 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinship in Speech: Leveraging Linguistic Relatedness for Zero-Shot TTS in Indian Languages
Jun 04, 2025Text-to-speech (TTS) systems typically require high-quality studio data and accurate transcriptions for training. India has 1369 languages, with 22 official using 13 scripts. Training a TTS system for all these languages, most of which have no digital resources, seems a Herculean task. Our work focuses on zero-shot synthesis, particularly for languages whose scripts and phonotactics come from different families. The novelty of our work is in the augmentation of a shared phone representation and modifying the text parsing rules to match the phonotactics of the target language, thus reducing the synthesiser overhead and enabling rapid adaptation. Intelligible and natural speech was generated for Sanskrit, Maharashtrian and Canara Konkani, Maithili and Kurukh by leveraging linguistic connections across languages with suitable synthesisers. Evaluations confirm the effectiveness of this approach, highlighting its potential to expand speech technology access for under-represented languages.
A Unified Framework for Collecting Text-to-Speech Synthesis Datasets for 22 Indian Languages
Oct 18, 2024



The performance of a text-to-speech (TTS) synthesis model depends on various factors, of which the quality of the training data is of utmost importance. Millions of data are collected around the globe for various languages, but resources for Indian languages are few. Although there are many efforts involved in data collection, a common set of protocols for data collection becomes necessary for building TTS systems in Indian languages primarily because of the need for a uniform development of TTS systems across languages. In this paper, we present our learnings on data collection efforts' for Indic languages over 15 years. These databases have been used in unit selection synthesis, hidden Markov model based, and end-to-end frameworks, and for generating prosodically rich TTS systems. The most significant feature of the data collected is that data purity enables building high-quality TTS systems with a comparatively small dataset compared to that of European/Chinese languages.
Exploring an Inter-Pausal Unit (IPU) based Approach for Indic End-to-End TTS Systems
Sep 18, 2024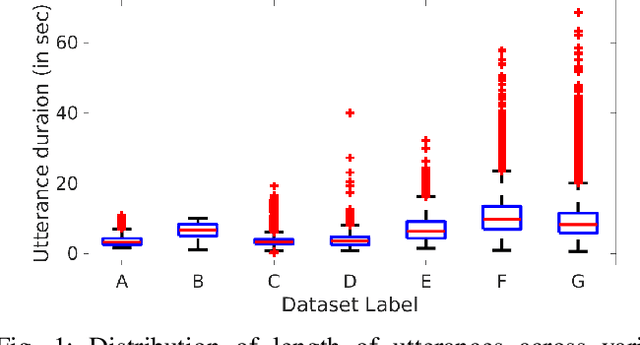
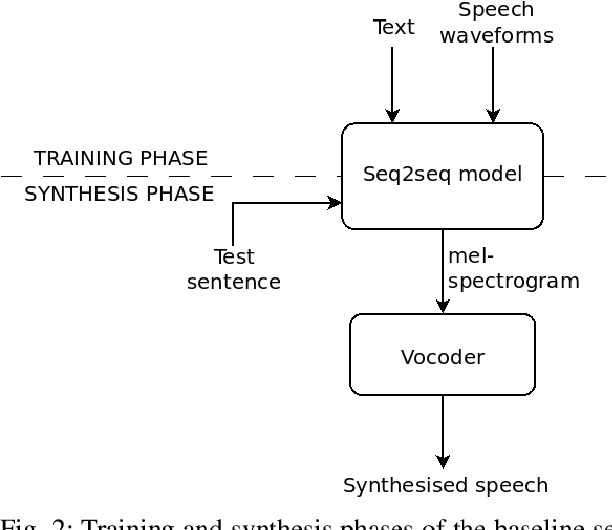
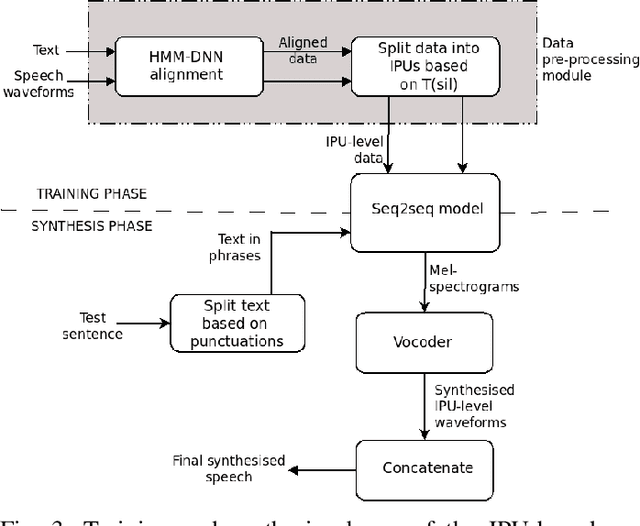
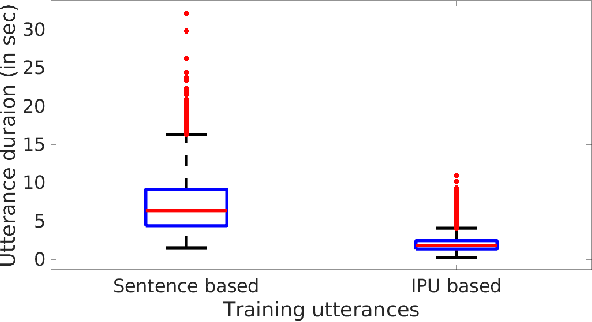
Sentences in Indian languages are generally longer than those in English. Indian languages are also considered to be phrase-based, wherein semantically complete phrases are concatenated to make up sentences. Long utterances lead to poor training of text-to-speech models and result in poor prosody during synthesis. In this work, we explore an inter-pausal unit (IPU) based approach in the end-to-end (E2E) framework, focusing on synthesising conversational-style text. We consider both autoregressive Tacotron2 and non-autoregressive FastSpeech2 architectures in our study and perform experiments with three Indian languages, namely, Hindi, Tamil and Telugu. With the IPU-based Tacotron2 approach, we see a reduction in insertion and deletion errors in the synthesised audio, providing an alternative approach to the FastSpeech(2) network in terms of error reduction. The IPU-based approach requires less computational resources and produces prosodically richer synthesis compared to conventional sentence-based systems.
Fast and small footprint Hybrid HMM-HiFiGAN based system for speech synthesis in Indian languages
Feb 13, 2023



Hidden-Markov-model (HMM) based text-to-speech (HTS) offers flexibility in speaking styles along with fast training and synthesis while being computationally less intense. HTS performs well even in low-resource scenarios. The primary drawback is that the voice quality is poor compared to that of E2E systems. A hybrid approach combining HMM-based feature generation and neural-network-based HiFi-GAN vocoder to improve HTS synthesis quality is proposed. HTS is trained on high-resolution mel-spectrograms instead of conventional mel generalized coefficients (MGC), and the output mel-spectrogram corresponding to the input text is used in a HiFi-GAN vocoder trained on Indic languages, to produce naturalness that is equivalent to that of E2E systems, as evidenced from the DMOS and PC tests.
HMM-based data augmentation for E2E systems for building conversational speech synthesis systems
Dec 22, 2022This paper proposes an approach to build a high-quality text-to-speech (TTS) system for technical domains using data augmentation. An end-to-end (E2E) system is trained on hidden Markov model (HMM) based synthesized speech and further fine-tuned with studio-recorded TTS data to improve the timbre of the synthesized voice. The motivation behind the work is that issues of word skips and repetitions are usually absent in HMM systems due to their ability to model the duration distribution of phonemes accurately. Context-dependent pentaphone modeling, along with tree-based clustering and state-tying, takes care of unseen context and out-of-vocabulary words. A language model is also employed to reduce synthesis errors further. Subjective evaluations indicate that speech produced using the proposed system is superior to the baseline E2E synthesis approach in terms of intelligibility when combining complementing attributes from HMM and E2E frameworks. The further analysis highlights the proposed approach's efficacy in low-resource scenarios.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
The Importance of Accurate Alignments in End-to-End Speech Synthesis
Oct 31, 2022Unit selection synthesis systems required accurate segmentation and labeling of the speech signal owing to the concatenative nature. Hidden Markov model-based speech synthesis accommodates some transcription errors, but it was later shown that accurate transcriptions yield highly intelligible speech with smaller amounts of training data. With the arrival of end-to-end (E2E) systems, it was observed that very good quality speech could be synthesised with large amounts of data. As end-to-end synthesis progressed from Tacotron to FastSpeech2, it has become imminent that features that represent prosody are important for good-quality synthesis. In particular, durations of the sub-word units are important. Variants of FastSpeech use a teacher model or forced alignments to obtain good-quality synthesis. In this paper, we focus on duration prediction, using signal processing cues in tandem with forced alignment to produce accurate phone durations during training. The current work aims to highlight the importance of accurate alignments for good-quality synthesis. An attempt is made to train the E2E systems with accurately labeled data, and compare the same with approximately labeled data.
Dual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021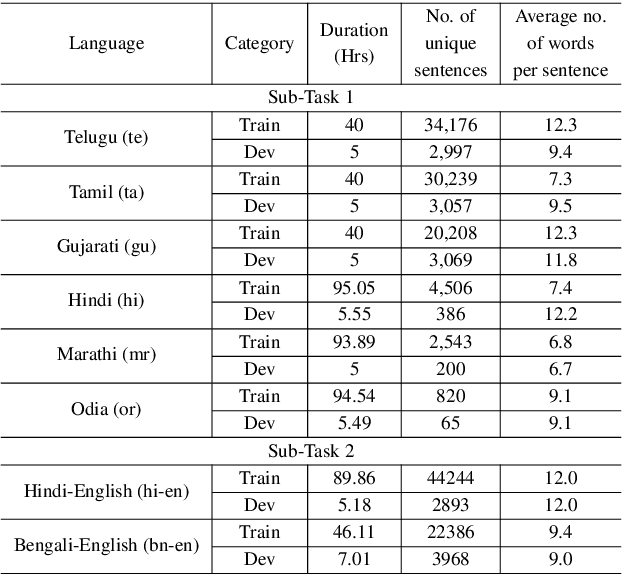
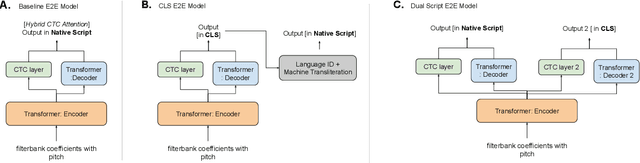
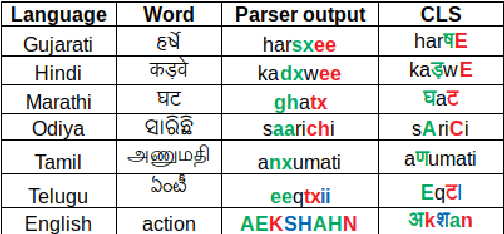
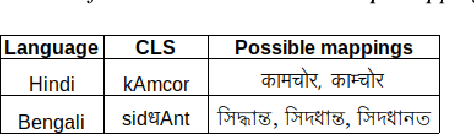
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.
Multi-Relational Question Answering from Narratives: Machine Reading and Reasoning in Simulated Worlds
Feb 25, 2019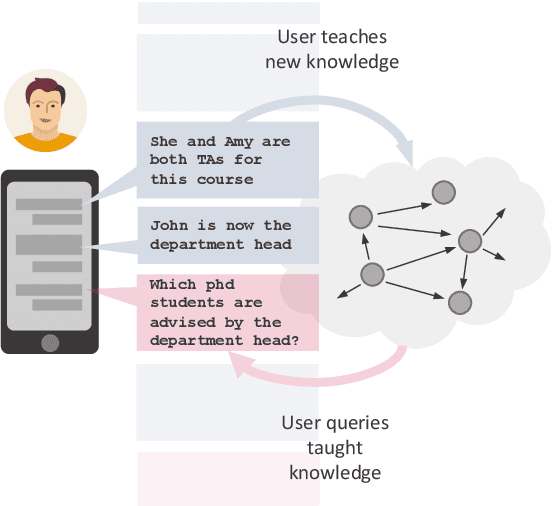
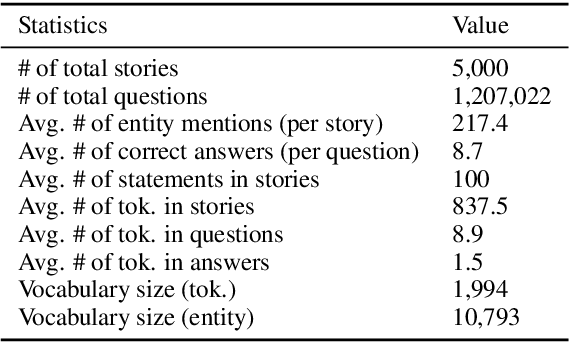

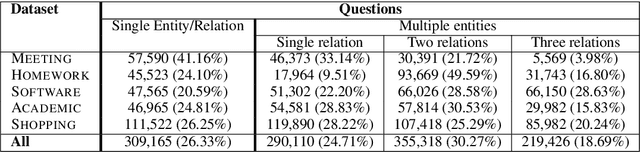
Question Answering (QA), as a research field, has primarily focused on either knowledge bases (KBs) or free text as a source of knowledge. These two sources have historically shaped the kinds of questions that are asked over these sources, and the methods developed to answer them. In this work, we look towards a practical use-case of QA over user-instructed knowledge that uniquely combines elements of both structured QA over knowledge bases, and unstructured QA over narrative, introducing the task of multi-relational QA over personal narrative. As a first step towards this goal, we make three key contributions: (i) we generate and release TextWorldsQA, a set of five diverse datasets, where each dataset contains dynamic narrative that describes entities and relations in a simulated world, paired with variably compositional questions over that knowledge, (ii) we perform a thorough evaluation and analysis of several state-of-the-art QA models and their variants at this task, and (iii) we release a lightweight Python-based framework we call TextWorlds for easily generating arbitrary additional worlds and narrative, with the goal of allowing the community to create and share a growing collection of diverse worlds as a test-bed for this task.
* published at ACL 2018