 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming GenAI Policy to Prompting Instruction: An RCT of Scalable Prompting Interventions in a CS1 Course
Feb 17, 2026Despite universal GenAI adoption, students cannot distinguish task performance from actual learning and lack skills to leverage AI for learning, leading to worse exam performance when AI use remains unreflective. Yet few interventions teaching students to prompt AI as a tutor rather than solution provider have been validated at scale through randomized controlled trials (RCTs). To bridge this gap, we conducted a semester-long RCT (N=979) with four ICAP framework-based instructional conditions varying in engagement intensity with a pre-test, immediate and delayed post-test and surveys. Mixed methods analysis results showed: (1) All conditions significantly improved prompting skills, with gains increasing progressively from Condition 1 to Condition 4, validating ICAP's cognitive engagement hierarchy; (2) for students with similar pre-test scores, higher learning gain in immediate post-test predict higher final exam score, though no direct between-group differences emerged; (3) Our interventions are suitable and scalable solutions for diverse educational contexts, resources and learners. Together, this study makes empirical and theoretical contributions: (1) theoretically, we provided one of the first large-scale RCTs examining how cognitive engagement shapes learning in prompting literacy and clarifying the relationship between learning-oriented prompting skills and broader academic performance; (2) empirically, we offered timely design guidance for transforming GenAI classroom policies into scalable, actionable prompting literacy instruction to advance learning in the era of Generative AI.
Generate-Then-Validate: A Novel Question Generation Approach Using Small Language Models
Dec 10, 2025

We explore the use of small language models (SLMs) for automatic question generation as a complement to the prevalent use of their large counterparts in learning analytics research. We present a novel question generation pipeline that leverages both the text generation and the probabilistic reasoning abilities of SLMs to generate high-quality questions. Adopting a "generate-then-validate" strategy, our pipeline first performs expansive generation to create an abundance of candidate questions and refine them through selective validation based on novel probabilistic reasoning. We conducted two evaluation studies, one with seven human experts and the other with a large language model (LLM), to assess the quality of the generated questions. Most judges (humans or LLMs) agreed that the generated questions had clear answers and generally aligned well with the intended learning objectives. Our findings suggest that an SLM can effectively generate high-quality questions when guided by a well-designed pipeline that leverages its strengths.
Improving Student-AI Interaction Through Pedagogical Prompting: An Example in Computer Science Education
Jun 23, 2025
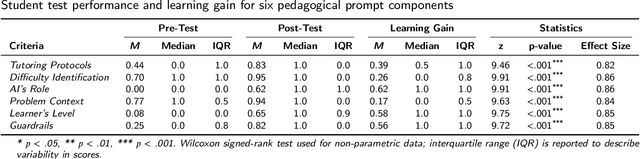


With the proliferation of large language model (LLM) applications since 2022, their use in education has sparked both excitement and concern. Recent studies consistently highlight students' (mis)use of LLMs can hinder learning outcomes. This work aims to teach students how to effectively prompt LLMs to improve their learning. We first proposed pedagogical prompting, a theoretically-grounded new concept to elicit learning-oriented responses from LLMs. To move from concept design to a proof-of-concept learning intervention in real educational settings, we selected early undergraduate CS education (CS1/CS2) as the example context. We began with a formative survey study with instructors (N=36) teaching early-stage undergraduate-level CS courses to inform the instructional design based on classroom needs. Based on their insights, we designed and developed a learning intervention through an interactive system with scenario-based instruction to train pedagogical prompting skills. Finally, we evaluated its instructional effectiveness through a user study with CS novice students (N=22) using pre/post-tests. Through mixed methods analyses, our results indicate significant improvements in learners' LLM-based pedagogical help-seeking skills, along with positive attitudes toward the system and increased willingness to use pedagogical prompts in the future. Our contributions include (1) a theoretical framework of pedagogical prompting; (2) empirical insights into current instructor attitudes toward pedagogical prompting; and (3) a learning intervention design with an interactive learning tool and scenario-based instruction leading to promising results on teaching LLM-based help-seeking. Our approach is scalable for broader implementation in classrooms and has the potential to be integrated into tools like ChatGPT as an on-boarding experience to encourage learning-oriented use of generative AI.
Small but Significant: On the Promise of Small Language Models for Accessible AIED
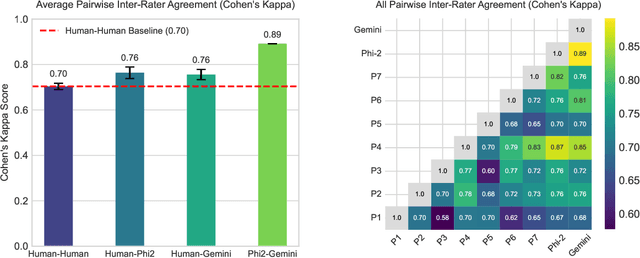
May 13, 2025GPT has become nearly synonymous with large language models (LLMs), an increasingly popular term in AIED proceedings. A simple keyword-based search reveals that 61% of the 76 long and short papers presented at AIED 2024 describe novel solutions using LLMs to address some of the long-standing challenges in education, and 43% specifically mention GPT. Although LLMs pioneered by GPT create exciting opportunities to strengthen the impact of AI on education, we argue that the field's predominant focus on GPT and other resource-intensive LLMs (with more than 10B parameters) risks neglecting the potential impact that small language models (SLMs) can make in providing resource-constrained institutions with equitable and affordable access to high-quality AI tools. Supported by positive results on knowledge component (KC) discovery, a critical challenge in AIED, we demonstrate that SLMs such as Phi-2 can produce an effective solution without elaborate prompting strategies. Hence, we call for more attention to developing SLM-based AIED approaches.
KCluster: An LLM-based Clustering Approach to Knowledge Component Discovery
May 09, 2025Educators evaluate student knowledge using knowledge component (KC) models that map assessment questions to KCs. Still, designing KC models for large question banks remains an insurmountable challenge for instructors who need to analyze each question by hand. The growing use of Generative AI in education is expected only to aggravate this chronic deficiency of expert-designed KC models, as course engineers designing KCs struggle to keep up with the pace at which questions are generated. In this work, we propose KCluster, a novel KC discovery algorithm based on identifying clusters of congruent questions according to a new similarity metric induced by a large language model (LLM). We demonstrate in three datasets that an LLM can create an effective metric of question similarity, which a clustering algorithm can use to create KC models from questions with minimal human effort. Combining the strengths of LLM and clustering, KCluster generates descriptive KC labels and discovers KC models that predict student performance better than the best expert-designed models available. In anticipation of future work, we illustrate how KCluster can reveal insights into difficult KCs and suggest improvements to instruction.
An Automatic Question Usability Evaluation Toolkit
May 30, 2024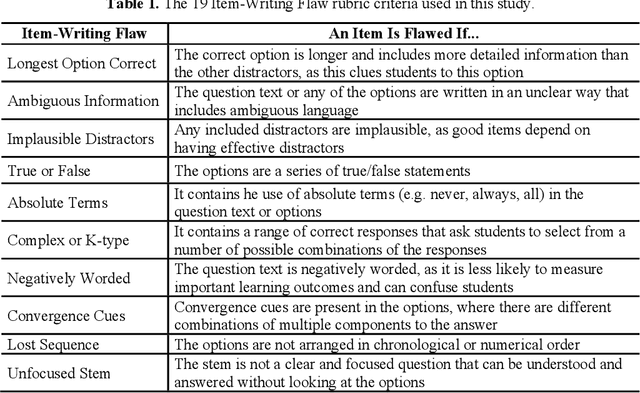

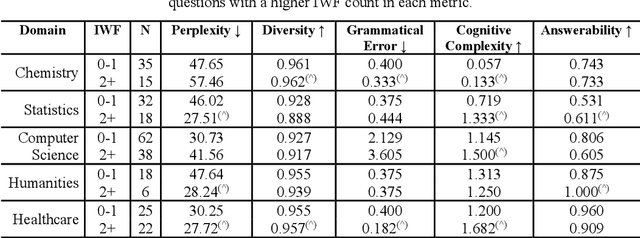
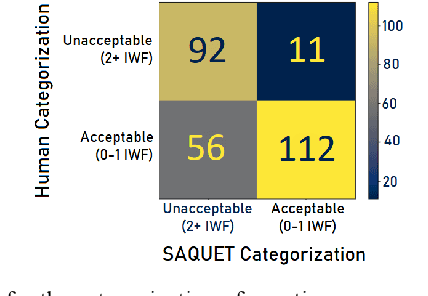
Evaluating multiple-choice questions (MCQs) involves either labor intensive human assessments or automated methods that prioritize readability, often overlooking deeper question design flaws. To address this issue, we introduce the Scalable Automatic Question Usability Evaluation Toolkit (SAQUET), an open-source tool that leverages the Item-Writing Flaws (IWF) rubric for a comprehensive and automated quality evaluation of MCQs. By harnessing the latest in large language models such as GPT-4, advanced word embeddings, and Transformers designed to analyze textual complexity, SAQUET effectively pinpoints and assesses a wide array of flaws in MCQs. We first demonstrate the discrepancy between commonly used automated evaluation metrics and the human assessment of MCQ quality. Then we evaluate SAQUET on a diverse dataset of MCQs across the five domains of Chemistry, Statistics, Computer Science, Humanities, and Healthcare, showing how it effectively distinguishes between flawed and flawless questions, providing a level of analysis beyond what is achievable with traditional metrics. With an accuracy rate of over 94% in detecting the presence of flaws identified by human evaluators, our findings emphasize the limitations of existing evaluation methods and showcase potential in improving the quality of educational assessments.
Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions
May 30, 2024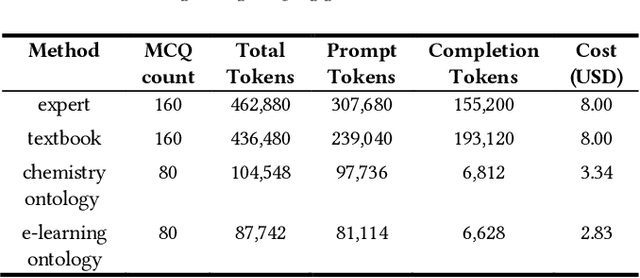
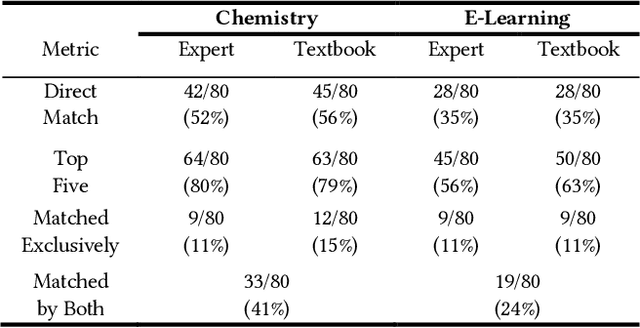


Knowledge Components (KCs) linked to assessments enhance the measurement of student learning, enrich analytics, and facilitate adaptivity. However, generating and linking KCs to assessment items requires significant effort and domain-specific knowledge. To streamline this process for higher-education courses, we employed GPT-4 to generate KCs for multiple-choice questions (MCQs) in Chemistry and E-Learning. We analyzed discrepancies between the KCs generated by the Large Language Model (LLM) and those made by humans through evaluation from three domain experts in each subject area. This evaluation aimed to determine whether, in instances of non-matching KCs, evaluators showed a preference for the LLM-generated KCs over their human-created counterparts. We also developed an ontology induction algorithm to cluster questions that assess similar KCs based on their content. Our most effective LLM strategy accurately matched KCs for 56% of Chemistry and 35% of E-Learning MCQs, with even higher success when considering the top five KC suggestions. Human evaluators favored LLM-generated KCs, choosing them over human-assigned ones approximately two-thirds of the time, a preference that was statistically significant across both domains. Our clustering algorithm successfully grouped questions by their underlying KCs without needing explicit labels or contextual information. This research advances the automation of KC generation and classification for assessment items, alleviating the need for student data or predefined KC labels.
Exploring How Multiple Levels of GPT-Generated Programming Hints Support or Disappoint Novices
Apr 02, 2024



Recent studies have integrated large language models (LLMs) into diverse educational contexts, including providing adaptive programming hints, a type of feedback focuses on helping students move forward during problem-solving. However, most existing LLM-based hint systems are limited to one single hint type. To investigate whether and how different levels of hints can support students' problem-solving and learning, we conducted a think-aloud study with 12 novices using the LLM Hint Factory, a system providing four levels of hints from general natural language guidance to concrete code assistance, varying in format and granularity. We discovered that high-level natural language hints alone can be helpless or even misleading, especially when addressing next-step or syntax-related help requests. Adding lower-level hints, like code examples with in-line comments, can better support students. The findings open up future work on customizing help responses from content, format, and granularity levels to accurately identify and meet students' learning needs.
Assessing the Quality of Multiple-Choice Questions Using GPT-4 and Rule-Based Methods
Jul 16, 2023Multiple-choice questions with item-writing flaws can negatively impact student learning and skew analytics. These flaws are often present in student-generated questions, making it difficult to assess their quality and suitability for classroom usage. Existing methods for evaluating multiple-choice questions often focus on machine readability metrics, without considering their intended use within course materials and their pedagogical implications. In this study, we compared the performance of a rule-based method we developed to a machine-learning based method utilizing GPT-4 for the task of automatically assessing multiple-choice questions based on 19 common item-writing flaws. By analyzing 200 student-generated questions from four different subject areas, we found that the rule-based method correctly detected 91% of the flaws identified by human annotators, as compared to 79% by GPT-4. We demonstrated the effectiveness of the two methods in identifying common item-writing flaws present in the student-generated questions across different subject areas. The rule-based method can accurately and efficiently evaluate multiple-choice questions from multiple domains, outperforming GPT-4 and going beyond existing metrics that do not account for the educational use of such questions. Finally, we discuss the potential for using these automated methods to improve the quality of questions based on the identified flaws.
Learnersourcing in the Age of AI: Student, Educator and Machine Partnerships for Content Creation
Jun 10, 2023Engaging students in creating novel content, also referred to as learnersourcing, is increasingly recognised as an effective approach to promoting higher-order learning, deeply engaging students with course material and developing large repositories of content suitable for personalized learning. Despite these benefits, some common concerns and criticisms are associated with learnersourcing (e.g., the quality of resources created by students, challenges in incentivising engagement and lack of availability of reliable learnersourcing systems), which have limited its adoption. This paper presents a framework that considers the existing learnersourcing literature, the latest insights from the learning sciences and advances in AI to offer promising future directions for developing learnersourcing systems. The framework is designed around important questions and human-AI partnerships relating to four key aspects: (1) creating novel content, (2) evaluating the quality of the created content, (3) utilising learnersourced contributions of students and (4) enabling instructors to support students in the learnersourcing process. We then present two comprehensive case studies that illustrate the application of the proposed framework in relation to two existing popular learnersourcing systems.