 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Item-Writing Flaws on Difficulty and Discrimination in Item Response Theory
Mar 13, 2025



High-quality test items are essential for educational assessments, particularly within Item Response Theory (IRT). Traditional validation methods rely on resource-intensive pilot testing to estimate item difficulty and discrimination. More recently, Item-Writing Flaw (IWF) rubrics emerged as a domain-general approach for evaluating test items based on textual features. However, their relationship to IRT parameters remains underexplored. To address this gap, we conducted a study involving over 7,000 multiple-choice questions across various STEM subjects (e.g., math and biology). Using an automated approach, we annotated each question with a 19-criteria IWF rubric and studied relationships to data-driven IRT parameters. Our analysis revealed statistically significant links between the number of IWFs and IRT difficulty and discrimination parameters, particularly in life and physical science domains. We further observed how specific IWF criteria can impact item quality more and less severely (e.g., negative wording vs. implausible distractors). Overall, while IWFs are useful for predicting IRT parameters--particularly for screening low-difficulty MCQs--they cannot replace traditional data-driven validation methods. Our findings highlight the need for further research on domain-general evaluation rubrics and algorithms that understand domain-specific content for robust item validation.
An Automatic Question Usability Evaluation Toolkit
May 30, 2024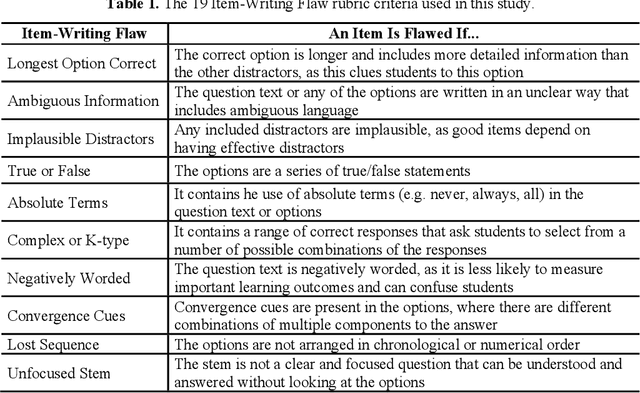

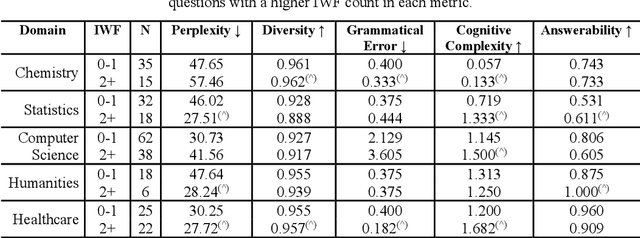
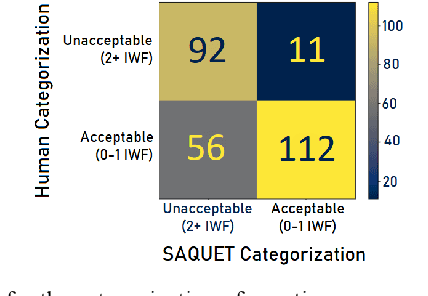
Evaluating multiple-choice questions (MCQs) involves either labor intensive human assessments or automated methods that prioritize readability, often overlooking deeper question design flaws. To address this issue, we introduce the Scalable Automatic Question Usability Evaluation Toolkit (SAQUET), an open-source tool that leverages the Item-Writing Flaws (IWF) rubric for a comprehensive and automated quality evaluation of MCQs. By harnessing the latest in large language models such as GPT-4, advanced word embeddings, and Transformers designed to analyze textual complexity, SAQUET effectively pinpoints and assesses a wide array of flaws in MCQs. We first demonstrate the discrepancy between commonly used automated evaluation metrics and the human assessment of MCQ quality. Then we evaluate SAQUET on a diverse dataset of MCQs across the five domains of Chemistry, Statistics, Computer Science, Humanities, and Healthcare, showing how it effectively distinguishes between flawed and flawless questions, providing a level of analysis beyond what is achievable with traditional metrics. With an accuracy rate of over 94% in detecting the presence of flaws identified by human evaluators, our findings emphasize the limitations of existing evaluation methods and showcase potential in improving the quality of educational assessments.
Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions
May 30, 2024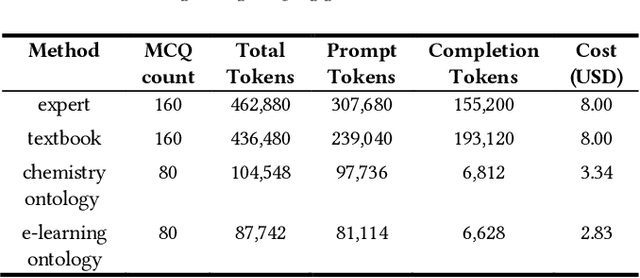
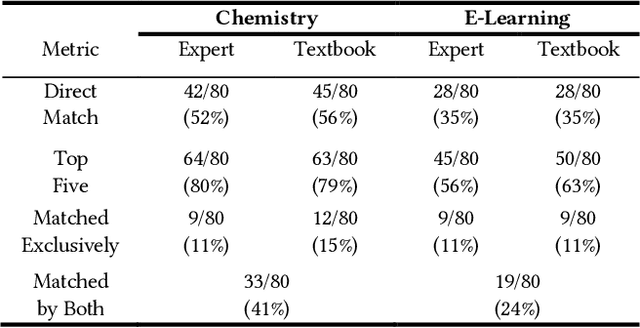


Knowledge Components (KCs) linked to assessments enhance the measurement of student learning, enrich analytics, and facilitate adaptivity. However, generating and linking KCs to assessment items requires significant effort and domain-specific knowledge. To streamline this process for higher-education courses, we employed GPT-4 to generate KCs for multiple-choice questions (MCQs) in Chemistry and E-Learning. We analyzed discrepancies between the KCs generated by the Large Language Model (LLM) and those made by humans through evaluation from three domain experts in each subject area. This evaluation aimed to determine whether, in instances of non-matching KCs, evaluators showed a preference for the LLM-generated KCs over their human-created counterparts. We also developed an ontology induction algorithm to cluster questions that assess similar KCs based on their content. Our most effective LLM strategy accurately matched KCs for 56% of Chemistry and 35% of E-Learning MCQs, with even higher success when considering the top five KC suggestions. Human evaluators favored LLM-generated KCs, choosing them over human-assigned ones approximately two-thirds of the time, a preference that was statistically significant across both domains. Our clustering algorithm successfully grouped questions by their underlying KCs without needing explicit labels or contextual information. This research advances the automation of KC generation and classification for assessment items, alleviating the need for student data or predefined KC labels.
Generative AI for Education (GAIED): Advances, Opportunities, and Challenges
Feb 07, 2024This survey article has grown out of the GAIED (pronounced "guide") workshop organized by the authors at the NeurIPS 2023 conference. We organized the GAIED workshop as part of a community-building effort to bring together researchers, educators, and practitioners to explore the potential of generative AI for enhancing education. This article aims to provide an overview of the workshop activities and highlight several future research directions in the area of GAIED.
Assessing the Quality of Multiple-Choice Questions Using GPT-4 and Rule-Based Methods
Jul 16, 2023Multiple-choice questions with item-writing flaws can negatively impact student learning and skew analytics. These flaws are often present in student-generated questions, making it difficult to assess their quality and suitability for classroom usage. Existing methods for evaluating multiple-choice questions often focus on machine readability metrics, without considering their intended use within course materials and their pedagogical implications. In this study, we compared the performance of a rule-based method we developed to a machine-learning based method utilizing GPT-4 for the task of automatically assessing multiple-choice questions based on 19 common item-writing flaws. By analyzing 200 student-generated questions from four different subject areas, we found that the rule-based method correctly detected 91% of the flaws identified by human annotators, as compared to 79% by GPT-4. We demonstrated the effectiveness of the two methods in identifying common item-writing flaws present in the student-generated questions across different subject areas. The rule-based method can accurately and efficiently evaluate multiple-choice questions from multiple domains, outperforming GPT-4 and going beyond existing metrics that do not account for the educational use of such questions. Finally, we discuss the potential for using these automated methods to improve the quality of questions based on the identified flaws.
Learnersourcing in the Age of AI: Student, Educator and Machine Partnerships for Content Creation
Jun 10, 2023Engaging students in creating novel content, also referred to as learnersourcing, is increasingly recognised as an effective approach to promoting higher-order learning, deeply engaging students with course material and developing large repositories of content suitable for personalized learning. Despite these benefits, some common concerns and criticisms are associated with learnersourcing (e.g., the quality of resources created by students, challenges in incentivising engagement and lack of availability of reliable learnersourcing systems), which have limited its adoption. This paper presents a framework that considers the existing learnersourcing literature, the latest insights from the learning sciences and advances in AI to offer promising future directions for developing learnersourcing systems. The framework is designed around important questions and human-AI partnerships relating to four key aspects: (1) creating novel content, (2) evaluating the quality of the created content, (3) utilising learnersourced contributions of students and (4) enabling instructors to support students in the learnersourcing process. We then present two comprehensive case studies that illustrate the application of the proposed framework in relation to two existing popular learnersourcing systems.
fAIlureNotes: Supporting Designers in Understanding the Limits of AI Models for Computer Vision Tasks
Feb 22, 2023
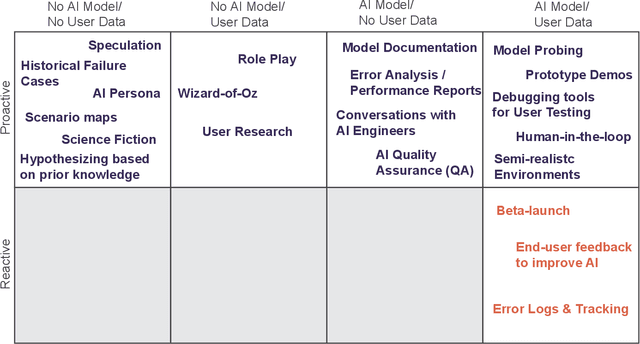
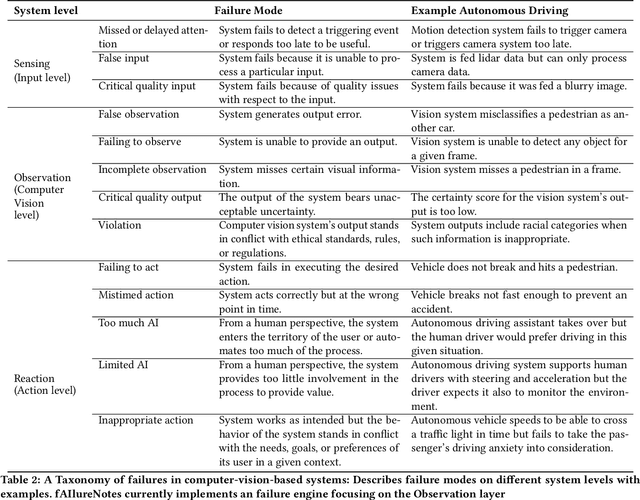
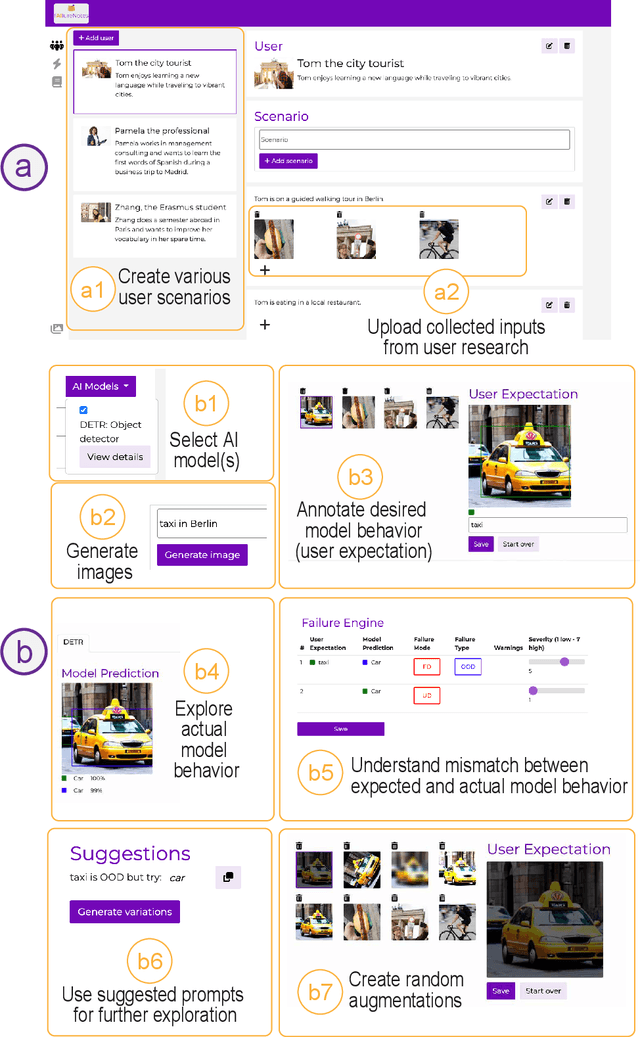
To design with AI models, user experience (UX) designers must assess the fit between the model and user needs. Based on user research, they need to contextualize the model's behavior and potential failures within their product-specific data instances and user scenarios. However, our formative interviews with ten UX professionals revealed that such a proactive discovery of model limitations is challenging and time-intensive. Furthermore, designers often lack technical knowledge of AI and accessible exploration tools, which challenges their understanding of model capabilities and limitations. In this work, we introduced a failure-driven design approach to AI, a workflow that encourages designers to explore model behavior and failure patterns early in the design process. The implementation of fAIlureNotes, a designer-centered failure exploration and analysis tool, supports designers in evaluating models and identifying failures across diverse user groups and scenarios. Our evaluation with UX practitioners shows that fAIlureNotes outperforms today's interactive model cards in assessing context-specific model performance.