 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaVerse : Translation Ecosystem for Indian Subcontinent Languages
Dec 05, 2024This paper focuses on developing translation models and related applications for 36 Indian languages, including Assamese, Awadhi, Bengali, Bhojpuri, Braj, Bodo, Dogri, English, Konkani, Gondi, Gujarati, Hindi, Hinglish, Ho, Kannada, Kangri, Kashmiri (Arabic and Devanagari), Khasi, Mizo, Magahi, Maithili, Malayalam, Marathi, Manipuri (Bengali and Meitei), Nepali, Oriya, Punjabi, Sanskrit, Santali, Sinhala, Sindhi (Arabic and Devanagari), Tamil, Tulu, Telugu, and Urdu. Achieving this requires parallel and other types of corpora for all 36 * 36 language pairs, addressing challenges like script variations, phonetic differences, and syntactic diversity. For instance, languages like Kashmiri and Sindhi, which use multiple scripts, demand script normalization for alignment, while low-resource languages such as Khasi and Santali require synthetic data augmentation to ensure sufficient coverage and quality. To address these challenges, this work proposes strategies for corpus creation by leveraging existing resources, developing parallel datasets, generating domain-specific corpora, and utilizing synthetic data techniques. Additionally, it evaluates machine translation across various dimensions, including standard and discourse-level translation, domain-specific translation, reference-based and reference-free evaluation, error analysis, and automatic post-editing. By integrating these elements, the study establishes a comprehensive framework to improve machine translation quality and enable better cross-lingual communication in India's linguistically diverse ecosystem.
Towards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
Apr 03, 2024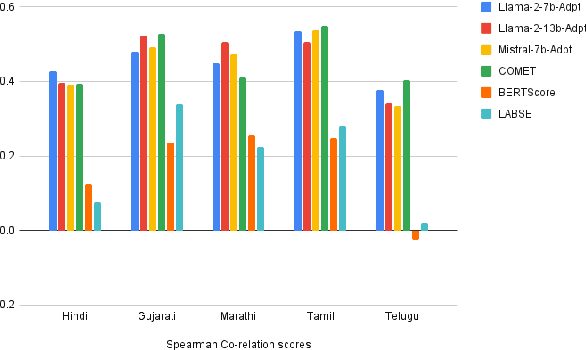
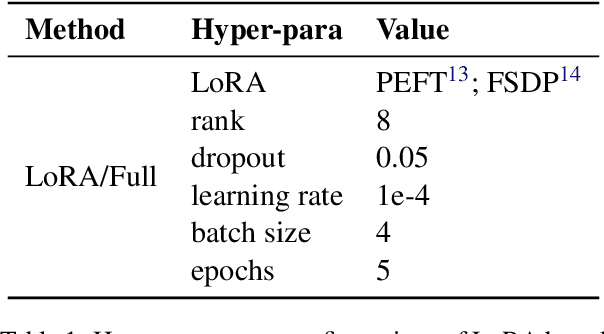
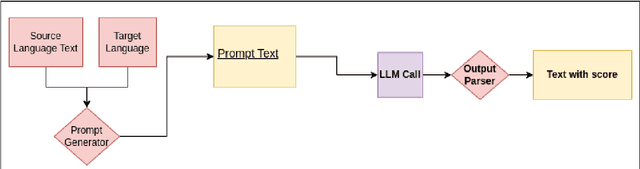
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
Automatic Data Retrieval for Cross Lingual Summarization
Dec 22, 2023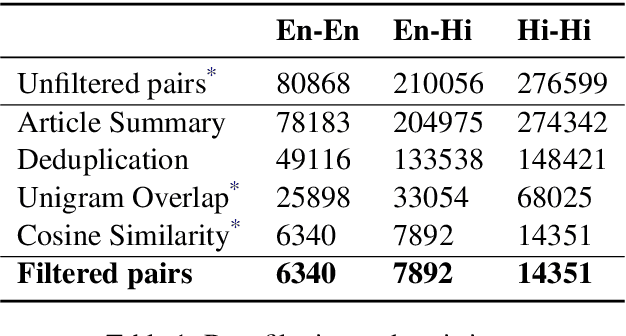
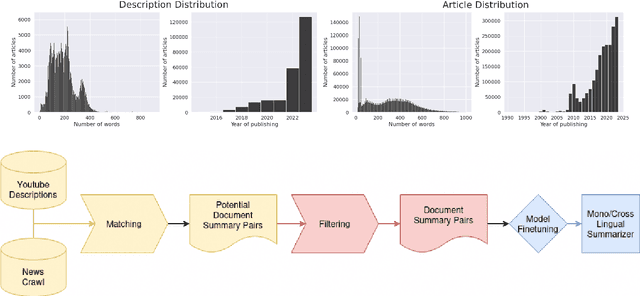
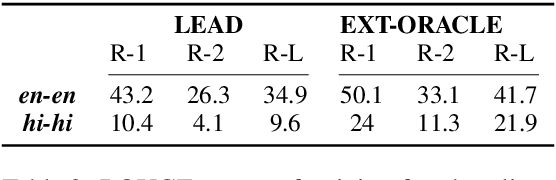
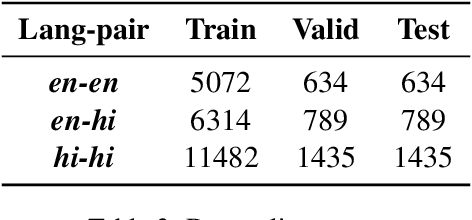
Cross-lingual summarization involves the summarization of text written in one language to a different one. There is a body of research addressing cross-lingual summarization from English to other European languages. In this work, we aim to perform cross-lingual summarization from English to Hindi. We propose pairing up the coverage of newsworthy events in textual and video format can prove to be helpful for data acquisition for cross lingual summarization. We analyze the data and propose methods to match articles to video descriptions that serve as document and summary pairs. We also outline filtering methods over reasonable thresholds to ensure the correctness of the summaries. Further, we make available 28,583 mono and cross-lingual article-summary pairs https://github.com/tingc9/Cross-Sum-News-Aligned. We also build and analyze multiple baselines on the collected data and report error analysis.
Assessing Translation capabilities of Large Language Models involving English and Indian Languages
Nov 15, 2023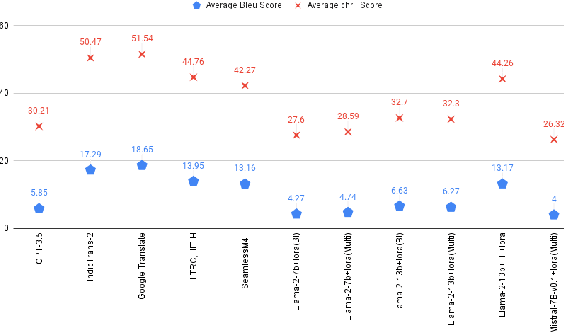

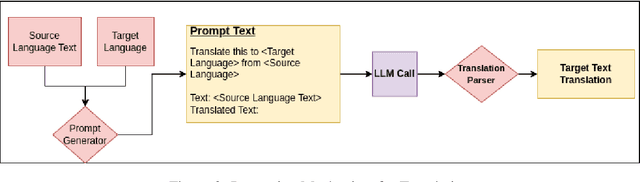
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. In this work, our aim is to explore the multilingual capabilities of large language models by using machine translation as a task involving English and 22 Indian languages. We first investigate the translation capabilities of raw large language models, followed by exploring the in-context learning capabilities of the same raw models. We fine-tune these large language models using parameter efficient fine-tuning methods such as LoRA and additionally with full fine-tuning. Through our study, we have identified the best performing large language model for the translation task involving LLMs, which is based on LLaMA. Our results demonstrate significant progress, with average BLEU scores of 13.42, 15.93, 12.13, 12.30, and 12.07, as well as CHRF scores of 43.98, 46.99, 42.55, 42.42, and 45.39, respectively, using 2-stage fine-tuned LLaMA-13b for English to Indian languages on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Similarly, for Indian languages to English, we achieved average BLEU scores of 14.03, 16.65, 16.17, 15.35 and 12.55 along with chrF scores of 36.71, 40.44, 40.26, 39.51, and 36.20, respectively, using fine-tuned LLaMA-13b on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Overall, our findings highlight the potential and strength of large language models for machine translation capabilities, including for languages that are currently underrepresented in LLMs.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
Assessing Post-editing Effort in the English-Hindi Direction
Dec 18, 2021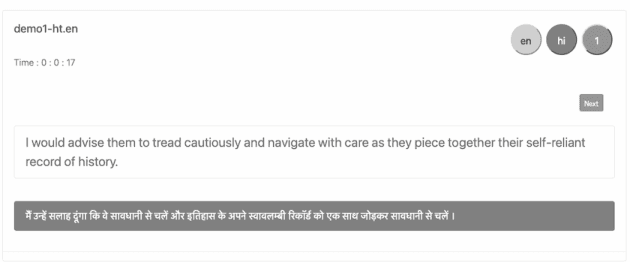
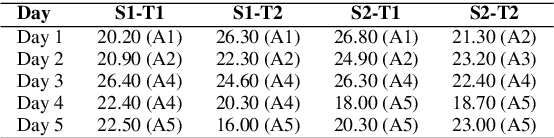
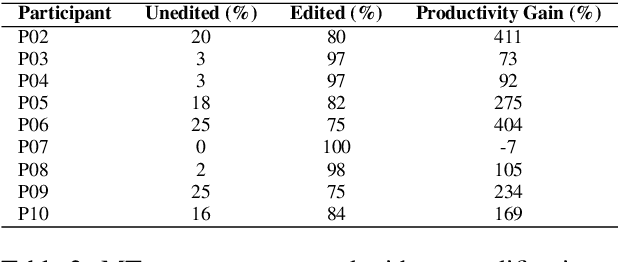
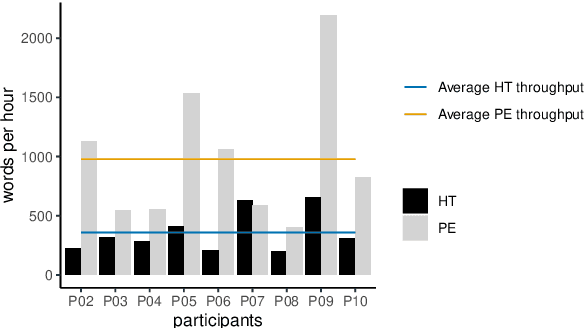
We present findings from a first in-depth post-editing effort estimation study in the English-Hindi direction along multiple effort indicators. We conduct a controlled experiment involving professional translators, who complete assigned tasks alternately, in a translation from scratch and a post-edit condition. We find that post-editing reduces translation time (by 63%), utilizes fewer keystrokes (by 59%), and decreases the number of pauses (by 63%) when compared to translating from scratch. We further verify the quality of translations thus produced via a human evaluation task in which we do not detect any discernible quality differences.