 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal Before Decoding: Detecting and Exploiting Refusal Signals in Intermediate LLM Activations
May 27, 2026In this paper, we investigate whether refusal behavior can be predicted from LLM intermediate activations before decoding using linear probes trained on residual stream activations at each transformer block. We find that refusal is linearly decodable well before the final layer, indicating that safety-relevant behavior is represented in intermediate activations before output generation. To test whether this signal is actionable, we introduce Mechanistic AutoDAN, a probe-guided variant of AutoDAN that replaces full-model fitness evaluation with partial forward passes and probe-based scoring inside a genetic prompt search loop. Across the evaluated models, our method achieves attack success rates competitive with vanilla AutoDAN while reducing per-iteration search time by up to 72%, and probe-guided prompts match or exceed AutoDAN's cross-model transfer in several configurations. We further find that the usefulness of probe guidance increases with model scale. Our results show that refusal is not only observable at the output level, but is encoded as a structured and actionable signal in intermediate LLM activations.
Supervised Classification Heads as Semantic Prototypes: Unlocking Vision-Language Alignment via Weight Recycling
May 21, 2026Vision-Language Models (VLMs) excel at tasks like zero-shot classification and cross-modal retrieval by mapping images and text to a shared space, but this requires expensive end-to-end training with massive paired datasets. Current post-hoc alignment methods reduce computational costs by connecting pretrained encoders through lightweight mappings, yet still demand substantial paired data. In this work, we investigate the potential of repurposing the classification heads of pretrained vision models as semantic prototypes. The recycling of these weights, typically discarded after pretraining, unlocks two distinct capabilities: it enables zero-shot alignment by using weights as semantic anchors, and serves as a robust data augmentation strategy by mixing these prototypes with real image-text pairs. We demonstrate that integrating our approach with several state-of-the-art post-hoc alignment techniques consistently boosts accuracy in cross-modal retrieval, zero- and few-shot classification tasks.
(Sometimes) Less is More: Mitigating the Complexity of Rule-based Representation for Interpretable Classification
Sep 26, 2025Deep neural networks are widely used in practical applications of AI, however, their inner structure and complexity made them generally not easily interpretable. Model transparency and interpretability are key requirements for multiple scenarios where high performance is not enough to adopt the proposed solution. In this work, a differentiable approximation of $L_0$ regularization is adapted into a logic-based neural network, the Multi-layer Logical Perceptron (MLLP), to study its efficacy in reducing the complexity of its discrete interpretable version, the Concept Rule Set (CRS), while retaining its performance. The results are compared to alternative heuristics like Random Binarization of the network weights, to determine if better results can be achieved when using a less-noisy technique that sparsifies the network based on the loss function instead of a random distribution. The trade-off between the CRS complexity and its performance is discussed.
CUBIC: Concept Embeddings for Unsupervised Bias Identification using VLMs
May 16, 2025Deep vision models often rely on biases learned from spurious correlations in datasets. To identify these biases, methods that interpret high-level, human-understandable concepts are more effective than those relying primarily on low-level features like heatmaps. A major challenge for these concept-based methods is the lack of image annotations indicating potentially bias-inducing concepts, since creating such annotations requires detailed labeling for each dataset and concept, which is highly labor-intensive. We present CUBIC (Concept embeddings for Unsupervised Bias IdentifiCation), a novel method that automatically discovers interpretable concepts that may bias classifier behavior. Unlike existing approaches, CUBIC does not rely on predefined bias candidates or examples of model failures tied to specific biases, as such information is not always available. Instead, it leverages image-text latent space and linear classifier probes to examine how the latent representation of a superclass label$\unicode{x2014}$shared by all instances in the dataset$\unicode{x2014}$is influenced by the presence of a given concept. By measuring these shifts against the normal vector to the classifier's decision boundary, CUBIC identifies concepts that significantly influence model predictions. Our experiments demonstrate that CUBIC effectively uncovers previously unknown biases using Vision-Language Models (VLMs) without requiring the samples in the dataset where the classifier underperforms or prior knowledge of potential biases.
Extracting PAC Decision Trees from Black Box Binary Classifiers: The Gender Bias Study Case on BERT-based Language Models
Dec 13, 2024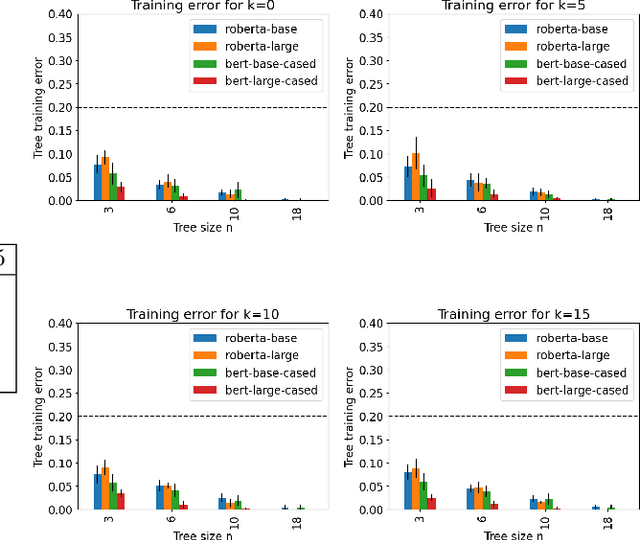
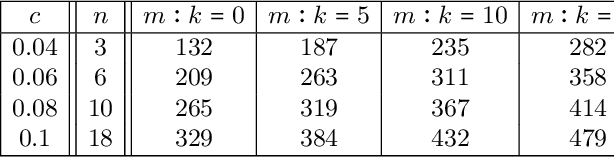
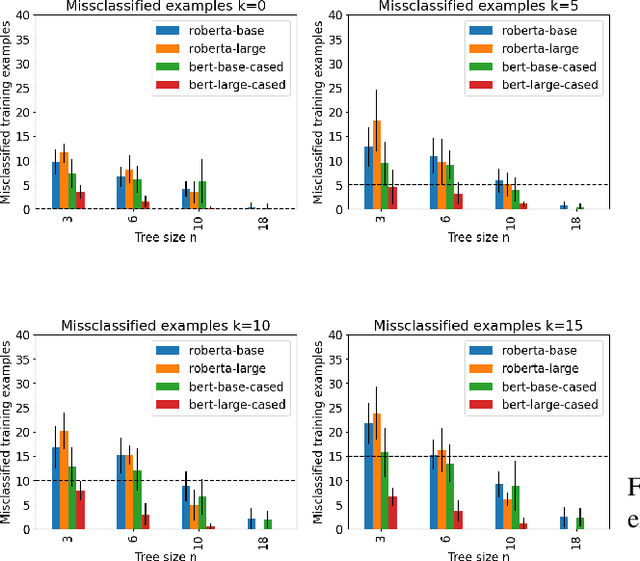

Decision trees are a popular machine learning method, known for their inherent explainability. In Explainable AI, decision trees can be used as surrogate models for complex black box AI models or as approximations of parts of such models. A key challenge of this approach is determining how accurately the extracted decision tree represents the original model and to what extent it can be trusted as an approximation of their behavior. In this work, we investigate the use of the Probably Approximately Correct (PAC) framework to provide a theoretical guarantee of fidelity for decision trees extracted from AI models. Based on theoretical results from the PAC framework, we adapt a decision tree algorithm to ensure a PAC guarantee under certain conditions. We focus on binary classification and conduct experiments where we extract decision trees from BERT-based language models with PAC guarantees. Our results indicate occupational gender bias in these models.
On the Multiple Roles of Ontologies in Explainable AI
Nov 08, 2023



This paper discusses the different roles that explicit knowledge, in particular ontologies, can play in Explainable AI and in the development of human-centric explainable systems and intelligible explanations. We consider three main perspectives in which ontologies can contribute significantly, namely reference modelling, common-sense reasoning, and knowledge refinement and complexity management. We overview some of the existing approaches in the literature, and we position them according to these three proposed perspectives. The paper concludes by discussing what challenges still need to be addressed to enable ontology-based approaches to explanation and to evaluate their human-understandability and effectiveness.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023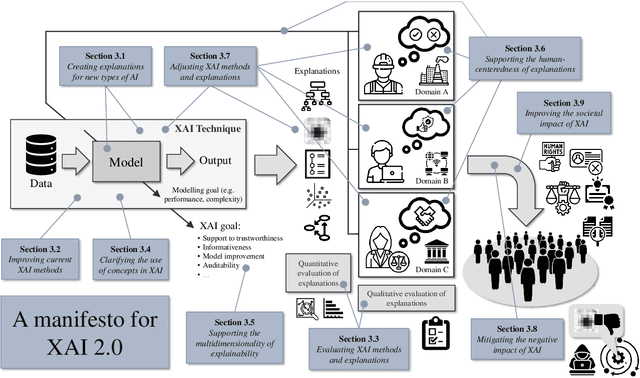
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Predicting rice blast disease: machine learning versus process based models
Apr 03, 2020
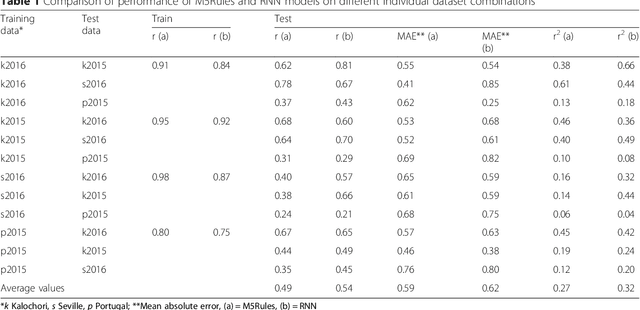

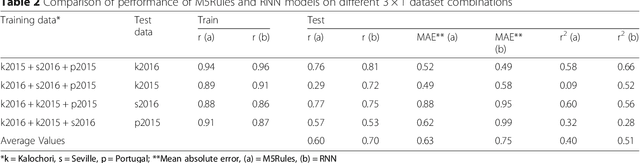
Rice is the second most important cereal crop worldwide, and the first in terms of number of people who depend on it as a major staple food. Rice blast disease is the most important biotic constraint of rice cultivation causing each year millions of dollars of losses. Despite the efforts for breeding new resistant varieties, agricultural practices and chemical control are still the most important methods for disease management. Thus, rice blast forecasting is a primary tool to support rice growers in controlling the disease. In this study, we compared four models for predicting rice blast disease, two operational process-based models (Yoshino and WARM) and two approaches based on machine learning algorithms (M5Rules and RNN), the former inducing a rule-based model and the latter building a neural network. In situ telemetry is important to obtain quality in-field data for predictive models and this was a key aspect of the RICE-GUARD project on which this study is based. According to the authors, this is the first time process-based and machine learning modelling approaches for supporting plant disease management are compared.
An Ontology-based Approach to Explaining Artificial Neural Networks
Jun 19, 2019
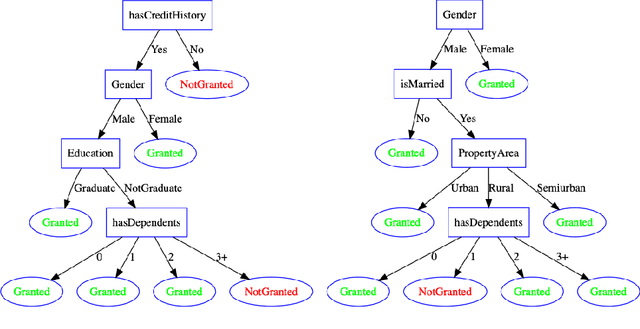
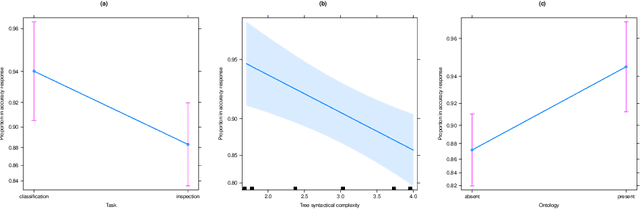
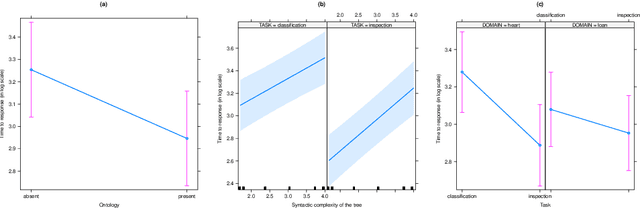
Explainability in Artificial Intelligence has been revived as a topic of active research by the need of conveying safety and trust to users in the `how' and `why' of automated decision-making. Whilst a plethora of approaches have been developed for post-hoc explainability, only a few focus on how to use domain knowledge, and how this influences the understandability of an explanation from the users' perspective. In this paper we show how ontologies help the understandability of interpretable machine learning models, such as decision trees. In particular, we build on Trepan, an algorithm that explains artificial neural networks by means of decision trees, and we extend it to include ontologies modeling domain knowledge in the process of generating explanations. We present the results of a user study that measures the understandability of decision trees in domains where explanations are critical, namely, in finance and medicine. Our study shows that decision trees taking into account domain knowledge during generation are more understandable than those generated without the use of ontologies.
Repairing Ontologies via Axiom Weakening
Nov 09, 2017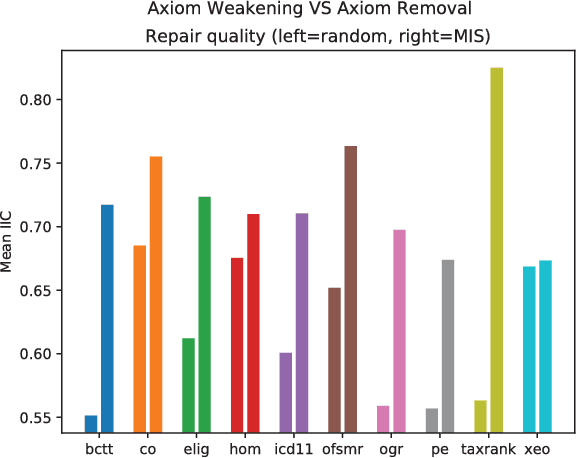
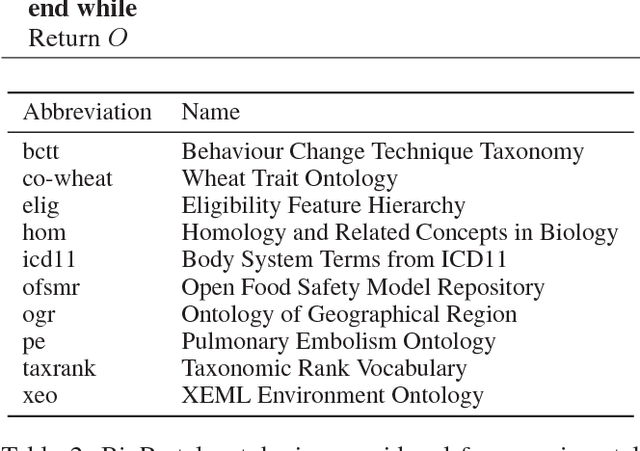
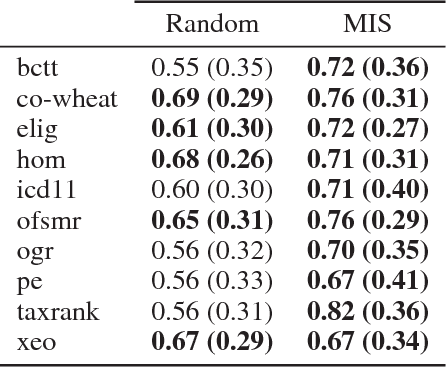
Ontology engineering is a hard and error-prone task, in which small changes may lead to errors, or even produce an inconsistent ontology. As ontologies grow in size, the need for automated methods for repairing inconsistencies while preserving as much of the original knowledge as possible increases. Most previous approaches to this task are based on removing a few axioms from the ontology to regain consistency. We propose a new method based on weakening these axioms to make them less restrictive, employing the use of refinement operators. We introduce the theoretical framework for weakening DL ontologies, propose algorithms to repair ontologies based on the framework, and provide an analysis of the computational complexity. Through an empirical analysis made over real-life ontologies, we show that our approach preserves significantly more of the original knowledge of the ontology than removing axioms.