 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow critically can an AI think? A framework for evaluating the quality of thinking of generative artificial intelligence
Jun 20, 2024

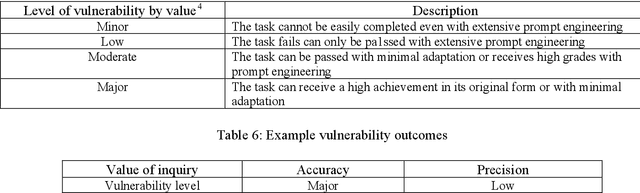
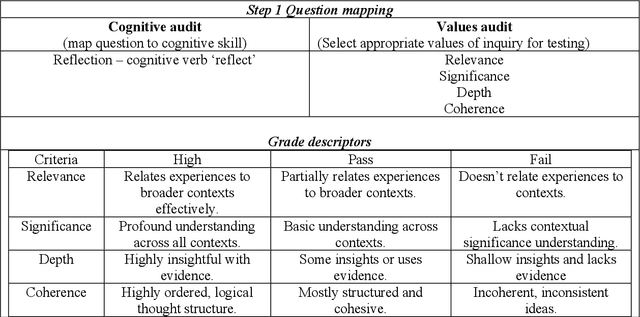
Generative AI such as those with large language models have created opportunities for innovative assessment design practices. Due to recent technological developments, there is a need to know the limits and capabilities of generative AI in terms of simulating cognitive skills. Assessing student critical thinking skills has been a feature of assessment for time immemorial, but the demands of digital assessment create unique challenges for equity, academic integrity and assessment authorship. Educators need a framework for determining their assessments vulnerability to generative AI to inform assessment design practices. This paper presents a framework that explores the capabilities of the LLM ChatGPT4 application, which is the current industry benchmark. This paper presents the Mapping of questions, AI vulnerability testing, Grading, Evaluation (MAGE) framework to methodically critique their assessments within their own disciplinary contexts. This critique will provide specific and targeted indications of their questions vulnerabilities in terms of the critical thinking skills. This can go on to form the basis of assessment design for their tasks.
Large Language Models Meet User Interfaces: The Case of Provisioning Feedback
Apr 17, 2024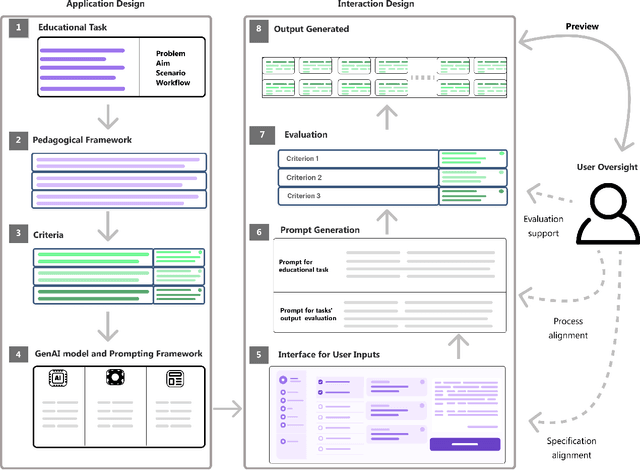

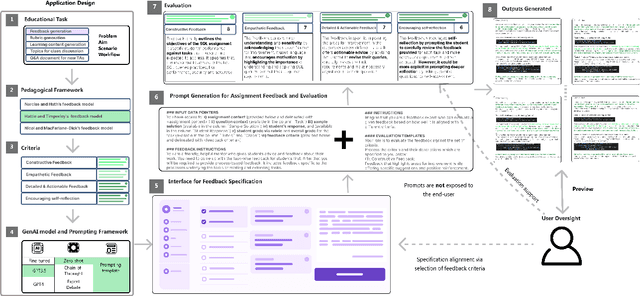

Incorporating Generative AI (GenAI) and Large Language Models (LLMs) in education can enhance teaching efficiency and enrich student learning. Current LLM usage involves conversational user interfaces (CUIs) for tasks like generating materials or providing feedback. However, this presents challenges including the need for educator expertise in AI and CUIs, ethical concerns with high-stakes decisions, and privacy risks. CUIs also struggle with complex tasks. To address these, we propose transitioning from CUIs to user-friendly applications leveraging LLMs via API calls. We present a framework for ethically incorporating GenAI into educational tools and demonstrate its application in our tool, Feedback Copilot, which provides personalized feedback on student assignments. Our evaluation shows the effectiveness of this approach, with implications for GenAI researchers, educators, and technologists. This work charts a course for the future of GenAI in education.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023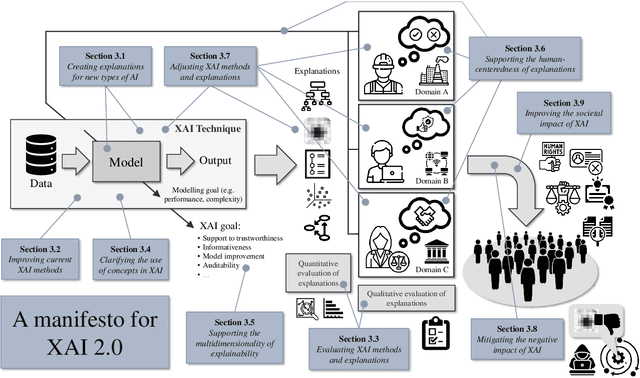
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Can We Trust AI-Generated Educational Content? Comparative Analysis of Human and AI-Generated Learning Resources
Jul 03, 2023
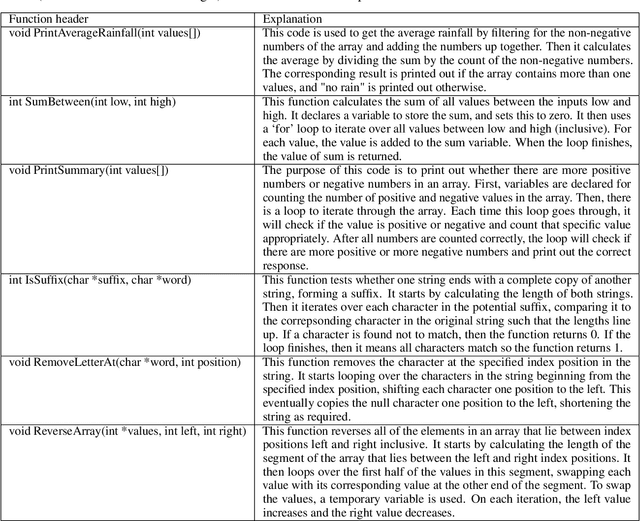
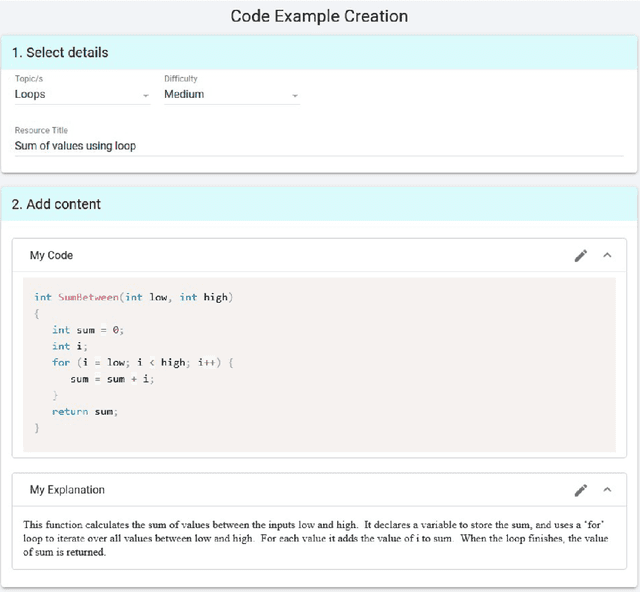

As an increasing number of students move to online learning platforms that deliver personalized learning experiences, there is a great need for the production of high-quality educational content. Large language models (LLMs) appear to offer a promising solution to the rapid creation of learning materials at scale, reducing the burden on instructors. In this study, we investigated the potential for LLMs to produce learning resources in an introductory programming context, by comparing the quality of the resources generated by an LLM with those created by students as part of a learnersourcing activity. Using a blind evaluation, students rated the correctness and helpfulness of resources generated by AI and their peers, after both were initially provided with identical exemplars. Our results show that the quality of AI-generated resources, as perceived by students, is equivalent to the quality of resources generated by their peers. This suggests that AI-generated resources may serve as viable supplementary material in certain contexts. Resources generated by LLMs tend to closely mirror the given exemplars, whereas student-generated resources exhibit greater variety in terms of content length and specific syntax features used. The study highlights the need for further research exploring different types of learning resources and a broader range of subject areas, and understanding the long-term impact of AI-generated resources on learning outcomes.
Learnersourcing in the Age of AI: Student, Educator and Machine Partnerships for Content Creation
Jun 10, 2023Engaging students in creating novel content, also referred to as learnersourcing, is increasingly recognised as an effective approach to promoting higher-order learning, deeply engaging students with course material and developing large repositories of content suitable for personalized learning. Despite these benefits, some common concerns and criticisms are associated with learnersourcing (e.g., the quality of resources created by students, challenges in incentivising engagement and lack of availability of reliable learnersourcing systems), which have limited its adoption. This paper presents a framework that considers the existing learnersourcing literature, the latest insights from the learning sciences and advances in AI to offer promising future directions for developing learnersourcing systems. The framework is designed around important questions and human-AI partnerships relating to four key aspects: (1) creating novel content, (2) evaluating the quality of the created content, (3) utilising learnersourced contributions of students and (4) enabling instructors to support students in the learnersourcing process. We then present two comprehensive case studies that illustrate the application of the proposed framework in relation to two existing popular learnersourcing systems.
Learning Class-Level Bayes Nets for Relational Data
Oct 20, 2009
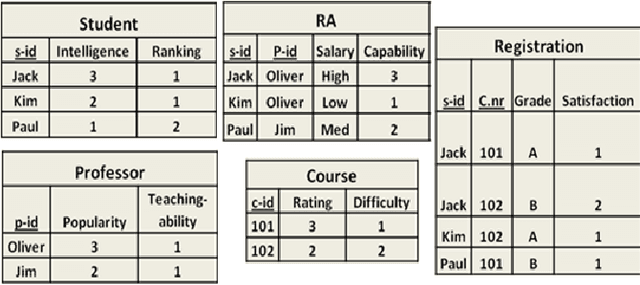
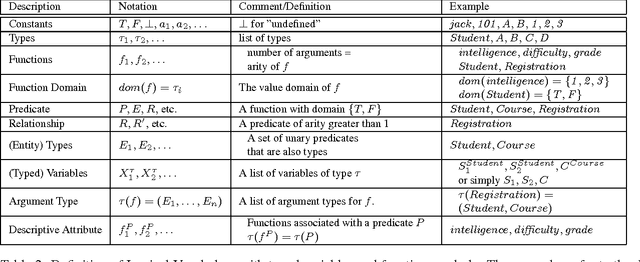
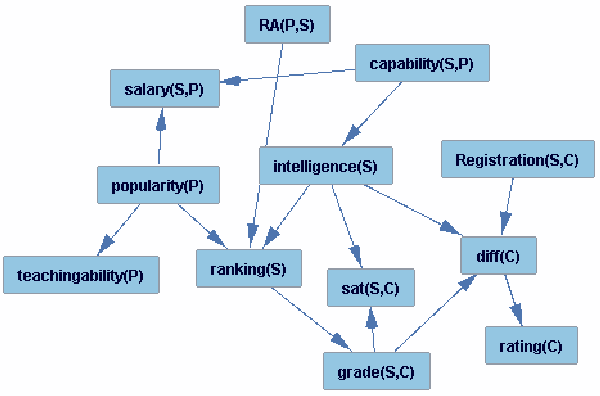
Many databases store data in relational format, with different types of entities and information about links between the entities. The field of statistical-relational learning (SRL) has developed a number of new statistical models for such data. In this paper we focus on learning class-level or first-order dependencies, which model the general database statistics over attributes of linked objects and links (e.g., the percentage of A grades given in computer science classes). Class-level statistical relationships are important in themselves, and they support applications like policy making, strategic planning, and query optimization. Most current SRL methods find class-level dependencies, but their main task is to support instance-level predictions about the attributes or links of specific entities. We focus only on class-level prediction, and describe algorithms for learning class-level models that are orders of magnitude faster for this task. Our algorithms learn Bayes nets with relational structure, leveraging the efficiency of single-table nonrelational Bayes net learners. An evaluation of our methods on three data sets shows that they are computationally feasible for realistic table sizes, and that the learned structures represent the statistical information in the databases well. After learning compiles the database statistics into a Bayes net, querying these statistics via Bayes net inference is faster than with SQL queries, and does not depend on the size of the database.