 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Safety-Aligned Intelligence via Differentiable Internal Alignment Embeddings
Dec 20, 2025We introduce Embedded Safety-Aligned Intelligence (ESAI), a theoretical framework for multi-agent reinforcement learning that embeds alignment constraints directly into agents internal representations using differentiable internal alignment embeddings. Unlike external reward shaping or post-hoc safety constraints, internal alignment embeddings are learned latent variables that predict externalized harm through counterfactual reasoning and modulate policy updates toward harm reduction through attention and graph-based propagation. The ESAI framework integrates four mechanisms: differentiable counterfactual alignment penalties computed from soft reference distributions, alignment-weighted perceptual attention, Hebbian associative memory supporting temporal credit assignment, and similarity-weighted graph diffusion with bias mitigation controls. We analyze stability conditions for bounded internal embeddings under Lipschitz continuity and spectral constraints, discuss computational complexity, and examine theoretical properties including contraction behavior and fairness-performance tradeoffs. This work positions ESAI as a conceptual contribution to differentiable alignment mechanisms in multi-agent systems. We identify open theoretical questions regarding convergence guarantees, embedding dimensionality, and extension to high-dimensional environments. Empirical evaluation is left to future work.
AGIC: Attention-Guided Image Captioning to Improve Caption Relevance
Aug 09, 2025
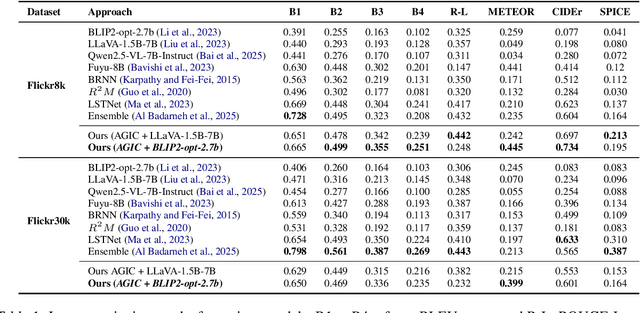
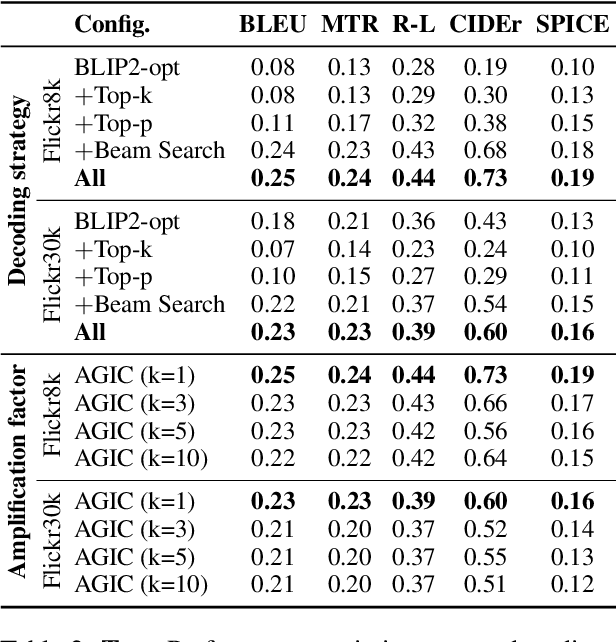
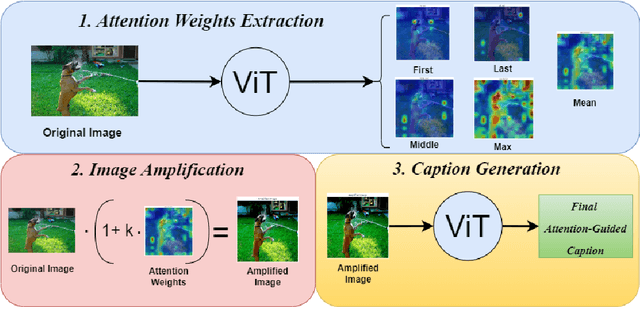
Despite significant progress in image captioning, generating accurate and descriptive captions remains a long-standing challenge. In this study, we propose Attention-Guided Image Captioning (AGIC), which amplifies salient visual regions directly in the feature space to guide caption generation. We further introduce a hybrid decoding strategy that combines deterministic and probabilistic sampling to balance fluency and diversity. To evaluate AGIC, we conduct extensive experiments on the Flickr8k and Flickr30k datasets. The results show that AGIC matches or surpasses several state-of-the-art models while achieving faster inference. Moreover, AGIC demonstrates strong performance across multiple evaluation metrics, offering a scalable and interpretable solution for image captioning.
ILID: Native Script Language Identification for Indian Languages
Jul 16, 2025The language identification task is a crucial fundamental step in NLP. Often it serves as a pre-processing step for widely used NLP applications such as multilingual machine translation, information retrieval, question and answering, and text summarization. The core challenge of language identification lies in distinguishing languages in noisy, short, and code-mixed environments. This becomes even harder in case of diverse Indian languages that exhibit lexical and phonetic similarities, but have distinct differences. Many Indian languages share the same script making the task even more challenging. In this paper, we release a dataset of 230K sentences consisting of English and all 22 official Indian languages labeled with their language identifiers where data in most languages are newly created. We also develop and release robust baseline models using state-of-the-art approaches in machine learning and deep learning that can aid the research in this field. Our baseline models are comparable to the state-of-the-art models for the language identification task.
No LLM is Free From Bias: A Comprehensive Study of Bias Evaluation in Large Language models
Mar 15, 2025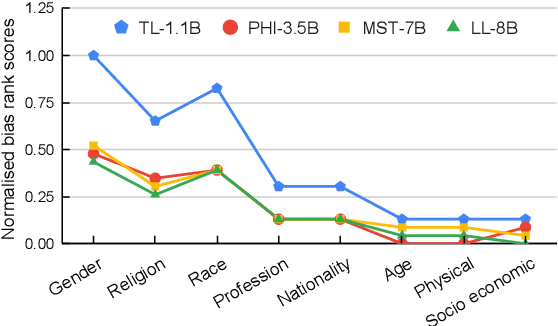
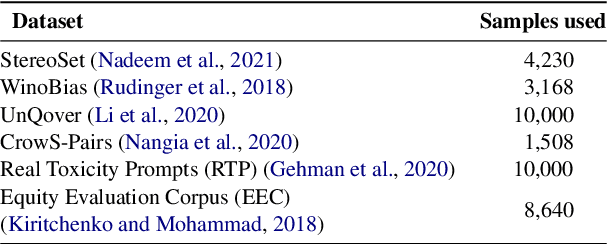
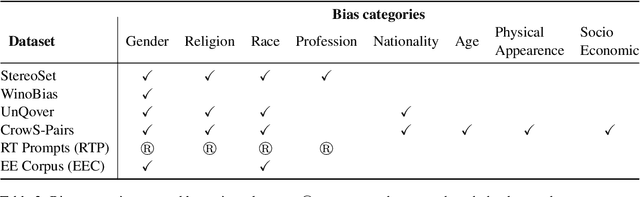

Advancements in Large Language Models (LLMs) have increased the performance of different natural language understanding as well as generation tasks. Although LLMs have breached the state-of-the-art performance in various tasks, they often reflect different forms of bias present in the training data. In the light of this perceived limitation, we provide a unified evaluation of benchmarks using a set of representative LLMs that cover different forms of biases starting from physical characteristics to socio-economic categories. Moreover, we propose five prompting approaches to carry out the bias detection task across different aspects of bias. Further, we formulate three research questions to gain valuable insight in detecting biases in LLMs using different approaches and evaluation metrics across benchmarks. The results indicate that each of the selected LLMs suffer from one or the other form of bias with the LLaMA3.1-8B model being the least biased. Finally, we conclude the paper with the identification of key challenges and possible future directions.
Text2TimeSeries: Enhancing Financial Forecasting through Time Series Prediction Updates with Event-Driven Insights from Large Language Models
Jul 04, 2024



Time series models, typically trained on numerical data, are designed to forecast future values. These models often rely on weighted averaging techniques over time intervals. However, real-world time series data is seldom isolated and is frequently influenced by non-numeric factors. For instance, stock price fluctuations are impacted by daily random events in the broader world, with each event exerting a unique influence on price signals. Previously, forecasts in financial markets have been approached in two main ways: either as time-series problems over price sequence or sentiment analysis tasks. The sentiment analysis tasks aim to determine whether news events will have a positive or negative impact on stock prices, often categorizing them into discrete labels. Recognizing the need for a more comprehensive approach to accurately model time series prediction, we propose a collaborative modeling framework that incorporates textual information about relevant events for predictions. Specifically, we leverage the intuition of large language models about future changes to update real number time series predictions. We evaluated the effectiveness of our approach on financial market data.
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
May 08, 2024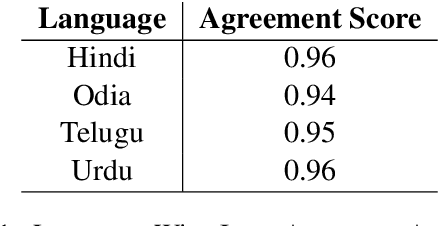
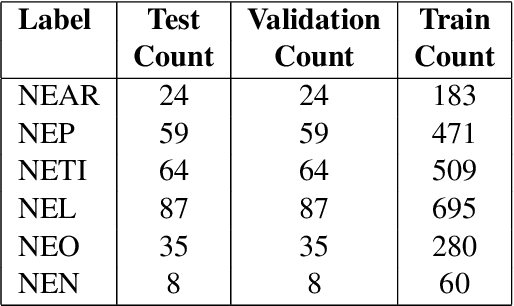
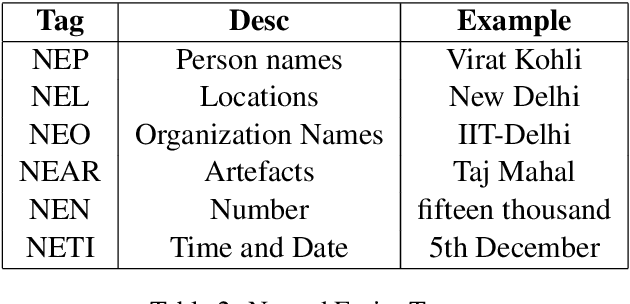
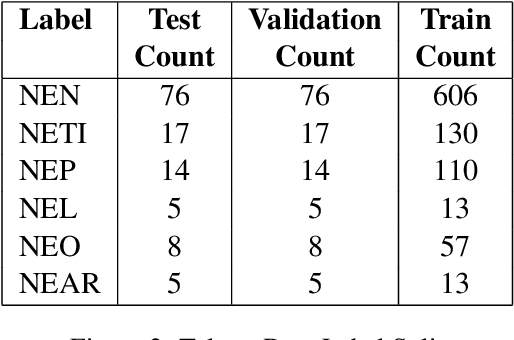
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
Towards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
Apr 03, 2024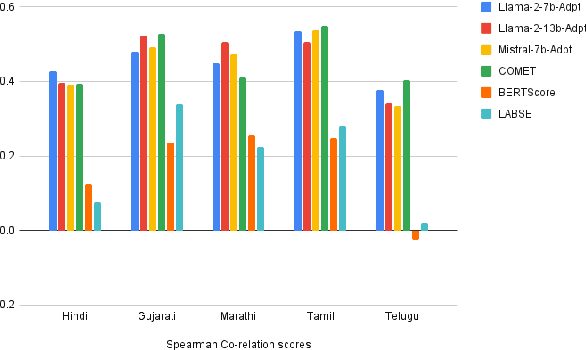
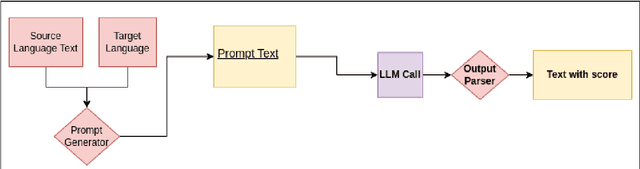
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
Automatic Data Retrieval for Cross Lingual Summarization
Dec 22, 2023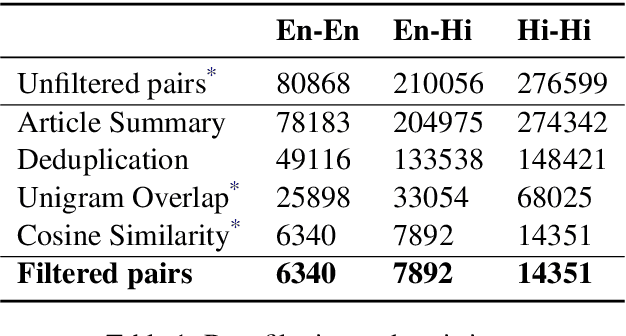
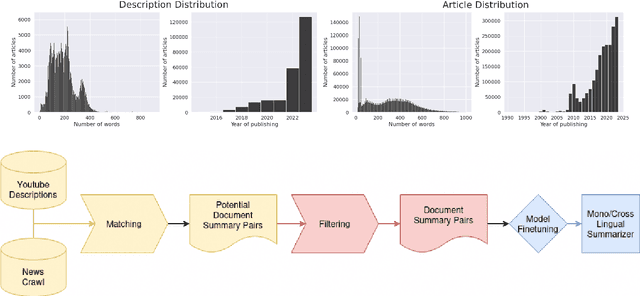
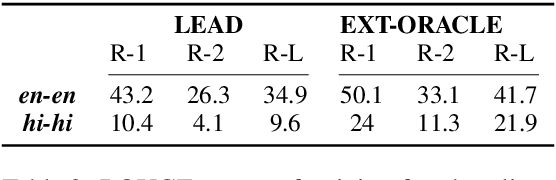
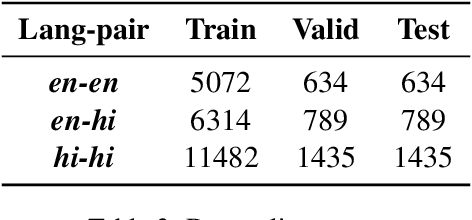
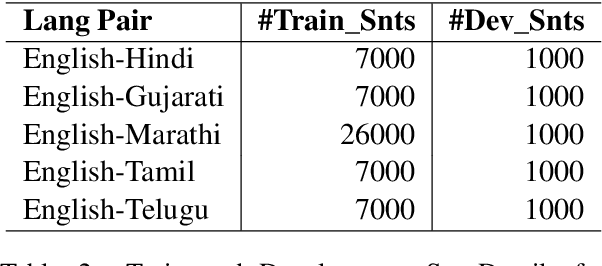
Cross-lingual summarization involves the summarization of text written in one language to a different one. There is a body of research addressing cross-lingual summarization from English to other European languages. In this work, we aim to perform cross-lingual summarization from English to Hindi. We propose pairing up the coverage of newsworthy events in textual and video format can prove to be helpful for data acquisition for cross lingual summarization. We analyze the data and propose methods to match articles to video descriptions that serve as document and summary pairs. We also outline filtering methods over reasonable thresholds to ensure the correctness of the summaries. Further, we make available 28,583 mono and cross-lingual article-summary pairs https://github.com/tingc9/Cross-Sum-News-Aligned. We also build and analyze multiple baselines on the collected data and report error analysis.
Verb Categorisation for Hindi Word Problem Solving
Dec 18, 2023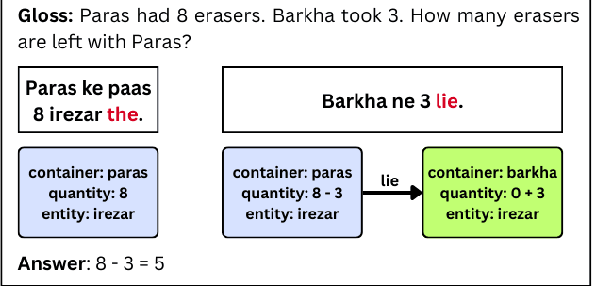



Word problem Solving is a challenging NLP task that deals with solving mathematical problems described in natural language. Recently, there has been renewed interest in developing word problem solvers for Indian languages. As part of this paper, we have built a Hindi arithmetic word problem solver which makes use of verbs. Additionally, we have created verb categorization data for Hindi. Verbs are very important for solving word problems with addition/subtraction operations as they help us identify the set of operations required to solve the word problems. We propose a rule-based solver that uses verb categorisation to identify operations in a word problem and generate answers for it. To perform verb categorisation, we explore several approaches and present a comparative study.
Controllable Text Summarization: Unraveling Challenges, Approaches, and Prospects -- A Survey
Nov 15, 2023



Generic text summarization approaches often fail to address the specific intent and needs of individual users. Recently, scholarly attention has turned to the development of summarization methods that are more closely tailored and controlled to align with specific objectives and user needs. While a growing corpus of research is devoted towards a more controllable summarization, there is no comprehensive survey available that thoroughly explores the diverse controllable aspects or attributes employed in this context, delves into the associated challenges, and investigates the existing solutions. In this survey, we formalize the Controllable Text Summarization (CTS) task, categorize controllable aspects according to their shared characteristics and objectives, and present a thorough examination of existing methods and datasets within each category. Moreover, based on our findings, we uncover limitations and research gaps, while also delving into potential solutions and future directions for CTS.