bias with the LLaMA3.1-8B model being the least biased. Finally, we conclude the paper with the identification of key challenges and possible future directions.
HalluCounter: Reference-free LLM Hallucination Detection in the Wild!
Mar 06, 2025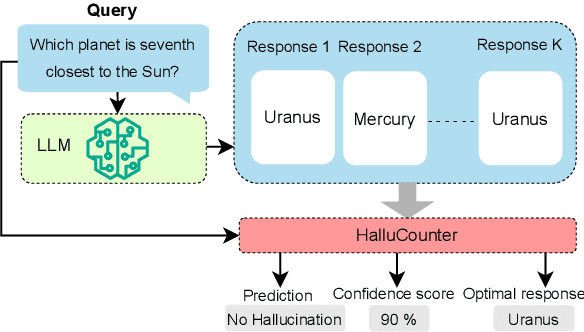

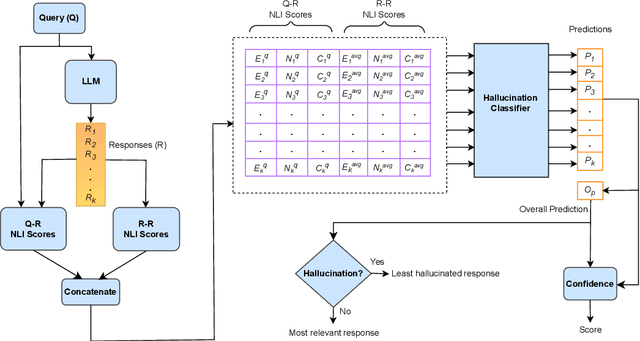
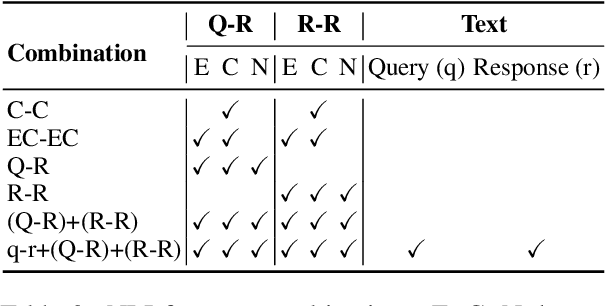
Response consistency-based, reference-free hallucination detection (RFHD) methods do not depend on internal model states, such as generation probabilities or gradients, which Grey-box models typically rely on but are inaccessible in closed-source LLMs. However, their inability to capture query-response alignment patterns often results in lower detection accuracy. Additionally, the lack of large-scale benchmark datasets spanning diverse domains remains a challenge, as most existing datasets are limited in size and scope. To this end, we propose HalluCounter, a novel reference-free hallucination detection method that utilizes both response-response and query-response consistency and alignment patterns. This enables the training of a classifier that detects hallucinations and provides a confidence score and an optimal response for user queries. Furthermore, we introduce HalluCounterEval, a benchmark dataset comprising both synthetically generated and human-curated samples across multiple domains. Our method outperforms state-of-the-art approaches by a significant margin, achieving over 90\% average confidence in hallucination detection across datasets.
TeClass: A Human-Annotated Relevance-based Headline Classification and Generation Dataset for Telugu
Apr 17, 2024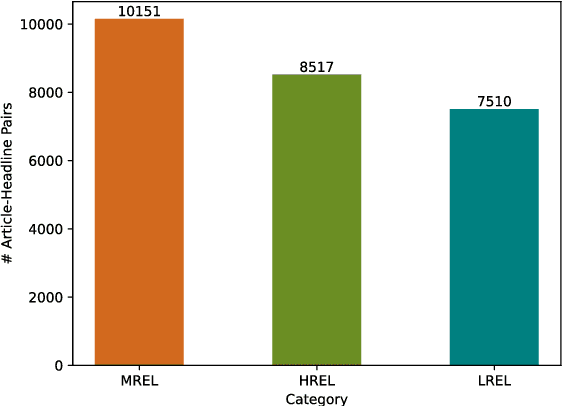
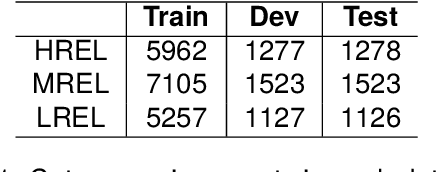
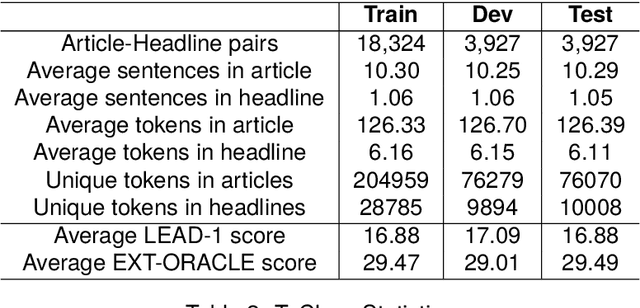

News headline generation is a crucial task in increasing productivity for both the readers and producers of news. This task can easily be aided by automated News headline-generation models. However, the presence of irrelevant headlines in scraped news articles results in sub-optimal performance of generation models. We propose that relevance-based headline classification can greatly aid the task of generating relevant headlines. Relevance-based headline classification involves categorizing news headlines based on their relevance to the corresponding news articles. While this task is well-established in English, it remains under-explored in low-resource languages like Telugu due to a lack of annotated data. To address this gap, we present TeClass, the first-ever human-annotated Telugu news headline classification dataset, containing 78,534 annotations across 26,178 article-headline pairs. We experiment with various baseline models and provide a comprehensive analysis of their results. We further demonstrate the impact of this work by fine-tuning various headline generation models using TeClass dataset. The headlines generated by the models fine-tuned on highly relevant article-headline pairs, showed about a 5 point increment in the ROUGE-L scores. To encourage future research, the annotated dataset as well as the annotation guidelines will be made publicly available.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
Unsupervised Approach to Evaluate Sentence-Level Fluency: Do We Really Need Reference?
Dec 03, 2023



Fluency is a crucial goal of all Natural Language Generation (NLG) systems. Widely used automatic evaluation metrics fall short in capturing the fluency of machine-generated text. Assessing the fluency of NLG systems poses a challenge since these models are not limited to simply reusing words from the input but may also generate abstractions. Existing reference-based fluency evaluations, such as word overlap measures, often exhibit weak correlations with human judgments. This paper adapts an existing unsupervised technique for measuring text fluency without the need for any reference. Our approach leverages various word embeddings and trains language models using Recurrent Neural Network (RNN) architectures. We also experiment with other available multilingual Language Models (LMs). To assess the performance of the models, we conduct a comparative analysis across 10 Indic languages, correlating the obtained fluency scores with human judgments. Our code and human-annotated benchmark test-set for fluency is available at https://github.com/AnanyaCoder/TextFluencyForIndicLanaguges.
Mukhyansh: A Headline Generation Dataset for Indic Languages
Nov 29, 2023



The task of headline generation within the realm of Natural Language Processing (NLP) holds immense significance, as it strives to distill the true essence of textual content into concise and attention-grabbing summaries. While noteworthy progress has been made in headline generation for widely spoken languages like English, there persist numerous challenges when it comes to generating headlines in low-resource languages, such as the rich and diverse Indian languages. A prominent obstacle that specifically hinders headline generation in Indian languages is the scarcity of high-quality annotated data. To address this crucial gap, we proudly present Mukhyansh, an extensive multilingual dataset, tailored for Indian language headline generation. Comprising an impressive collection of over 3.39 million article-headline pairs, Mukhyansh spans across eight prominent Indian languages, namely Telugu, Tamil, Kannada, Malayalam, Hindi, Bengali, Marathi, and Gujarati. We present a comprehensive evaluation of several state-of-the-art baseline models. Additionally, through an empirical analysis of existing works, we demonstrate that Mukhyansh outperforms all other models, achieving an impressive average ROUGE-L score of 31.43 across all 8 languages.