 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Modern Machine Learning Models for Retail Sales Forecasting
Jun 06, 2025Accurate forecasting is key for all business planning. When estimated sales are too high, brick-and-mortar retailers may incur higher costs due to unsold inventories, higher labor and storage space costs, etc. On the other hand, when forecasts underestimate the level of sales, firms experience lost sales, shortages, and impact on the reputation of the retailer in their relevant market. Accurate forecasting presents a competitive advantage for companies. It facilitates the achievement of revenue and profit goals and execution of pricing strategy and tactics. In this study, we provide an exhaustive assessment of the forecasting models applied to a high-resolution brick-and-mortar retail dataset. Our forecasting framework addresses the problems found in retail environments, including intermittent demand, missing values, and frequent product turnover. We compare tree-based ensembles (such as XGBoost and LightGBM) and state-of-the-art neural network architectures (including N-BEATS, NHITS, and the Temporal Fusion Transformer) across various experimental settings. Our results show that localized modeling strategies especially those using tree-based models on individual groups with non-imputed data, consistently deliver superior forecasting accuracy and computational efficiency. In contrast, neural models benefit from advanced imputation methods, yet still fall short in handling the irregularities typical of physical retail data. These results further practical understanding for model selection in retail environment and highlight the significance of data preprocessing to improve forecast performance.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023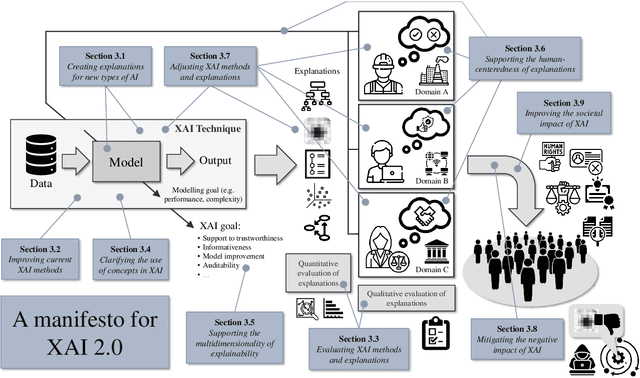
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Prismal view of ethics
May 26, 2022

We shall have a hard look at ethics and try to extract insights in the form of abstract properties that might become tools. We want to connect ethics to games, talk about the performance of ethics, introduce curiosity into the interplay between competing and coordinating in well-performing ethics, and offer a view of possible developments that could unify increasing aggregates of entities. All this is under a long shadow cast by computational complexity that is quite negative about games. This analysis is the first step toward finding modeling aspects that might be used in AI ethics for integrating modern AI systems into human society.
Explainability in reinforcement learning: perspective and position
Mar 22, 2022

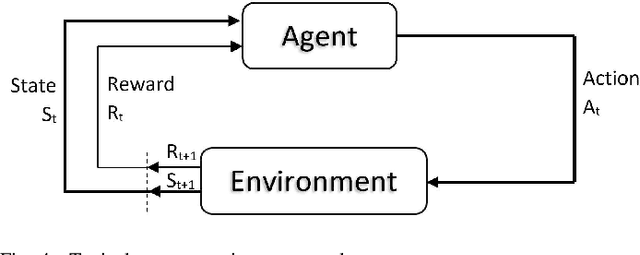

Artificial intelligence (AI) has been embedded into many aspects of people's daily lives and it has become normal for people to have AI make decisions for them. Reinforcement learning (RL) models increase the space of solvable problems with respect to other machine learning paradigms. Some of the most interesting applications are in situations with non-differentiable expected reward function, operating in unknown or underdefined environment, as well as for algorithmic discovery that surpasses performance of any teacher, whereby agent learns from experimental experience through simple feedback. The range of applications and their social impact is vast, just to name a few: genomics, game-playing (chess, Go, etc.), general optimization, financial investment, governmental policies, self-driving cars, recommendation systems, etc. It is therefore essential to improve the trust and transparency of RL-based systems through explanations. Most articles dealing with explainability in artificial intelligence provide methods that concern supervised learning and there are very few articles dealing with this in the area of RL. The reasons for this are the credit assignment problem, delayed rewards, and the inability to assume that data is independently and identically distributed (i.i.d.). This position paper attempts to give a systematic overview of existing methods in the explainable RL area and propose a novel unified taxonomy, building and expanding on the existing ones. The position section describes pragmatic aspects of how explainability can be observed. The gap between the parties receiving and generating the explanation is especially emphasized. To reduce the gap and achieve honesty and truthfulness of explanations, we set up three pillars: proactivity, risk attitudes, and epistemological constraints. To this end, we illustrate our proposal on simple variants of the shortest path problem.
Impossibility Results in AI: A Survey
Sep 01, 2021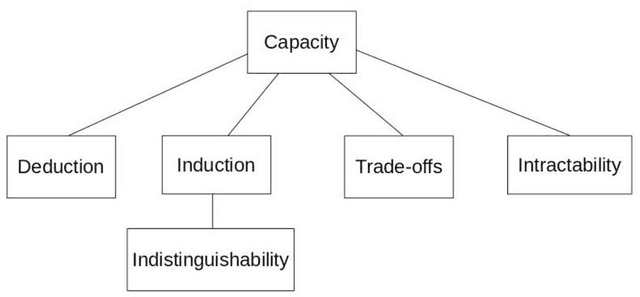
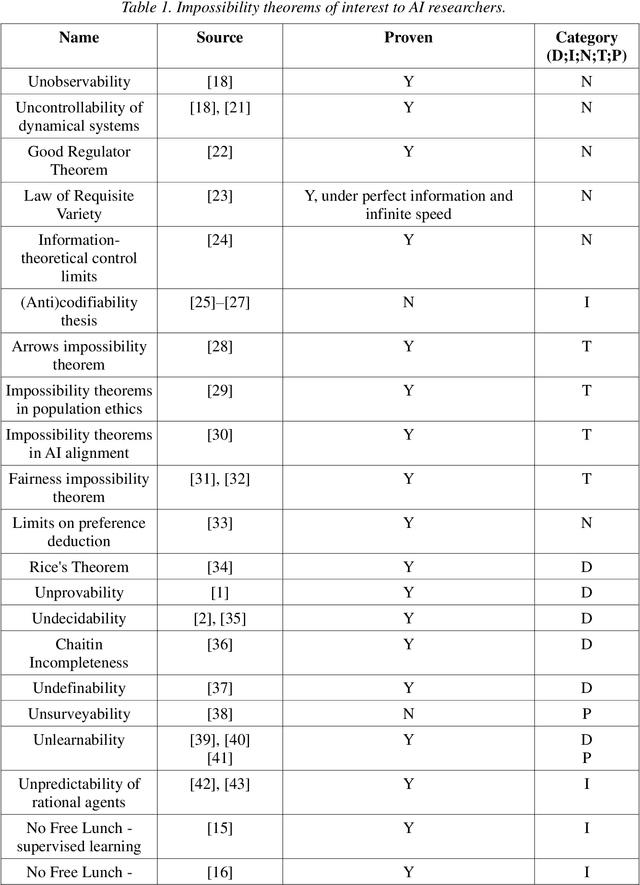

An impossibility theorem demonstrates that a particular problem or set of problems cannot be solved as described in the claim. Such theorems put limits on what is possible to do concerning artificial intelligence, especially the super-intelligent one. As such, these results serve as guidelines, reminders, and warnings to AI safety, AI policy, and governance researchers. These might enable solutions to some long-standing questions in the form of formalizing theories in the framework of constraint satisfaction without committing to one option. In this paper, we have categorized impossibility theorems applicable to the domain of AI into five categories: deduction, indistinguishability, induction, tradeoffs, and intractability. We found that certain theorems are too specific or have implicit assumptions that limit application. Also, we added a new result (theorem) about the unfairness of explainability, the first explainability-related result in the induction category. We concluded that deductive impossibilities deny 100%-guarantees for security. In the end, we give some ideas that hold potential in explainability, controllability, value alignment, ethics, and group decision-making. They can be deepened by further investigation.
AI safety: state of the field through quantitative lens
Feb 12, 2020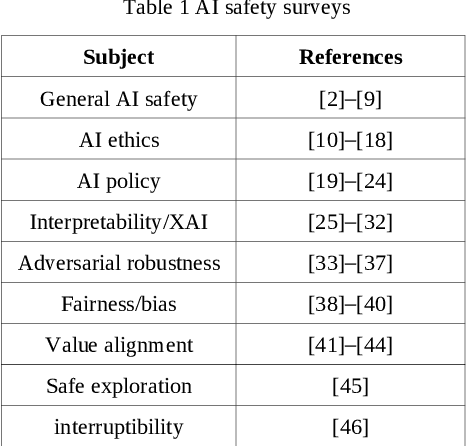
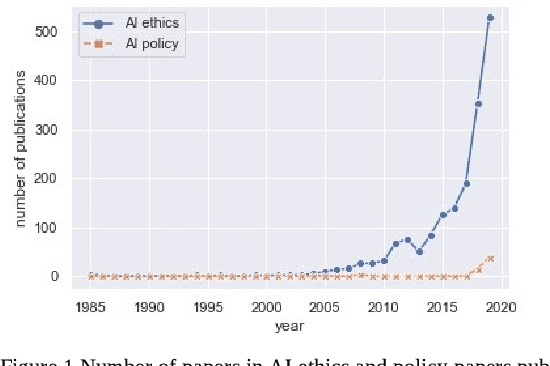
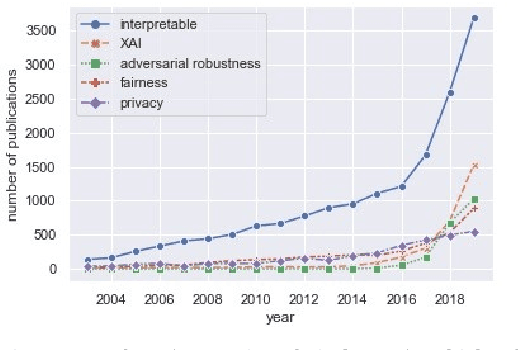

Last decade has seen major improvements in the performance of artificial intelligence which has driven wide-spread applications. Unforeseen effects of such mass-adoption has put the notion of AI safety into the public eye. AI safety is a relatively new field of research focused on techniques for building AI beneficial for humans. While there exist survey papers for the field of AI safety, there is a lack of a quantitative look at the research being conducted. The quantitative aspect gives a data-driven insight about the emerging trends, knowledge gaps and potential areas for future research. In this paper, bibliometric analysis of the literature finds significant increase in research activity since 2015. Also, the field is so new that most of the technical issues are open, including: explainability with its long-term utility, and value alignment which we have identified as the most important long-term research topic. Equally, there is a severe lack of research into concrete policies regarding AI. As we expect AI to be the one of the main driving forces of changes in society, AI safety is the field under which we need to decide the direction of humanity's future.