 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: Learning and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding
Mar 10, 2026LM-based agents excel when given high-level action APIs but struggle to ground language into low-level control. Prior work has LLMs generate skills or reward functions for RL, but these one-shot approaches lack feedback to correct specification errors. We introduce SCALAR, a bidirectional framework coupling LLM planning with RL through a learned skill library. The LLM proposes skills with preconditions and effects; RL trains policies for each skill and feeds back execution results to iteratively refine specifications, improving robustness to initial errors. Pivotal Trajectory Analysis corrects LLM priors by analyzing RL trajectories; Frontier Checkpointing optionally saves environment states at skill boundaries to improve sample efficiency. On Craftax, SCALAR achieves 88.2% diamond collection, a 1.9x improvement over the best baseline, and reaches the Gnomish Mines 9.1% of the time where prior methods fail entirely.
Towards Reliable Benchmarking: A Contamination Free, Controllable Evaluation Framework for Multi-step LLM Function Calling
Sep 30, 2025
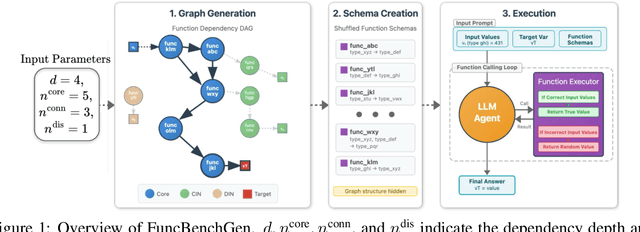
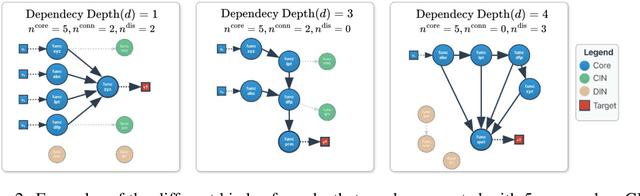

As language models gain access to external tools via structured function calls, they become increasingly more capable of solving complex, multi-step tasks. However, existing benchmarks for tool-augmented language models (TaLMs) provide insufficient control over factors such as the number of functions accessible, task complexity, and input size, and remain vulnerable to data contamination. We present FuncBenchGen, a unified, contamination-free framework that evaluates TaLMs by generating synthetic multi-step tool-use tasks. The key idea is to cast tool use as traversal over a hidden function-dependency DAG where nodes are function calls and an edge between nodes represents one function consuming the output of another. Given a set of external function schemas, initial variable values, and a target variable, models must compose the correct call sequence to compute the target variable. FuncBenchGen allows users to precisely control task difficulty (e.g., graph size, dependency depth, and distractor functions) while avoiding data leakage. We apply our FuncBenchGen framework to evaluate seven LLMs on tool use tasks of varying difficulty. Reasoning-optimized models consistently outperform general-purpose models with GPT-5 significantly outperforming other models. Performance declines sharply as dependency depth increases. Furthermore, connected irrelevant functions prove especially difficult to handle. We find that strong models often make syntactically valid function calls but propagate incorrect or stale argument values across steps, revealing brittle state tracking by LLMs in multi-turn tool use. Motivated by this observation, we introduce a simple mitigation strategy that explicitly restates prior variable values to the agent at each step. Surprisingly, this lightweight change yields substantial gains across models. e.g., yielding a success rate improvement from 62.5% to 81.3% for GPT-5.
Learning to Optimize Feedback for One Million Students: Insights from Multi-Armed and Contextual Bandits in Large-Scale Online Tutoring
Aug 01, 2025We present an online tutoring system that learns to provide effective feedback to students after they answer questions incorrectly. Using data from one million students, the system learns which assistance action (e.g., one of multiple hints) to provide for each question to optimize student learning. Employing the multi-armed bandit (MAB) framework and offline policy evaluation, we assess 43,000 assistance actions, and identify trade-offs between assistance policies optimized for different student outcomes (e.g., response correctness, session completion). We design an algorithm that for each question decides on a suitable policy training objective to enhance students' immediate second attempt success and overall practice session performance. We evaluate the resulting MAB policies in 166,000 practice sessions, verifying significant improvements in student outcomes. While MAB policies optimize feedback for the overall student population, we further investigate whether contextual bandit (CB) policies can enhance outcomes by personalizing feedback based on individual student features (e.g., ability estimates, response times). Using causal inference, we examine (i) how effects of assistance actions vary across students and (ii) whether CB policies, which leverage such effect heterogeneity, outperform MAB policies. While our analysis reveals that some actions for some questions exhibit effect heterogeneity, effect sizes may often be too small for CB policies to provide significant improvements beyond what well-optimized MAB policies that deliver the same action to all students already achieve. We discuss insights gained from deploying data-driven systems at scale and implications for future refinements. Today, the teaching policies optimized by our system support thousands of students daily.
Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions
May 30, 2024
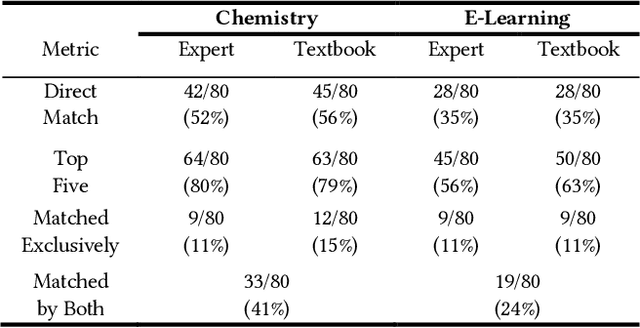


Knowledge Components (KCs) linked to assessments enhance the measurement of student learning, enrich analytics, and facilitate adaptivity. However, generating and linking KCs to assessment items requires significant effort and domain-specific knowledge. To streamline this process for higher-education courses, we employed GPT-4 to generate KCs for multiple-choice questions (MCQs) in Chemistry and E-Learning. We analyzed discrepancies between the KCs generated by the Large Language Model (LLM) and those made by humans through evaluation from three domain experts in each subject area. This evaluation aimed to determine whether, in instances of non-matching KCs, evaluators showed a preference for the LLM-generated KCs over their human-created counterparts. We also developed an ontology induction algorithm to cluster questions that assess similar KCs based on their content. Our most effective LLM strategy accurately matched KCs for 56% of Chemistry and 35% of E-Learning MCQs, with even higher success when considering the top five KC suggestions. Human evaluators favored LLM-generated KCs, choosing them over human-assigned ones approximately two-thirds of the time, a preference that was statistically significant across both domains. Our clustering algorithm successfully grouped questions by their underlying KCs without needing explicit labels or contextual information. This research advances the automation of KC generation and classification for assessment items, alleviating the need for student data or predefined KC labels.
Ruffle&Riley: Insights from Designing and Evaluating a Large Language Model-Based Conversational Tutoring System
Apr 26, 2024Conversational tutoring systems (CTSs) offer learning experiences through interactions based on natural language. They are recognized for promoting cognitive engagement and improving learning outcomes, especially in reasoning tasks. Nonetheless, the cost associated with authoring CTS content is a major obstacle to widespread adoption and to research on effective instructional design. In this paper, we discuss and evaluate a novel type of CTS that leverages recent advances in large language models (LLMs) in two ways: First, the system enables AI-assisted content authoring by inducing an easily editable tutoring script automatically from a lesson text. Second, the system automates the script orchestration in a learning-by-teaching format via two LLM-based agents (Ruffle&Riley) acting as a student and a professor. The system allows for free-form conversations that follow the ITS-typical inner and outer loop structure. We evaluate Ruffle&Riley's ability to support biology lessons in two between-subject online user studies (N = 200) comparing the system to simpler QA chatbots and reading activity. Analyzing system usage patterns, pre/post-test scores and user experience surveys, we find that Ruffle&Riley users report high levels of engagement, understanding and perceive the offered support as helpful. Even though Ruffle&Riley users require more time to complete the activity, we did not find significant differences in short-term learning gains over the reading activity. Our system architecture and user study provide various insights for designers of future CTSs. We further open-source our system to support ongoing research on effective instructional design of LLM-based learning technologies.
AgentKit: Flow Engineering with Graphs, not Coding
Apr 17, 2024



We propose an intuitive LLM prompting framework (AgentKit) for multifunctional agents. AgentKit offers a unified framework for explicitly constructing a complex "thought process" from simple natural language prompts. The basic building block in AgentKit is a node, containing a natural language prompt for a specific subtask. The user then puts together chains of nodes, like stacking LEGO pieces. The chains of nodes can be designed to explicitly enforce a naturally structured "thought process". For example, for the task of writing a paper, one may start with the thought process of 1) identify a core message, 2) identify prior research gaps, etc. The nodes in AgentKit can be designed and combined in different ways to implement multiple advanced capabilities including on-the-fly hierarchical planning, reflection, and learning from interactions. In addition, due to the modular nature and the intuitive design to simulate explicit human thought process, a basic agent could be implemented as simple as a list of prompts for the subtasks and therefore could be designed and tuned by someone without any programming experience. Quantitatively, we show that agents designed through AgentKit achieve SOTA performance on WebShop and Crafter. These advances underscore AgentKit's potential in making LLM agents effective and accessible for a wider range of applications. https://github.com/holmeswww/AgentKit
Reasoning Capacity in Multi-Agent Systems: Limitations, Challenges and Human-Centered Solutions
Feb 02, 2024Remarkable performance of large language models (LLMs) in a variety of tasks brings forth many opportunities as well as challenges of utilizing them in production settings. Towards practical adoption of LLMs, multi-agent systems hold great promise to augment, integrate, and orchestrate LLMs in the larger context of enterprise platforms that use existing proprietary data and models to tackle complex real-world tasks. Despite the tremendous success of these systems, current approaches rely on narrow, single-focus objectives for optimization and evaluation, often overlooking potential constraints in real-world scenarios, including restricted budgets, resources and time. Furthermore, interpreting, analyzing, and debugging these systems requires different components to be evaluated in relation to one another. This demand is currently not feasible with existing methodologies. In this postion paper, we introduce the concept of reasoning capacity as a unifying criterion to enable integration of constraints during optimization and establish connections among different components within the system, which also enable a more holistic and comprehensive approach to evaluation. We present a formal definition of reasoning capacity and illustrate its utility in identifying limitations within each component of the system. We then argue how these limitations can be addressed with a self-reflective process wherein human-feedback is used to alleviate shortcomings in reasoning and enhance overall consistency of the system.
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning
May 24, 2023Open-world survival games pose significant challenges for AI algorithms due to their multi-tasking, deep exploration, and goal prioritization requirements. Despite reinforcement learning (RL) being popular for solving games, its high sample complexity limits its effectiveness in complex open-world games like Crafter or Minecraft. We propose a novel approach, SPRING, to read the game's original academic paper and use the knowledge learned to reason and play the game through a large language model (LLM). Prompted with the LaTeX source as game context and a description of the agent's current observation, our SPRING framework employs a directed acyclic graph (DAG) with game-related questions as nodes and dependencies as edges. We identify the optimal action to take in the environment by traversing the DAG and calculating LLM responses for each node in topological order, with the LLM's answer to final node directly translating to environment actions. In our experiments, we study the quality of in-context "reasoning" induced by different forms of prompts under the setting of the Crafter open-world environment. Our experiments suggest that LLMs, when prompted with consistent chain-of-thought, have great potential in completing sophisticated high-level trajectories. Quantitatively, SPRING with GPT-4 outperforms all state-of-the-art RL baselines, trained for 1M steps, without any training. Finally, we show the potential of games as a test bed for LLMs.
Plan, Eliminate, and Track -- Language Models are Good Teachers for Embodied Agents
May 07, 2023Pre-trained large language models (LLMs) capture procedural knowledge about the world. Recent work has leveraged LLM's ability to generate abstract plans to simplify challenging control tasks, either by action scoring, or action modeling (fine-tuning). However, the transformer architecture inherits several constraints that make it difficult for the LLM to directly serve as the agent: e.g. limited input lengths, fine-tuning inefficiency, bias from pre-training, and incompatibility with non-text environments. To maintain compatibility with a low-level trainable actor, we propose to instead use the knowledge in LLMs to simplify the control problem, rather than solving it. We propose the Plan, Eliminate, and Track (PET) framework. The Plan module translates a task description into a list of high-level sub-tasks. The Eliminate module masks out irrelevant objects and receptacles from the observation for the current sub-task. Finally, the Track module determines whether the agent has accomplished each sub-task. On the AlfWorld instruction following benchmark, the PET framework leads to a significant 15% improvement over SOTA for generalization to human goal specifications.
The Internal State of an LLM Knows When its Lying
Apr 26, 2023While Large Language Models (LLMs) have shown exceptional performance in various tasks, their (arguably) most prominent drawback is generating inaccurate or false information with a confident tone. In this paper, we hypothesize that the LLM's internal state can be used to reveal the truthfulness of a statement. Therefore, we introduce a simple yet effective method to detect the truthfulness of LLM-generated statements, which utilizes the LLM's hidden layer activations to determine the veracity of statements. To train and evaluate our method, we compose a dataset of true and false statements in six different topics. A classifier is trained to detect which statement is true or false based on an LLM's activation values. Specifically, the classifier receives as input the activation values from the LLM for each of the statements in the dataset. Our experiments demonstrate that our method for detecting statement veracity significantly outperforms even few-shot prompting methods, highlighting its potential to enhance the reliability of LLM-generated content and its practical applicability in real-world scenarios.