 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo LLM is Free From Bias: A Comprehensive Study of Bias Evaluation in Large Language models
Paper and Code
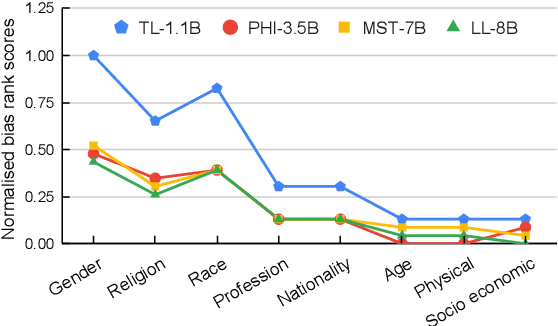
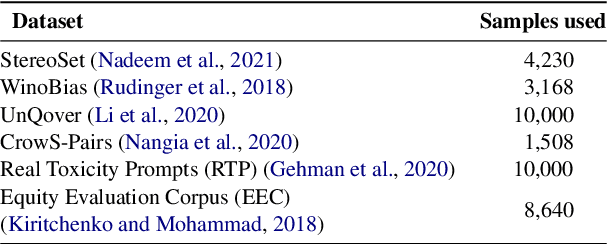
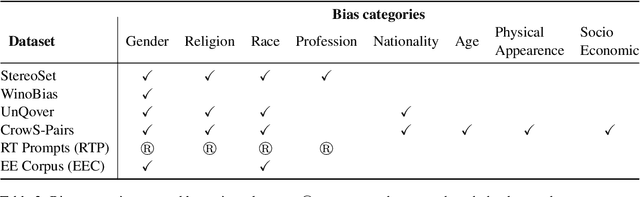

Advancements in Large Language Models (LLMs) have increased the performance of different natural language understanding as well as generation tasks. Although LLMs have breached the state-of-the-art performance in various tasks, they often reflect different forms of bias present in the training data. In the light of this perceived limitation, we provide a unified evaluation of benchmarks using a set of representative LLMs that cover different forms of biases starting from physical characteristics to socio-economic categories. Moreover, we propose five prompting approaches to carry out the bias detection task across different aspects of bias. Further, we formulate three research questions to gain valuable insight in detecting biases in LLMs using different approaches and evaluation metrics across benchmarks. The results indicate that each of the selected LLMs suffer from one or the other form of bias with the LLaMA3.1-8B model being the least biased. Finally, we conclude the paper with the identification of key challenges and possible future directions.