 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Analogy between Human Brain and LLMs: Spotting Key Neurons in Grammar Perception
Nov 09, 2025Artificial Neural Networks, the building blocks of AI, were inspired by the human brain's network of neurons. Over the years, these networks have evolved to replicate the complex capabilities of the brain, allowing them to handle tasks such as image and language processing. In the realm of Large Language Models, there has been a keen interest in making the language learning process more akin to that of humans. While neuroscientific research has shown that different grammatical categories are processed by different neurons in the brain, we show that LLMs operate in a similar way. Utilizing Llama 3, we identify the most important neurons associated with the prediction of words belonging to different part-of-speech tags. Using the achieved knowledge, we train a classifier on a dataset, which shows that the activation patterns of these key neurons can reliably predict part-of-speech tags on fresh data. The results suggest the presence of a subspace in LLMs focused on capturing part-of-speech tag concepts, resembling patterns observed in lesion studies of the brain in neuroscience.
An Ontology for Representing Curriculum and Learning Material
Jun 06, 2025Educational, learning, and training materials have become extremely commonplace across the Internet. Yet, they frequently remain disconnected from each other, fall into platform silos, and so on. One way to overcome this is to provide a mechanism to integrate the material and provide cross-links across topics. In this paper, we present the Curriculum KG Ontology, which we use as a framework for the dense interlinking of educational materials, by first starting with organizational and broad pedagogical principles. We provide a materialized graph for the Prototype Open Knowledge Network use-case, and validate it using competency questions sourced from domain experts and educators.
Building Knowledge Graphs Towards a Global Food Systems Datahub
Feb 26, 2025Sustainable agricultural production aligns with several sustainability goals established by the United Nations (UN). However, there is a lack of studies that comprehensively examine sustainable agricultural practices across various products and production methods. Such research could provide valuable insights into the diverse factors influencing the sustainability of specific crops and produce while also identifying practices and conditions that are universally applicable to all forms of agricultural production. While this research might help us better understand sustainability, the community would still need a consistent set of vocabularies. These consistent vocabularies, which represent the underlying datasets, can then be stored in a global food systems datahub. The standardized vocabularies might help encode important information for further statistical analyses and AI/ML approaches in the datasets, resulting in the research targeting sustainable agricultural production. A structured method of representing information in sustainability, especially for wheat production, is currently unavailable. In an attempt to address this gap, we are building a set of ontologies and Knowledge Graphs (KGs) that encode knowledge associated with sustainable wheat production using formal logic. The data for this set of knowledge graphs are collected from public data sources, experimental results collected at our experiments at Kansas State University, and a Sustainability Workshop that we organized earlier in the year, which helped us collect input from different stakeholders throughout the value chain of wheat. The modeling of the ontology (i.e., the schema) for the Knowledge Graph has been in progress with the help of our domain experts, following a modular structure using KNARM methodology. In this paper, we will present our preliminary results and schemas of our Knowledge Graph and ontologies.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Accelerating Knowledge Graph and Ontology Engineering with Large Language Models
Nov 14, 2024Large Language Models bear the promise of significant acceleration of key Knowledge Graph and Ontology Engineering tasks, including ontology modeling, extension, modification, population, alignment, as well as entity disambiguation. We lay out LLM-based Knowledge Graph and Ontology Engineering as a new and coming area of research, and argue that modular approaches to ontologies will be of central importance.
Ontology Population using LLMs
Nov 03, 2024Knowledge graphs (KGs) are increasingly utilized for data integration, representation, and visualization. While KG population is critical, it is often costly, especially when data must be extracted from unstructured text in natural language, which presents challenges, such as ambiguity and complex interpretations. Large Language Models (LLMs) offer promising capabilities for such tasks, excelling in natural language understanding and content generation. However, their tendency to ``hallucinate'' can produce inaccurate outputs. Despite these limitations, LLMs offer rapid and scalable processing of natural language data, and with prompt engineering and fine-tuning, they can approximate human-level performance in extracting and structuring data for KGs. This study investigates LLM effectiveness for the KG population, focusing on the Enslaved.org Hub Ontology. In this paper, we report that compared to the ground truth, LLM's can extract ~90% of triples, when provided a modular ontology as guidance in the prompts.
The S2 Hierarchical Discrete Global Grid as a Nexus for Data Representation, Integration, and Querying Across Geospatial Knowledge Graphs
Oct 18, 2024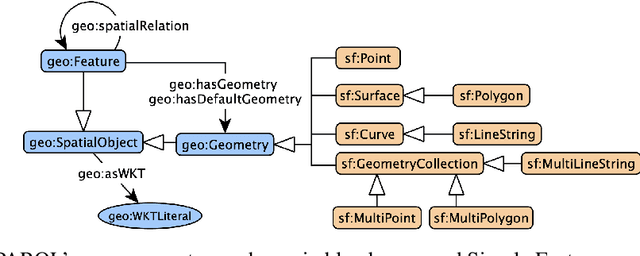


Geospatial Knowledge Graphs (GeoKGs) have become integral to the growing field of Geospatial Artificial Intelligence. Initiatives like the U.S. National Science Foundation's Open Knowledge Network program aim to create an ecosystem of nation-scale, cross-disciplinary GeoKGs that provide AI-ready geospatial data aligned with FAIR principles. However, building this infrastructure presents key challenges, including 1) managing large volumes of data, 2) the computational complexity of discovering topological relations via SPARQL, and 3) conflating multi-scale raster and vector data. Discrete Global Grid Systems (DGGS) help tackle these issues by offering efficient data integration and representation strategies. The KnowWhereGraph utilizes Google's S2 Geometry -- a DGGS framework -- to enable efficient multi-source data processing, qualitative spatial querying, and cross-graph integration. This paper outlines the implementation of S2 within KnowWhereGraph, emphasizing its role in topologically enriching and semantically compressing data. Ultimately, this work demonstrates the potential of DGGS frameworks, particularly S2, for building scalable GeoKGs.
The KnowWhereGraph Ontology
Oct 17, 2024



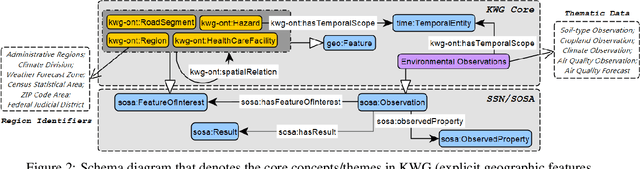
KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
ConceptLens: from Pixels to Understanding
Oct 04, 2024ConceptLens is an innovative tool designed to illuminate the intricate workings of deep neural networks (DNNs) by visualizing hidden neuron activations. By integrating deep learning with symbolic methods, ConceptLens offers users a unique way to understand what triggers neuron activations and how they respond to various stimuli. The tool uses error-margin analysis to provide insights into the confidence levels of neuron activations, thereby enhancing the interpretability of DNNs. This paper presents an overview of ConceptLens, its implementation, and its application in real-time visualization of neuron activations and error margins through bar charts.
Knowledge in Triples for LLMs: Enhancing Table QA Accuracy with Semantic Extraction
Sep 21, 2024Integrating structured knowledge from tabular formats poses significant challenges within natural language processing (NLP), mainly when dealing with complex, semi-structured tables like those found in the FeTaQA dataset. These tables require advanced methods to interpret and generate meaningful responses accurately. Traditional approaches, such as SQL and SPARQL, often fail to fully capture the semantics of such data, especially in the presence of irregular table structures like web tables. This paper addresses these challenges by proposing a novel approach that extracts triples straightforward from tabular data and integrates it with a retrieval-augmented generation (RAG) model to enhance the accuracy, coherence, and contextual richness of responses generated by a fine-tuned GPT-3.5-turbo-0125 model. Our approach significantly outperforms existing baselines on the FeTaQA dataset, particularly excelling in Sacre-BLEU and ROUGE metrics. It effectively generates contextually accurate and detailed long-form answers from tables, showcasing its strength in complex data interpretation.