 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ontology for Representing Curriculum and Learning Material
Jun 06, 2025Educational, learning, and training materials have become extremely commonplace across the Internet. Yet, they frequently remain disconnected from each other, fall into platform silos, and so on. One way to overcome this is to provide a mechanism to integrate the material and provide cross-links across topics. In this paper, we present the Curriculum KG Ontology, which we use as a framework for the dense interlinking of educational materials, by first starting with organizational and broad pedagogical principles. We provide a materialized graph for the Prototype Open Knowledge Network use-case, and validate it using competency questions sourced from domain experts and educators.
Education in the Era of Neurosymbolic AI
Nov 16, 2024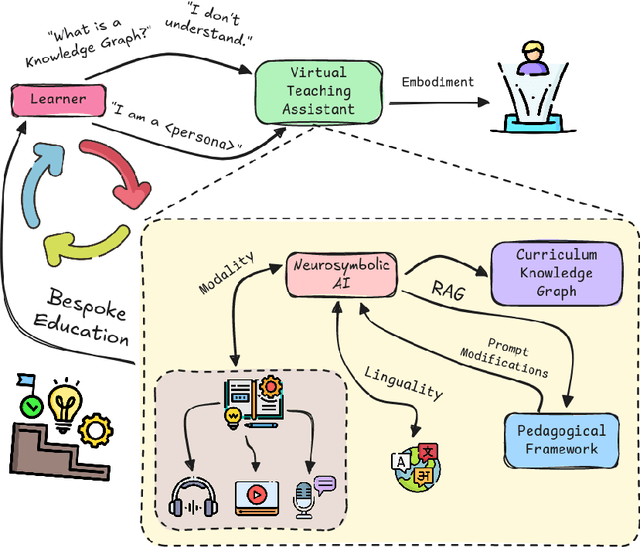
Education is poised for a transformative shift with the advent of neurosymbolic artificial intelligence (NAI), which will redefine how we support deeply adaptive and personalized learning experiences. NAI-powered education systems will be capable of interpreting complex human concepts and contexts while employing advanced problem-solving strategies, all grounded in established pedagogical frameworks. This will enable a level of personalization in learning systems that to date has been largely unattainable at scale, providing finely tailored curricula that adapt to an individual's learning pace and accessibility needs, including the diagnosis of student understanding of subjects at a fine-grained level, identifying gaps in foundational knowledge, and adjusting instruction accordingly. In this paper, we propose a system that leverages the unique affordances of pedagogical agents -- embodied characters designed to enhance learning -- as critical components of a hybrid NAI architecture. To do so, these agents can thus simulate nuanced discussions, debates, and problem-solving exercises that push learners beyond rote memorization toward deep comprehension. We discuss the rationale for our system design and the preliminary findings of our work. We conclude that education in the era of NAI will make learning more accessible, equitable, and aligned with real-world skills. This is an era that will explore a new depth of understanding in educational tools.
Accelerating Knowledge Graph and Ontology Engineering with Large Language Models
Nov 14, 2024Large Language Models bear the promise of significant acceleration of key Knowledge Graph and Ontology Engineering tasks, including ontology modeling, extension, modification, population, alignment, as well as entity disambiguation. We lay out LLM-based Knowledge Graph and Ontology Engineering as a new and coming area of research, and argue that modular approaches to ontologies will be of central importance.
Ontology Population using LLMs
Nov 03, 2024Knowledge graphs (KGs) are increasingly utilized for data integration, representation, and visualization. While KG population is critical, it is often costly, especially when data must be extracted from unstructured text in natural language, which presents challenges, such as ambiguity and complex interpretations. Large Language Models (LLMs) offer promising capabilities for such tasks, excelling in natural language understanding and content generation. However, their tendency to ``hallucinate'' can produce inaccurate outputs. Despite these limitations, LLMs offer rapid and scalable processing of natural language data, and with prompt engineering and fine-tuning, they can approximate human-level performance in extracting and structuring data for KGs. This study investigates LLM effectiveness for the KG population, focusing on the Enslaved.org Hub Ontology. In this paper, we report that compared to the ground truth, LLM's can extract ~90% of triples, when provided a modular ontology as guidance in the prompts.
The S2 Hierarchical Discrete Global Grid as a Nexus for Data Representation, Integration, and Querying Across Geospatial Knowledge Graphs
Oct 18, 2024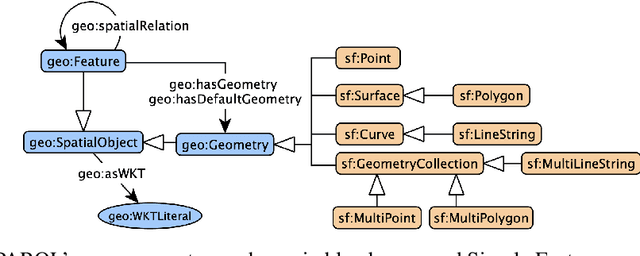


Geospatial Knowledge Graphs (GeoKGs) have become integral to the growing field of Geospatial Artificial Intelligence. Initiatives like the U.S. National Science Foundation's Open Knowledge Network program aim to create an ecosystem of nation-scale, cross-disciplinary GeoKGs that provide AI-ready geospatial data aligned with FAIR principles. However, building this infrastructure presents key challenges, including 1) managing large volumes of data, 2) the computational complexity of discovering topological relations via SPARQL, and 3) conflating multi-scale raster and vector data. Discrete Global Grid Systems (DGGS) help tackle these issues by offering efficient data integration and representation strategies. The KnowWhereGraph utilizes Google's S2 Geometry -- a DGGS framework -- to enable efficient multi-source data processing, qualitative spatial querying, and cross-graph integration. This paper outlines the implementation of S2 within KnowWhereGraph, emphasizing its role in topologically enriching and semantically compressing data. Ultimately, this work demonstrates the potential of DGGS frameworks, particularly S2, for building scalable GeoKGs.
The KnowWhereGraph Ontology
Oct 17, 2024



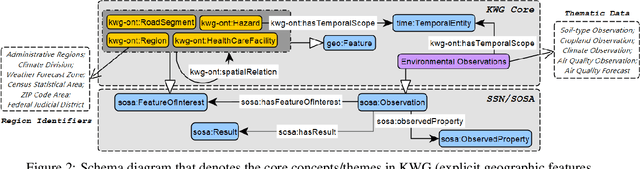
KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
Commonsense Ontology Micropatterns
Feb 28, 2024The previously introduced Modular Ontology Modeling methodology (MOMo) attempts to mimic the human analogical process by using modular patterns to assemble more complex concepts. To support this, MOMo organizes organizes ontology design patterns into design libraries, which are programmatically queryable, to support accelerated ontology development, for both human and automated processes. However, a major bottleneck to large-scale deployment of MOMo is the (to-date) limited availability of ready-to-use ontology design patterns. At the same time, Large Language Models have quickly become a source of common knowledge and, in some cases, replacing search engines for questions. In this paper, we thus present a collection of 104 ontology design patterns representing often occurring nouns, curated from the common-sense knowledge available in LLMs, organized into a fully-annotated modular ontology design library ready for use with MOMo.
A Modular Ontology for MODS -- Metadata Object Description Schema
Jul 31, 2023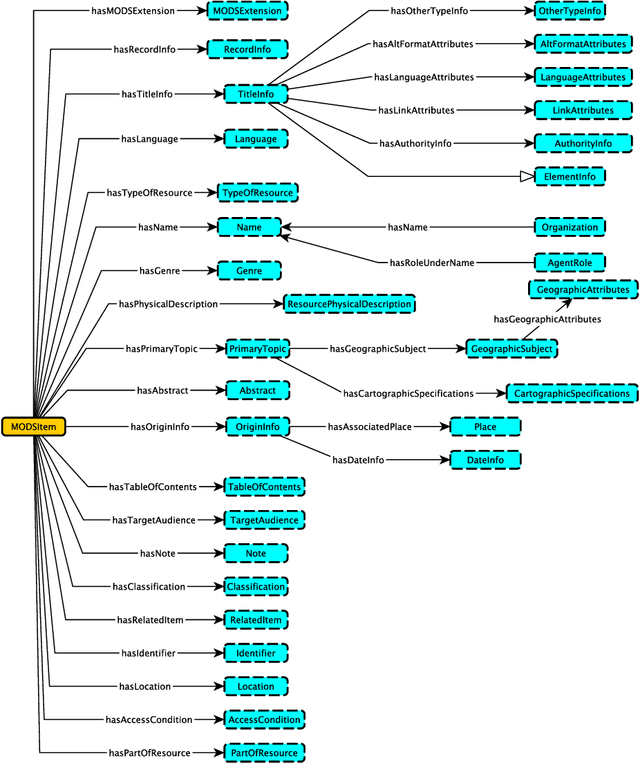
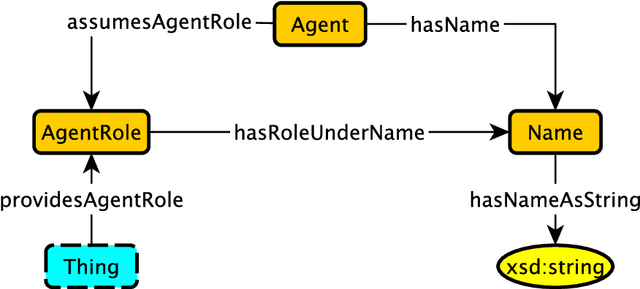
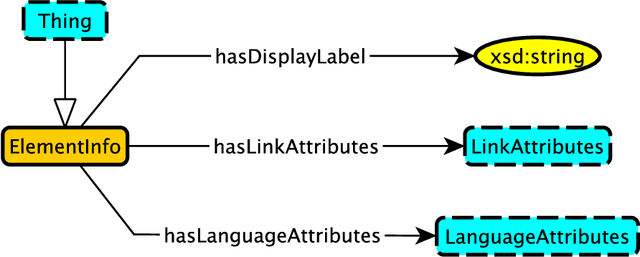
The Metadata Object Description Schema (MODS) was developed to describe bibliographic concepts and metadata and is maintained by the Library of Congress. Its authoritative version is given as an XML schema based on an XML mindset which means that it has significant limitations for use in a knowledge graphs context. We have therefore developed the Modular MODS Ontology (MMODS-O) which incorporates all elements and attributes of the MODS XML schema. In designing the ontology, we adopt the recent Modular Ontology Design Methodology (MOMo) with the intention to strike a balance between modularity and quality ontology design on the one hand, and conservative backward compatibility with MODS on the other.
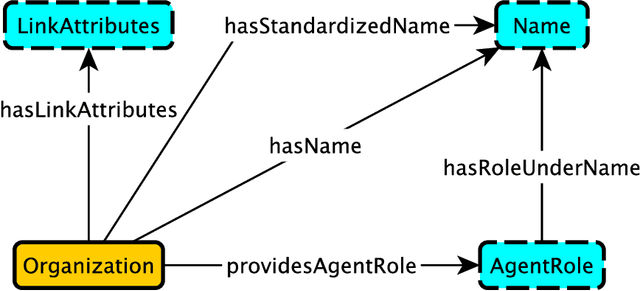
An Ontology Design Pattern for Role-Dependent Names
May 03, 2023We present an ontology design pattern for modeling Names as part of Roles, to capture scenarios where an Agent performs different Roles using different Names associated with the different Roles. Examples of an Agent performing a Role using different Names are rather ubiquitous, e.g., authors who write under different pseudonyms, or different legal names for citizens of more than one country. The proposed pattern is a modified merger of a standard Agent Role and a standard Name pattern stub.
Ontology Design Facilitating Wikibase Integration -- and a Worked Example for Historical Data
May 27, 2022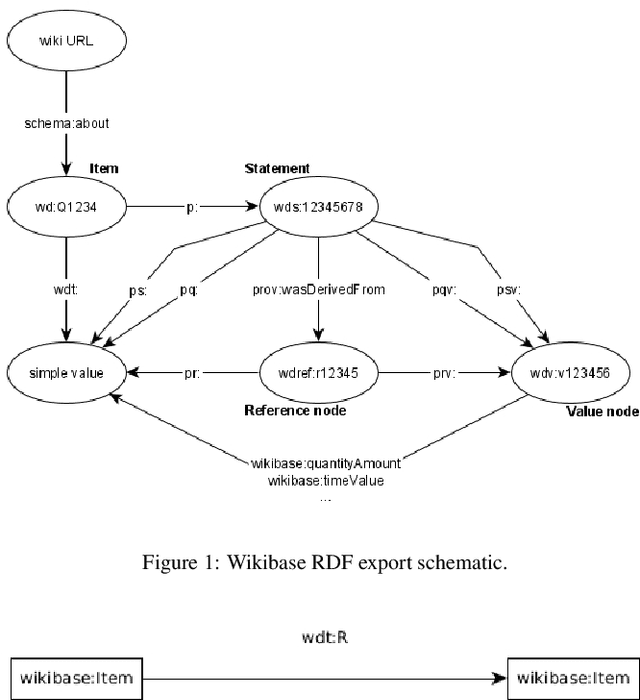
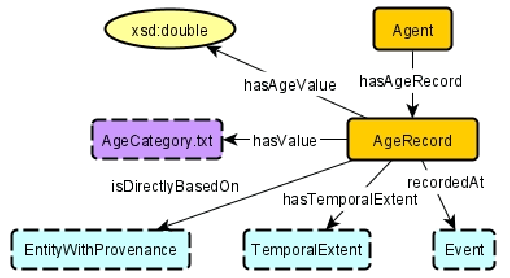
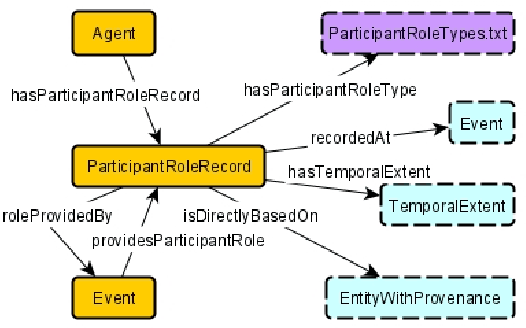
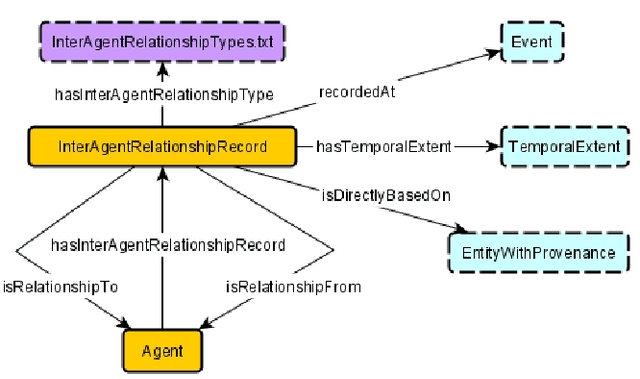
Wikibase -- which is the software underlying Wikidata -- is a powerful platform for knowledge graph creation and management. However, it has been developed with a crowd-sourced knowledge graph creation scenario in mind, which in particular means that it has not been designed for use case scenarios in which a tightly controlled high-quality schema, in the form of an ontology, is to be imposed, and indeed, independently developed ontologies do not necessarily map seamlessly to the Wikibase approach. In this paper, we provide the key ingredients needed in order to combine traditional ontology modeling with use of the Wikibase platform, namely a set of \emph{axiom} patterns that bridge the paradigm gap, together with usage instructions and a worked example for historical data.