 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook-up and Adapt: A One-shot Semantic Parser
Oct 27, 2019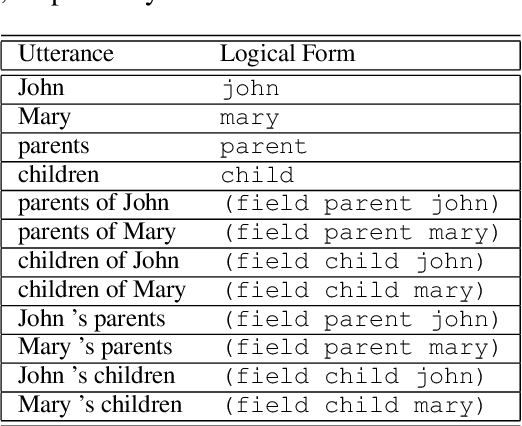
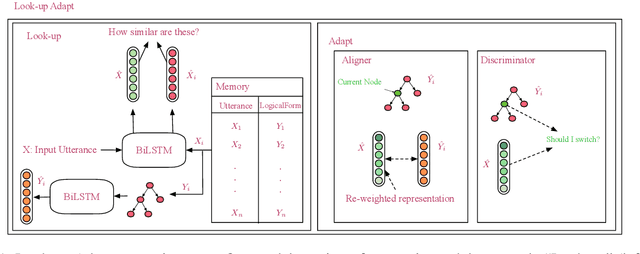
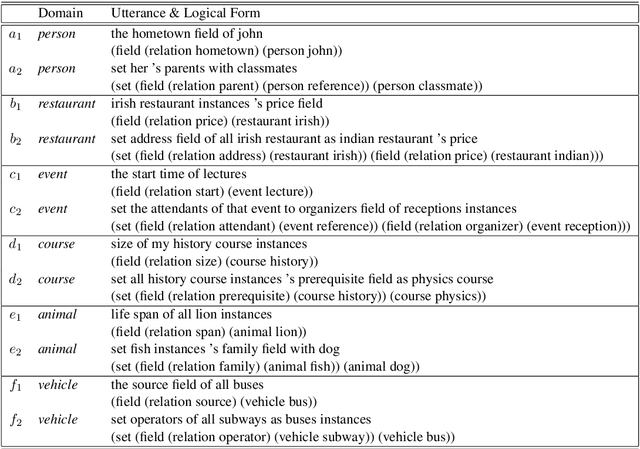
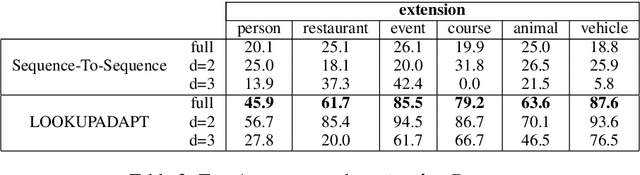
Computing devices have recently become capable of interacting with their end users via natural language. However, they can only operate within a limited "supported" domain of discourse and fail drastically when faced with an out-of-domain utterance, mainly due to the limitations of their semantic parser. In this paper, we propose a semantic parser that generalizes to out-of-domain examples by learning a general strategy for parsing an unseen utterance through adapting the logical forms of seen utterances, instead of learning to generate a logical form from scratch. Our parser maintains a memory consisting of a representative subset of the seen utterances paired with their logical forms. Given an unseen utterance, our parser works by looking up a similar utterance from the memory and adapting its logical form until it fits the unseen utterance. Moreover, we present a data generation strategy for constructing utterance-logical form pairs from different domains. Our results show an improvement of up to 68.8% on one-shot parsing under two different evaluation settings compared to the baselines.
Multi-Relational Question Answering from Narratives: Machine Reading and Reasoning in Simulated Worlds
Feb 25, 2019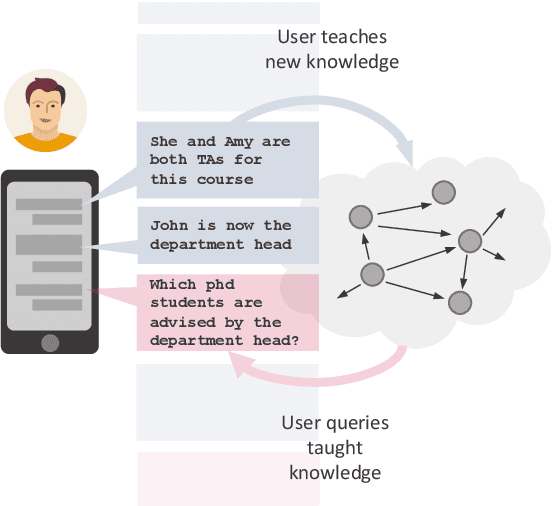
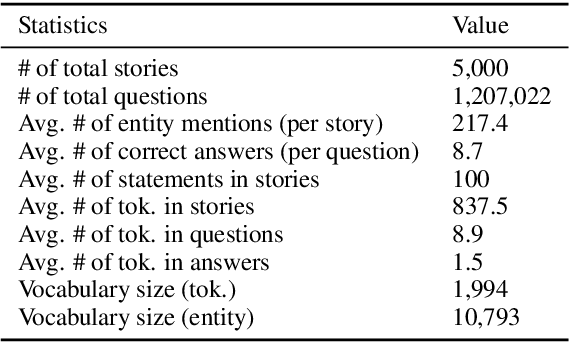

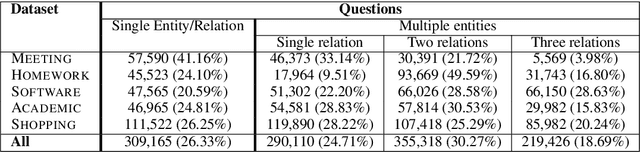
Question Answering (QA), as a research field, has primarily focused on either knowledge bases (KBs) or free text as a source of knowledge. These two sources have historically shaped the kinds of questions that are asked over these sources, and the methods developed to answer them. In this work, we look towards a practical use-case of QA over user-instructed knowledge that uniquely combines elements of both structured QA over knowledge bases, and unstructured QA over narrative, introducing the task of multi-relational QA over personal narrative. As a first step towards this goal, we make three key contributions: (i) we generate and release TextWorldsQA, a set of five diverse datasets, where each dataset contains dynamic narrative that describes entities and relations in a simulated world, paired with variably compositional questions over that knowledge, (ii) we perform a thorough evaluation and analysis of several state-of-the-art QA models and their variants at this task, and (iii) we release a lightweight Python-based framework we call TextWorlds for easily generating arbitrary additional worlds and narrative, with the goal of allowing the community to create and share a growing collection of diverse worlds as a test-bed for this task.
* published at ACL 2018
Learning to Learn Semantic Parsers from Natural Language Supervision
Feb 22, 2019


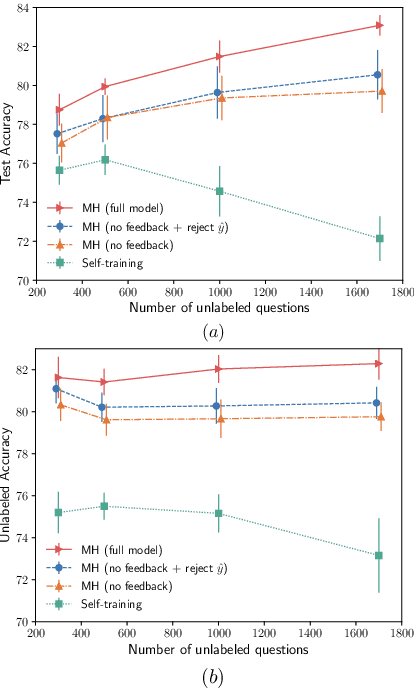
As humans, we often rely on language to learn language. For example, when corrected in a conversation, we may learn from that correction, over time improving our language fluency. Inspired by this observation, we propose a learning algorithm for training semantic parsers from supervision (feedback) expressed in natural language. Our algorithm learns a semantic parser from users' corrections such as "no, what I really meant was before his job, not after", by also simultaneously learning to parse this natural language feedback in order to leverage it as a form of supervision. Unlike supervision with gold-standard logical forms, our method does not require the user to be familiar with the underlying logical formalism, and unlike supervision from denotation, it does not require the user to know the correct answer to their query. This makes our learning algorithm naturally scalable in settings where existing conversational logs are available and can be leveraged as training data. We construct a novel dataset of natural language feedback in a conversational setting, and show that our method is effective at learning a semantic parser from such natural language supervision.
Unbounded Human Learning: Optimal Scheduling for Spaced Repetition
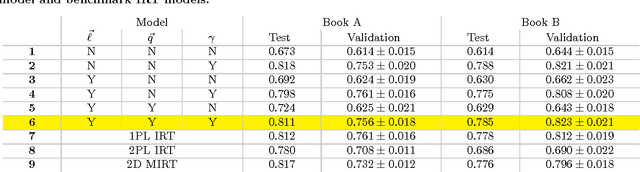
Jun 08, 2016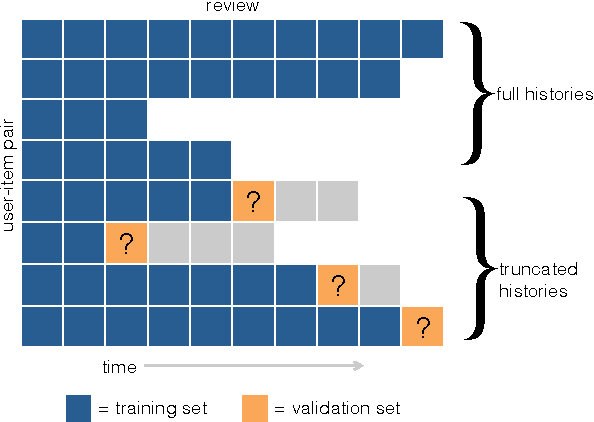

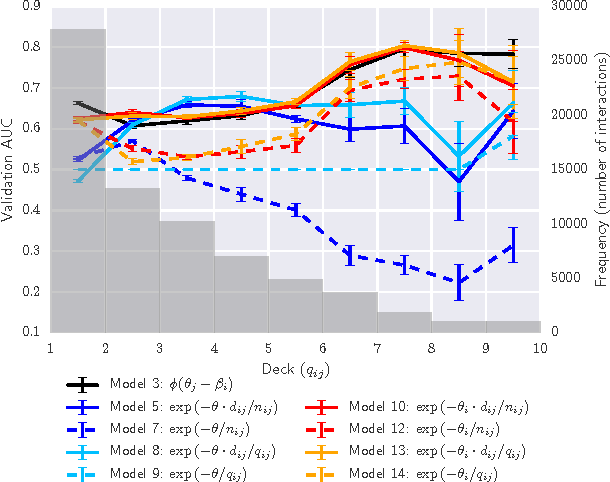
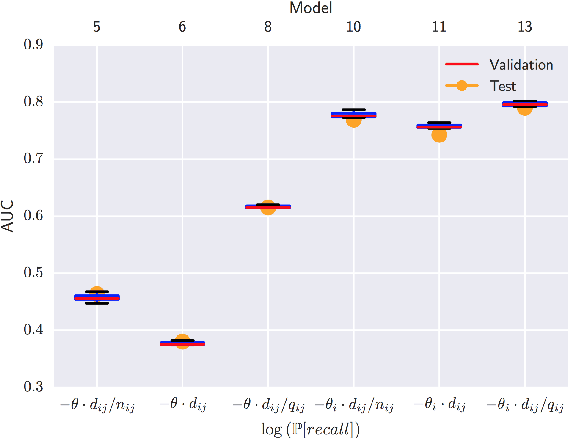
In the study of human learning, there is broad evidence that our ability to retain information improves with repeated exposure and decays with delay since last exposure. This plays a crucial role in the design of educational software, leading to a trade-off between teaching new material and reviewing what has already been taught. A common way to balance this trade-off is spaced repetition, which uses periodic review of content to improve long-term retention. Though spaced repetition is widely used in practice, e.g., in electronic flashcard software, there is little formal understanding of the design of these systems. Our paper addresses this gap in three ways. First, we mine log data from spaced repetition software to establish the functional dependence of retention on reinforcement and delay. Second, we use this memory model to develop a stochastic model for spaced repetition systems. We propose a queueing network model of the Leitner system for reviewing flashcards, along with a heuristic approximation that admits a tractable optimization problem for review scheduling. Finally, we empirically evaluate our queueing model through a Mechanical Turk experiment, verifying a key qualitative prediction of our model: the existence of a sharp phase transition in learning outcomes upon increasing the rate of new item introductions.
Latent Skill Embedding for Personalized Lesson Sequence Recommendation
Feb 23, 2016

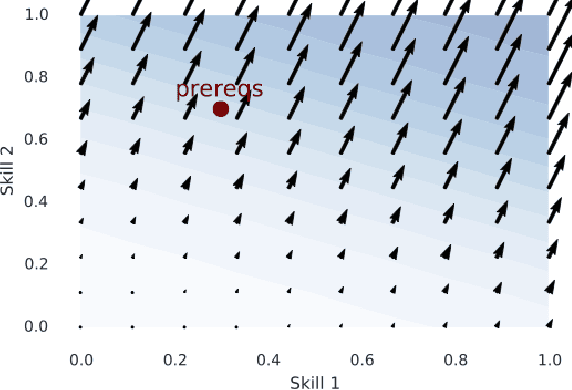
Students in online courses generate large amounts of data that can be used to personalize the learning process and improve quality of education. In this paper, we present the Latent Skill Embedding (LSE), a probabilistic model of students and educational content that can be used to recommend personalized sequences of lessons with the goal of helping students prepare for specific assessments. Akin to collaborative filtering for recommender systems, the algorithm does not require students or content to be described by features, but it learns a representation using access traces. We formulate this problem as a regularized maximum-likelihood embedding of students, lessons, and assessments from historical student-content interactions. An empirical evaluation on large-scale data from Knewton, an adaptive learning technology company, shows that this approach predicts assessment results competitively with benchmark models and is able to discriminate between lesson sequences that lead to mastery and failure.