 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ontology for Representing Curriculum and Learning Material
Jun 06, 2025Educational, learning, and training materials have become extremely commonplace across the Internet. Yet, they frequently remain disconnected from each other, fall into platform silos, and so on. One way to overcome this is to provide a mechanism to integrate the material and provide cross-links across topics. In this paper, we present the Curriculum KG Ontology, which we use as a framework for the dense interlinking of educational materials, by first starting with organizational and broad pedagogical principles. We provide a materialized graph for the Prototype Open Knowledge Network use-case, and validate it using competency questions sourced from domain experts and educators.
Ontology Population using LLMs
Nov 03, 2024Knowledge graphs (KGs) are increasingly utilized for data integration, representation, and visualization. While KG population is critical, it is often costly, especially when data must be extracted from unstructured text in natural language, which presents challenges, such as ambiguity and complex interpretations. Large Language Models (LLMs) offer promising capabilities for such tasks, excelling in natural language understanding and content generation. However, their tendency to ``hallucinate'' can produce inaccurate outputs. Despite these limitations, LLMs offer rapid and scalable processing of natural language data, and with prompt engineering and fine-tuning, they can approximate human-level performance in extracting and structuring data for KGs. This study investigates LLM effectiveness for the KG population, focusing on the Enslaved.org Hub Ontology. In this paper, we report that compared to the ground truth, LLM's can extract ~90% of triples, when provided a modular ontology as guidance in the prompts.
The S2 Hierarchical Discrete Global Grid as a Nexus for Data Representation, Integration, and Querying Across Geospatial Knowledge Graphs
Oct 18, 2024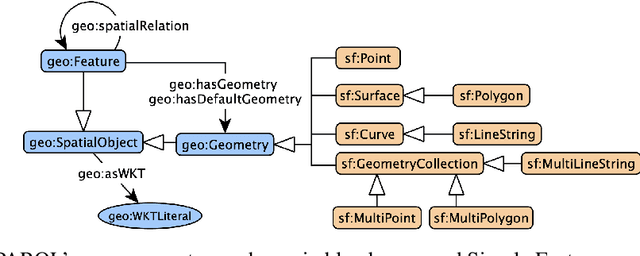


Geospatial Knowledge Graphs (GeoKGs) have become integral to the growing field of Geospatial Artificial Intelligence. Initiatives like the U.S. National Science Foundation's Open Knowledge Network program aim to create an ecosystem of nation-scale, cross-disciplinary GeoKGs that provide AI-ready geospatial data aligned with FAIR principles. However, building this infrastructure presents key challenges, including 1) managing large volumes of data, 2) the computational complexity of discovering topological relations via SPARQL, and 3) conflating multi-scale raster and vector data. Discrete Global Grid Systems (DGGS) help tackle these issues by offering efficient data integration and representation strategies. The KnowWhereGraph utilizes Google's S2 Geometry -- a DGGS framework -- to enable efficient multi-source data processing, qualitative spatial querying, and cross-graph integration. This paper outlines the implementation of S2 within KnowWhereGraph, emphasizing its role in topologically enriching and semantically compressing data. Ultimately, this work demonstrates the potential of DGGS frameworks, particularly S2, for building scalable GeoKGs.
The KnowWhereGraph Ontology
Oct 17, 2024



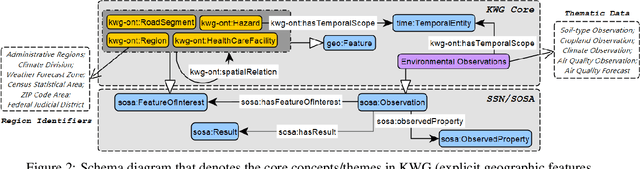
KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.