 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Knowledge Re-expression: A Fully Local Method for Adapting LLMs to Tasks Using Intrinsic Knowledge
Apr 24, 2026While the next-token prediction (NTP) paradigm enables large language models (LLMs) to express their intrinsic knowledge, its sequential nature constrains performance on specialized, non-generative tasks. We attribute this performance bottleneck to the LLMs' knowledge expression mechanism, rather than to deficiencies in knowledge acquisition. To address this, we propose Self-Knowledge Re-expression (SKR), a novel, task-agnostic adaptation method. SKR transforms the LLM's output from generic token generation to highly efficient, task-specific expression. SKR is a fully local method that uses only unannotated data, requiring neither human supervision nor model distillation. Experiments on a large financial document dataset demonstrate substantial improvements: over 40% in Recall@1 for information retrieval tasks, over 76% reduction in object detection latency, and over 33% increase in anomaly detection AUPRC. Our results on the MMDocRAG dataset surpass those of leading retrieval models by at least 12.6%.
Learning to Optimize Feedback for One Million Students: Insights from Multi-Armed and Contextual Bandits in Large-Scale Online Tutoring
Aug 01, 2025We present an online tutoring system that learns to provide effective feedback to students after they answer questions incorrectly. Using data from one million students, the system learns which assistance action (e.g., one of multiple hints) to provide for each question to optimize student learning. Employing the multi-armed bandit (MAB) framework and offline policy evaluation, we assess 43,000 assistance actions, and identify trade-offs between assistance policies optimized for different student outcomes (e.g., response correctness, session completion). We design an algorithm that for each question decides on a suitable policy training objective to enhance students' immediate second attempt success and overall practice session performance. We evaluate the resulting MAB policies in 166,000 practice sessions, verifying significant improvements in student outcomes. While MAB policies optimize feedback for the overall student population, we further investigate whether contextual bandit (CB) policies can enhance outcomes by personalizing feedback based on individual student features (e.g., ability estimates, response times). Using causal inference, we examine (i) how effects of assistance actions vary across students and (ii) whether CB policies, which leverage such effect heterogeneity, outperform MAB policies. While our analysis reveals that some actions for some questions exhibit effect heterogeneity, effect sizes may often be too small for CB policies to provide significant improvements beyond what well-optimized MAB policies that deliver the same action to all students already achieve. We discuss insights gained from deploying data-driven systems at scale and implications for future refinements. Today, the teaching policies optimized by our system support thousands of students daily.
The Impact of Item-Writing Flaws on Difficulty and Discrimination in Item Response Theory
Mar 13, 2025



High-quality test items are essential for educational assessments, particularly within Item Response Theory (IRT). Traditional validation methods rely on resource-intensive pilot testing to estimate item difficulty and discrimination. More recently, Item-Writing Flaw (IWF) rubrics emerged as a domain-general approach for evaluating test items based on textual features. However, their relationship to IRT parameters remains underexplored. To address this gap, we conducted a study involving over 7,000 multiple-choice questions across various STEM subjects (e.g., math and biology). Using an automated approach, we annotated each question with a 19-criteria IWF rubric and studied relationships to data-driven IRT parameters. Our analysis revealed statistically significant links between the number of IWFs and IRT difficulty and discrimination parameters, particularly in life and physical science domains. We further observed how specific IWF criteria can impact item quality more and less severely (e.g., negative wording vs. implausible distractors). Overall, while IWFs are useful for predicting IRT parameters--particularly for screening low-difficulty MCQs--they cannot replace traditional data-driven validation methods. Our findings highlight the need for further research on domain-general evaluation rubrics and algorithms that understand domain-specific content for robust item validation.
Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions
May 30, 2024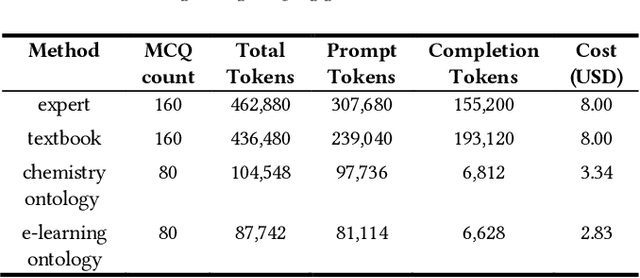
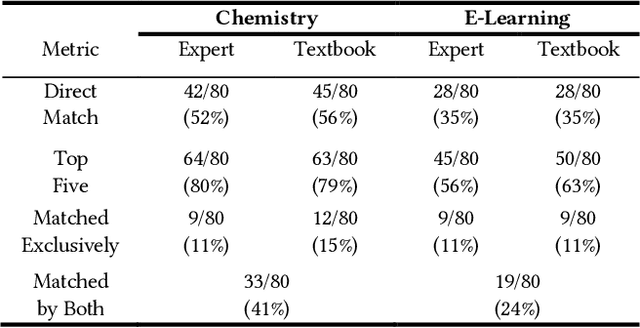


Knowledge Components (KCs) linked to assessments enhance the measurement of student learning, enrich analytics, and facilitate adaptivity. However, generating and linking KCs to assessment items requires significant effort and domain-specific knowledge. To streamline this process for higher-education courses, we employed GPT-4 to generate KCs for multiple-choice questions (MCQs) in Chemistry and E-Learning. We analyzed discrepancies between the KCs generated by the Large Language Model (LLM) and those made by humans through evaluation from three domain experts in each subject area. This evaluation aimed to determine whether, in instances of non-matching KCs, evaluators showed a preference for the LLM-generated KCs over their human-created counterparts. We also developed an ontology induction algorithm to cluster questions that assess similar KCs based on their content. Our most effective LLM strategy accurately matched KCs for 56% of Chemistry and 35% of E-Learning MCQs, with even higher success when considering the top five KC suggestions. Human evaluators favored LLM-generated KCs, choosing them over human-assigned ones approximately two-thirds of the time, a preference that was statistically significant across both domains. Our clustering algorithm successfully grouped questions by their underlying KCs without needing explicit labels or contextual information. This research advances the automation of KC generation and classification for assessment items, alleviating the need for student data or predefined KC labels.
Ruffle&Riley: Insights from Designing and Evaluating a Large Language Model-Based Conversational Tutoring System
Apr 26, 2024Conversational tutoring systems (CTSs) offer learning experiences through interactions based on natural language. They are recognized for promoting cognitive engagement and improving learning outcomes, especially in reasoning tasks. Nonetheless, the cost associated with authoring CTS content is a major obstacle to widespread adoption and to research on effective instructional design. In this paper, we discuss and evaluate a novel type of CTS that leverages recent advances in large language models (LLMs) in two ways: First, the system enables AI-assisted content authoring by inducing an easily editable tutoring script automatically from a lesson text. Second, the system automates the script orchestration in a learning-by-teaching format via two LLM-based agents (Ruffle&Riley) acting as a student and a professor. The system allows for free-form conversations that follow the ITS-typical inner and outer loop structure. We evaluate Ruffle&Riley's ability to support biology lessons in two between-subject online user studies (N = 200) comparing the system to simpler QA chatbots and reading activity. Analyzing system usage patterns, pre/post-test scores and user experience surveys, we find that Ruffle&Riley users report high levels of engagement, understanding and perceive the offered support as helpful. Even though Ruffle&Riley users require more time to complete the activity, we did not find significant differences in short-term learning gains over the reading activity. Our system architecture and user study provide various insights for designers of future CTSs. We further open-source our system to support ongoing research on effective instructional design of LLM-based learning technologies.
NEOLAF, an LLM-powered neural-symbolic cognitive architecture
Aug 08, 2023This paper presents the Never Ending Open Learning Adaptive Framework (NEOLAF), an integrated neural-symbolic cognitive architecture that models and constructs intelligent agents. The NEOLAF framework is a superior approach to constructing intelligent agents than both the pure connectionist and pure symbolic approaches due to its explainability, incremental learning, efficiency, collaborative and distributed learning, human-in-the-loop enablement, and self-improvement. The paper further presents a compelling experiment where a NEOLAF agent, built as a problem-solving agent, is fed with complex math problems from the open-source MATH dataset. The results demonstrate NEOLAF's superior learning capability and its potential to revolutionize the field of cognitive architectures and self-improving adaptive instructional systems.
Transferable Student Performance Modeling for Intelligent Tutoring Systems
Feb 08, 2022


Millions of learners worldwide are now using intelligent tutoring systems (ITSs). At their core, ITSs rely on machine learning algorithms to track each user's changing performance level over time to provide personalized instruction. Crucially, student performance models are trained using interaction sequence data of previous learners to analyse data generated by future learners. This induces a cold-start problem when a new course is introduced for which no training data is available. Here, we consider transfer learning techniques as a way to provide accurate performance predictions for new courses by leveraging log data from existing courses. We study two settings: (i) In the naive transfer setting, we propose course-agnostic performance models that can be applied to any course. (ii) In the inductive transfer setting, we tune pre-trained course-agnostic performance models to new courses using small-scale target course data (e.g., collected during a pilot study). We evaluate the proposed techniques using student interaction sequence data from 5 different mathematics courses containing data from over 47,000 students in a real world large-scale ITS. The course-agnostic models that use additional features provided by human domain experts (e.g, difficulty ratings for questions in the new course) but no student interaction training data for the new course, achieve prediction accuracy on par with standard BKT and PFA models that use training data from thousands of students in the new course. In the inductive setting our transfer learning approach yields more accurate predictions than conventional performance models when only limited student interaction training data (<100 students) is available to both.
Assessing the Knowledge State of Online Students -- New Data, New Approaches, Improved Accuracy
Sep 04, 2021
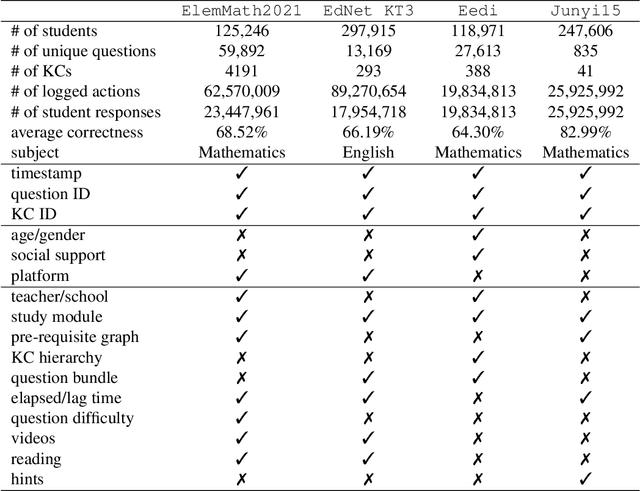
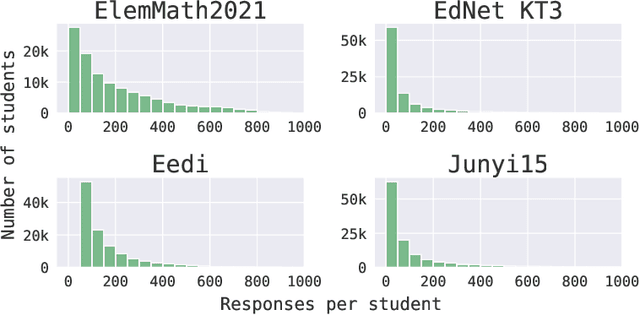
We consider the problem of assessing the changing knowledge state of individual students as they go through online courses. This student performance (SP) modeling problem, also known as knowledge tracing, is a critical step for building adaptive online teaching systems. Specifically, we conduct a study of how to utilize various types and large amounts of students log data to train accurate machine learning models that predict the knowledge state of future students. This study is the first to use four very large datasets made available recently from four distinct intelligent tutoring systems. Our results include a new machine learning approach that defines a new state of the art for SP modeling, improving over earlier methods in several ways: First, we achieve improved accuracy by introducing new features that can be easily computed from conventional question-response logs (e.g., the pattern in the student's most recent answers). Second, we take advantage of features of the student history that go beyond question-response pairs (e.g., which video segments the student watched, or skipped) as well as information about prerequisite structure in the curriculum. Third, we train multiple specialized modeling models for different aspects of the curriculum (e.g., specializing in early versus later segments of the student history), then combine these specialized models to create a group prediction of student knowledge. Taken together, these innovations yield an average AUC score across these four datasets of 0.807 compared to the previous best logistic regression approach score of 0.766, and also outperforming state-of-the-art deep neural net approaches. Importantly, we observe consistent improvements from each of our three methodological innovations, in each dataset, suggesting that our methods are of general utility and likely to produce improvements for other online tutoring systems as well.
Multi-objective Asynchronous Successive Halving
Jun 23, 2021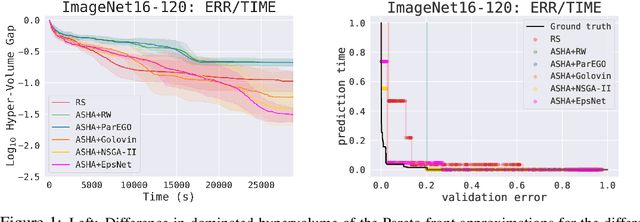

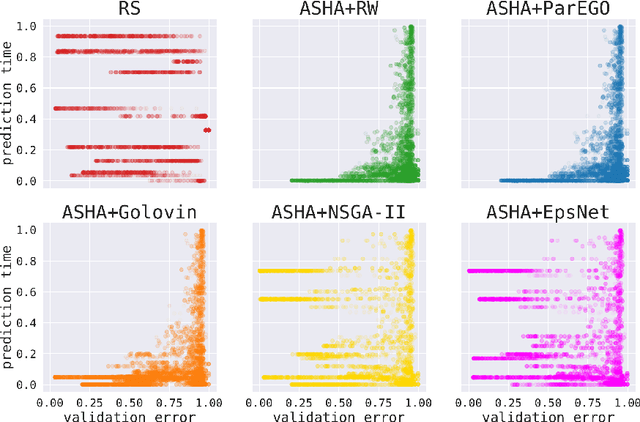

Hyperparameter optimization (HPO) is increasingly used to automatically tune the predictive performance (e.g., accuracy) of machine learning models. However, in a plethora of real-world applications, accuracy is only one of the multiple -- often conflicting -- performance criteria, necessitating the adoption of a multi-objective (MO) perspective. While the literature on MO optimization is rich, few prior studies have focused on HPO. In this paper, we propose algorithms that extend asynchronous successive halving (ASHA) to the MO setting. Considering multiple evaluation metrics, we assess the performance of these methods on three real world tasks: (i) Neural architecture search, (ii) algorithmic fairness and (iii) language model optimization. Our empirical analysis shows that MO ASHA enables to perform MO HPO at scale. Further, we observe that that taking the entire Pareto front into account for candidate selection consistently outperforms multi-fidelity HPO based on MO scalarization in terms of wall-clock time. Our algorithms (to be open-sourced) establish new baselines for future research in the area.
Bandit Linear Optimization for Sequential Decision Making and Extensive-Form Games
Mar 08, 2021
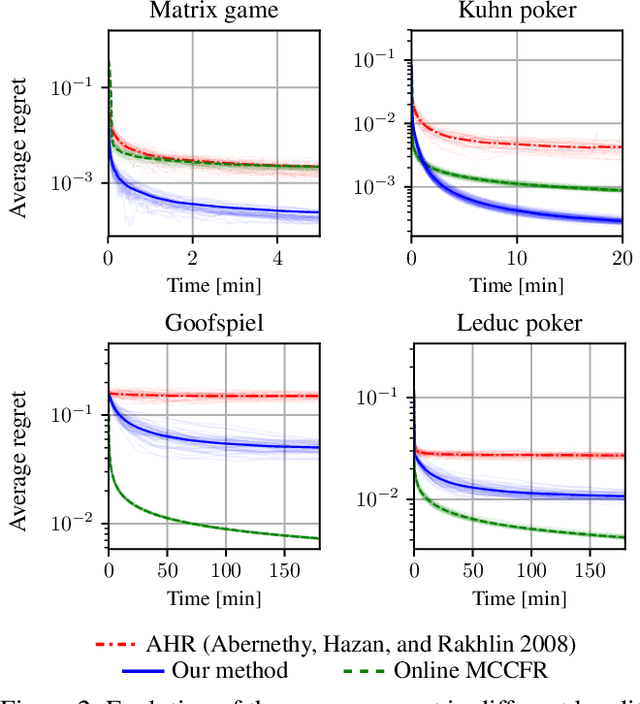
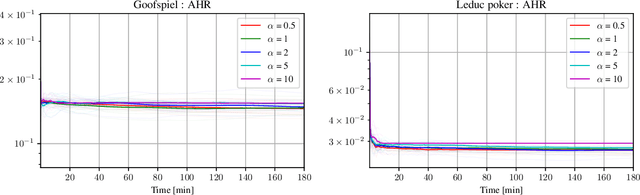
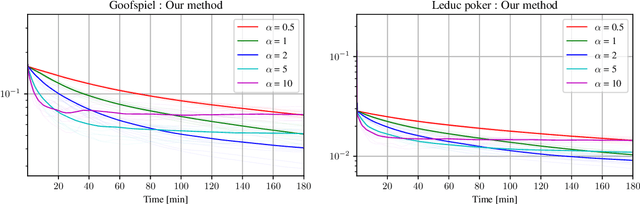
Tree-form sequential decision making (TFSDM) extends classical one-shot decision making by modeling tree-form interactions between an agent and a potentially adversarial environment. It captures the online decision-making problems that each player faces in an extensive-form game, as well as Markov decision processes and partially-observable Markov decision processes where the agent conditions on observed history. Over the past decade, there has been considerable effort into designing online optimization methods for TFSDM. Virtually all of that work has been in the full-feedback setting, where the agent has access to counterfactuals, that is, information on what would have happened had the agent chosen a different action at any decision node. Little is known about the bandit setting, where that assumption is reversed (no counterfactual information is available), despite this latter setting being well understood for almost 20 years in one-shot decision making. In this paper, we give the first algorithm for the bandit linear optimization problem for TFSDM that offers both (i) linear-time iterations (in the size of the decision tree) and (ii) $O(\sqrt{T})$ cumulative regret in expectation compared to any fixed strategy, at all times $T$. This is made possible by new results that we derive, which may have independent uses as well: 1) geometry of the dilated entropy regularizer, 2) autocorrelation matrix of the natural sampling scheme for sequence-form strategies, 3) construction of an unbiased estimator for linear losses for sequence-form strategies, and 4) a refined regret analysis for mirror descent when using the dilated entropy regularizer.