 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Generation and Tagging of Knowledge Components from Multiple-Choice Questions
Paper and Code
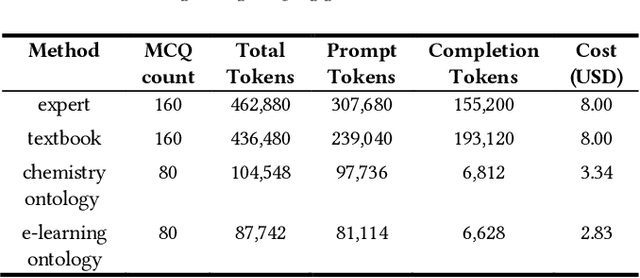
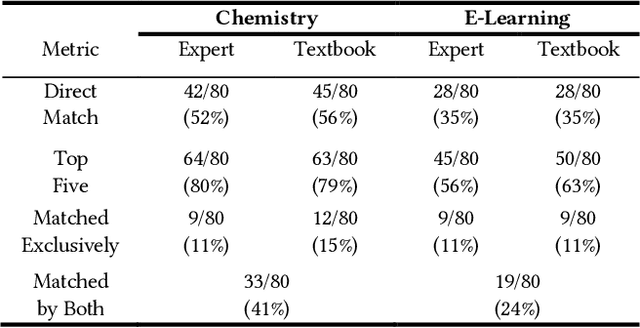


Knowledge Components (KCs) linked to assessments enhance the measurement of student learning, enrich analytics, and facilitate adaptivity. However, generating and linking KCs to assessment items requires significant effort and domain-specific knowledge. To streamline this process for higher-education courses, we employed GPT-4 to generate KCs for multiple-choice questions (MCQs) in Chemistry and E-Learning. We analyzed discrepancies between the KCs generated by the Large Language Model (LLM) and those made by humans through evaluation from three domain experts in each subject area. This evaluation aimed to determine whether, in instances of non-matching KCs, evaluators showed a preference for the LLM-generated KCs over their human-created counterparts. We also developed an ontology induction algorithm to cluster questions that assess similar KCs based on their content. Our most effective LLM strategy accurately matched KCs for 56% of Chemistry and 35% of E-Learning MCQs, with even higher success when considering the top five KC suggestions. Human evaluators favored LLM-generated KCs, choosing them over human-assigned ones approximately two-thirds of the time, a preference that was statistically significant across both domains. Our clustering algorithm successfully grouped questions by their underlying KCs without needing explicit labels or contextual information. This research advances the automation of KC generation and classification for assessment items, alleviating the need for student data or predefined KC labels.