 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Latent to Lucid: Transforming Knowledge Graph Embeddings into Interpretable Structures
Jun 03, 2024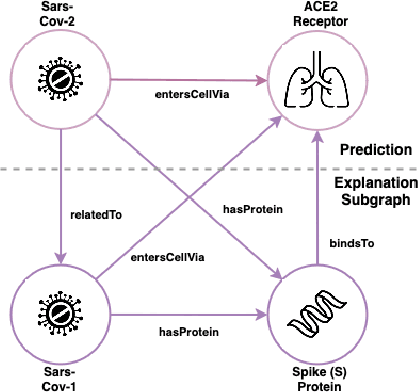

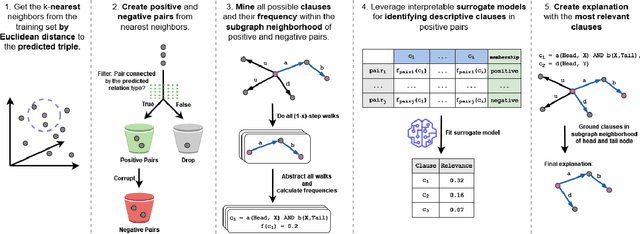
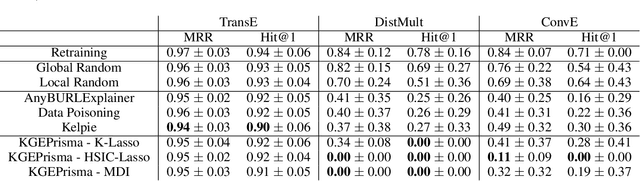
This paper introduces a post-hoc explainable AI method tailored for Knowledge Graph Embedding models. These models are essential to Knowledge Graph Completion yet criticized for their opaque, black-box nature. Despite their significant success in capturing the semantics of knowledge graphs through high-dimensional latent representations, their inherent complexity poses substantial challenges to explainability. Unlike existing methods, our approach directly decodes the latent representations encoded by Knowledge Graph Embedding models, leveraging the principle that similar embeddings reflect similar behaviors within the Knowledge Graph. By identifying distinct structures within the subgraph neighborhoods of similarly embedded entities, our method identifies the statistical regularities on which the models rely and translates these insights into human-understandable symbolic rules and facts. This bridges the gap between the abstract representations of Knowledge Graph Embedding models and their predictive outputs, offering clear, interpretable insights. Key contributions include a novel post-hoc explainable AI method for Knowledge Graph Embedding models that provides immediate, faithful explanations without retraining, facilitating real-time application even on large-scale knowledge graphs. The method's flexibility enables the generation of rule-based, instance-based, and analogy-based explanations, meeting diverse user needs. Extensive evaluations show our approach's effectiveness in delivering faithful and well-localized explanations, enhancing the transparency and trustworthiness of Knowledge Graph Embedding models.
The Next Big Thing in Unsupervised Machine Learning: Five Lessons from Infant Learning
Sep 17, 2020After a surge in popularity of supervised Deep Learning, the desire to reduce the dependence on curated, labelled data sets and to leverage the vast quantities of unlabelled data available recently triggered renewed interest in unsupervised learning algorithms. Despite a significantly improved performance due to approaches such as the identification of disentangled latent representations, contrastive learning, and clustering optimisations, the performance of unsupervised machine learning still falls short of its hypothesised potential. Machine learning has previously taken inspiration from neuroscience and cognitive science with great success. However, this has mostly been based on adult learners with access to labels and a vast amount of prior knowledge. In order to push unsupervised machine learning forward, we argue that developmental science of infant cognition might hold the key to unlocking the next generation of unsupervised learning approaches. Conceptually, human infant learning is the closest biological parallel to artificial unsupervised learning, as infants too must learn useful representations from unlabelled data. In contrast to machine learning, these new representations are learned rapidly and from relatively few examples. Moreover, infants learn robust representations that can be used flexibly and efficiently in a number of different tasks and contexts. We identify five crucial factors enabling infants' quality and speed of learning, assess the extent to which these have already been exploited in machine learning, and propose how further adoption of these factors can give rise to previously unseen performance levels in unsupervised learning.
An Ontology-based Approach to Explaining Artificial Neural Networks
Jun 19, 2019
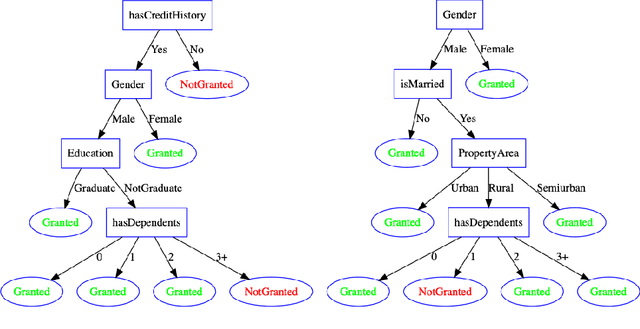
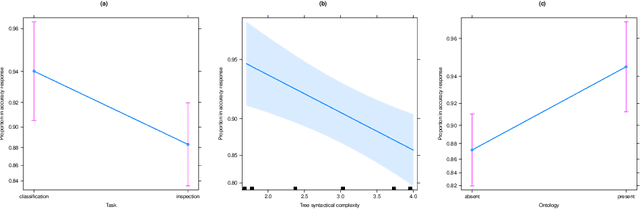
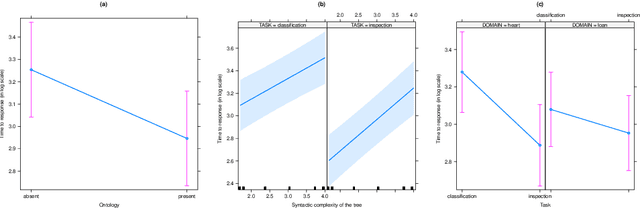
Explainability in Artificial Intelligence has been revived as a topic of active research by the need of conveying safety and trust to users in the `how' and `why' of automated decision-making. Whilst a plethora of approaches have been developed for post-hoc explainability, only a few focus on how to use domain knowledge, and how this influences the understandability of an explanation from the users' perspective. In this paper we show how ontologies help the understandability of interpretable machine learning models, such as decision trees. In particular, we build on Trepan, an algorithm that explains artificial neural networks by means of decision trees, and we extend it to include ontologies modeling domain knowledge in the process of generating explanations. We present the results of a user study that measures the understandability of decision trees in domains where explanations are critical, namely, in finance and medicine. Our study shows that decision trees taking into account domain knowledge during generation are more understandable than those generated without the use of ontologies.
The What, the Why, and the How of Artificial Explanations in Automated Decision-Making
Aug 21, 2018The increasing incorporation of Artificial Intelligence in the form of automated systems into decision-making procedures highlights not only the importance of decision theory for automated systems but also the need for these decision procedures to be explainable to the people involved in them. Traditional realist accounts of explanation, wherein explanation is a relation that holds (or does not hold) eternally between an explanans and an explanandum, are not adequate to account for the notion of explanation required for artificial decision procedures. We offer an alternative account of explanation as used in the context of automated decision-making that makes explanation an epistemic phenomenon, and one that is dependent on context. This account of explanation better accounts for the way that we talk about, and use, explanations and derived concepts, such as `explanatory power', and also allows us to differentiate between reasons or causes on the one hand, which do not need to have an epistemic aspect, and explanations on the other, which do have such an aspect. Against this theoretical backdrop we then review existing approaches to explanation in Artificial Intelligence and Machine Learning, and suggest desiderata which truly explainable decision systems should fulfill.
Neural-Symbolic Learning and Reasoning: A Survey and Interpretation
Nov 10, 2017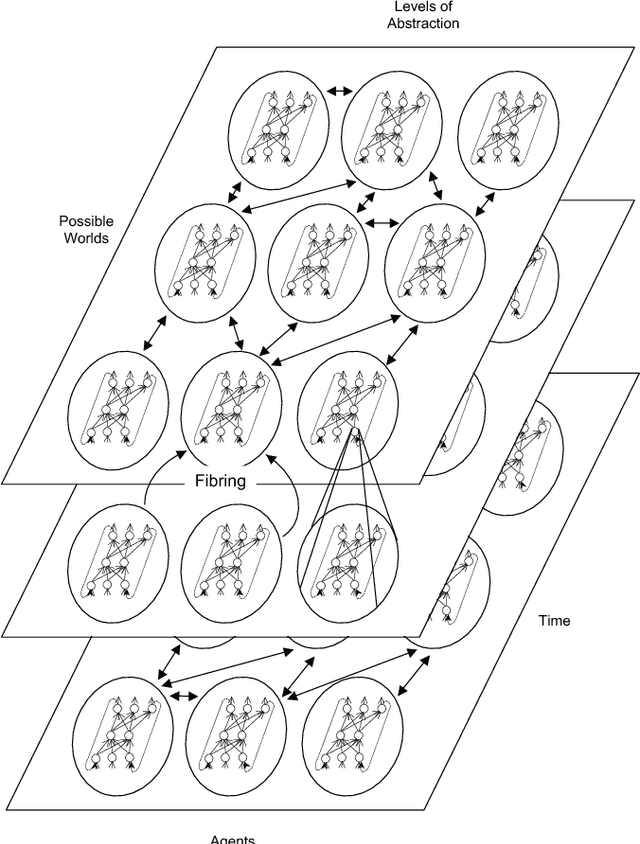

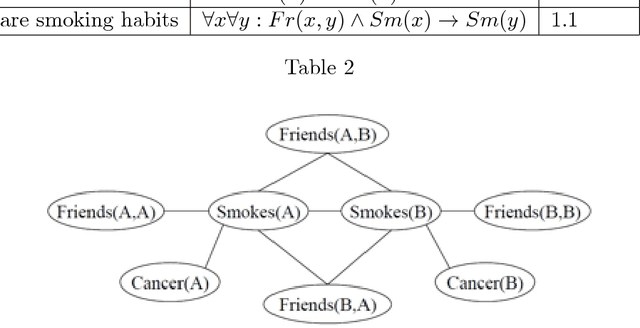
The study and understanding of human behaviour is relevant to computer science, artificial intelligence, neural computation, cognitive science, philosophy, psychology, and several other areas. Presupposing cognition as basis of behaviour, among the most prominent tools in the modelling of behaviour are computational-logic systems, connectionist models of cognition, and models of uncertainty. Recent studies in cognitive science, artificial intelligence, and psychology have produced a number of cognitive models of reasoning, learning, and language that are underpinned by computation. In addition, efforts in computer science research have led to the development of cognitive computational systems integrating machine learning and automated reasoning. Such systems have shown promise in a range of applications, including computational biology, fault diagnosis, training and assessment in simulators, and software verification. This joint survey reviews the personal ideas and views of several researchers on neural-symbolic learning and reasoning. The article is organised in three parts: Firstly, we frame the scope and goals of neural-symbolic computation and have a look at the theoretical foundations. We then proceed to describe the realisations of neural-symbolic computation, systems, and applications. Finally we present the challenges facing the area and avenues for further research.
What Does Explainable AI Really Mean? A New Conceptualization of Perspectives
Oct 02, 2017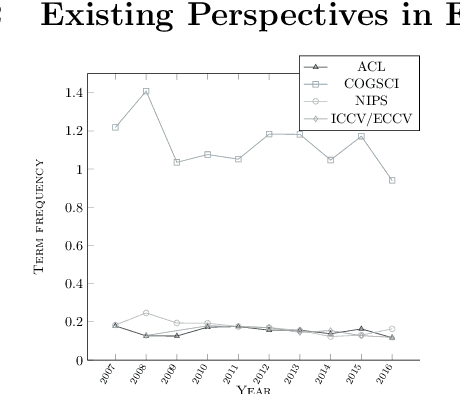
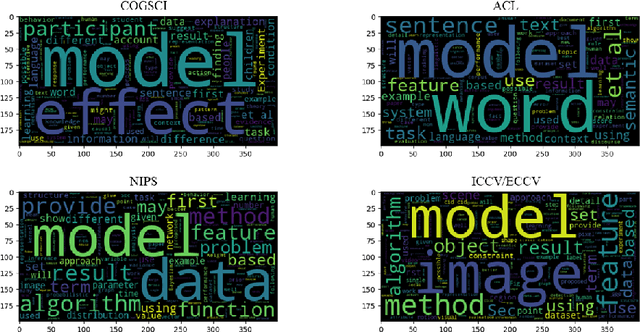
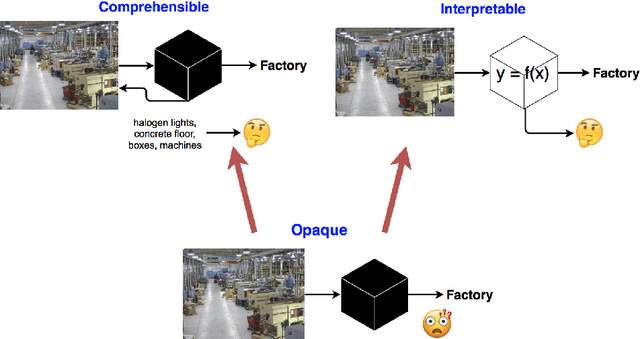
We characterize three notions of explainable AI that cut across research fields: opaque systems that offer no insight into its algo- rithmic mechanisms; interpretable systems where users can mathemat- ically analyze its algorithmic mechanisms; and comprehensible systems that emit symbols enabling user-driven explanations of how a conclusion is reached. The paper is motivated by a corpus analysis of NIPS, ACL, COGSCI, and ICCV/ECCV paper titles showing differences in how work on explainable AI is positioned in various fields. We close by introducing a fourth notion: truly explainable systems, where automated reasoning is central to output crafted explanations without requiring human post processing as final step of the generative process.
Reasoning in Non-Probabilistic Uncertainty: Logic Programming and Neural-Symbolic Computing as Examples
Mar 01, 2017



This article aims to achieve two goals: to show that probability is not the only way of dealing with uncertainty (and even more, that there are kinds of uncertainty which are for principled reasons not addressable with probabilistic means); and to provide evidence that logic-based methods can well support reasoning with uncertainty. For the latter claim, two paradigmatic examples are presented: Logic Programming with Kleene semantics for modelling reasoning from information in a discourse, to an interpretation of the state of affairs of the intended model, and a neural-symbolic implementation of Input/Output logic for dealing with uncertainty in dynamic normative contexts.
Efficient Dodgson-Score Calculation Using Heuristics and Parallel Computing
Aug 09, 2016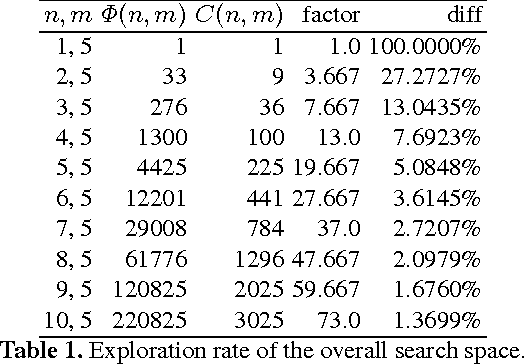
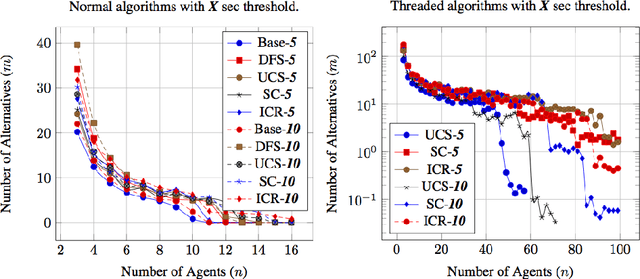
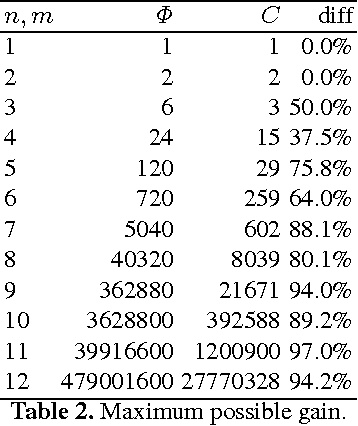
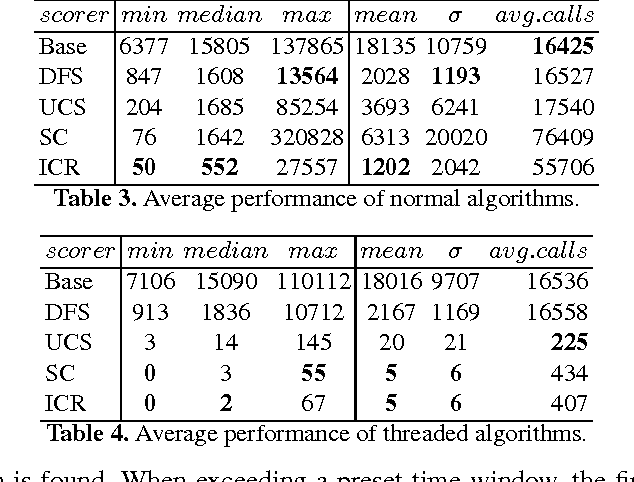
Conflict of interest is the permanent companion of any population of agents (computational or biological). For that reason, the ability to compromise is of paramount importance, making voting a key element of societal mechanisms. One of the voting procedures most often discussed in the literature and, due to its intuitiveness, also conceptually quite appealing is Charles Dodgson's scoring rule, basically using the respective closeness to being a Condorcet winner for evaluating competing alternatives. In this paper, we offer insights on the practical limits of algorithms computing the exact Dodgson scores from a number of votes. While the problem itself is theoretically intractable, this work proposes and analyses five different solutions which try distinct approaches to practically solve the issue in an effective manner. Additionally, three of the discussed procedures can be run in parallel which has the potential of drastically reducing the problem size.