 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology Population using LLMs
Nov 03, 2024Knowledge graphs (KGs) are increasingly utilized for data integration, representation, and visualization. While KG population is critical, it is often costly, especially when data must be extracted from unstructured text in natural language, which presents challenges, such as ambiguity and complex interpretations. Large Language Models (LLMs) offer promising capabilities for such tasks, excelling in natural language understanding and content generation. However, their tendency to ``hallucinate'' can produce inaccurate outputs. Despite these limitations, LLMs offer rapid and scalable processing of natural language data, and with prompt engineering and fine-tuning, they can approximate human-level performance in extracting and structuring data for KGs. This study investigates LLM effectiveness for the KG population, focusing on the Enslaved.org Hub Ontology. In this paper, we report that compared to the ground truth, LLM's can extract ~90% of triples, when provided a modular ontology as guidance in the prompts.
Commonsense Ontology Micropatterns
Feb 28, 2024The previously introduced Modular Ontology Modeling methodology (MOMo) attempts to mimic the human analogical process by using modular patterns to assemble more complex concepts. To support this, MOMo organizes organizes ontology design patterns into design libraries, which are programmatically queryable, to support accelerated ontology development, for both human and automated processes. However, a major bottleneck to large-scale deployment of MOMo is the (to-date) limited availability of ready-to-use ontology design patterns. At the same time, Large Language Models have quickly become a source of common knowledge and, in some cases, replacing search engines for questions. In this paper, we thus present a collection of 104 ontology design patterns representing often occurring nouns, curated from the common-sense knowledge available in LLMs, organized into a fully-annotated modular ontology design library ready for use with MOMo.
Ontology Design Facilitating Wikibase Integration -- and a Worked Example for Historical Data
May 27, 2022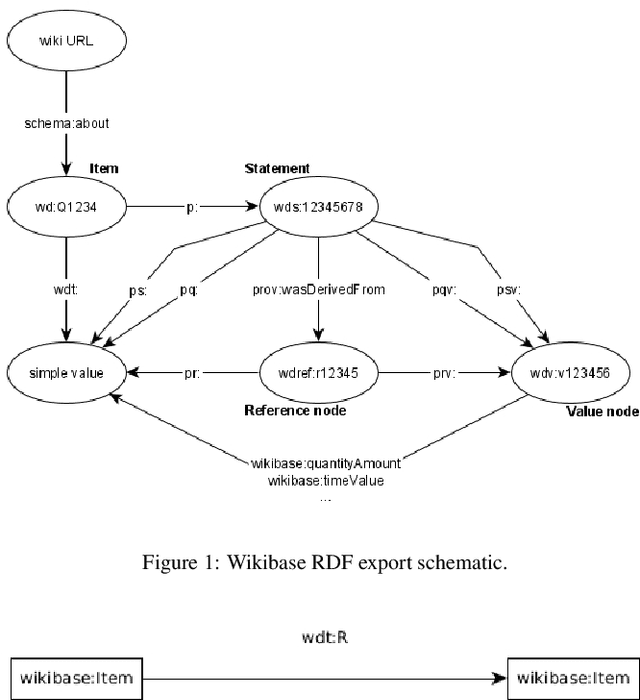
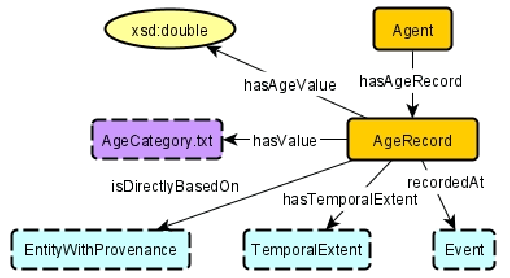
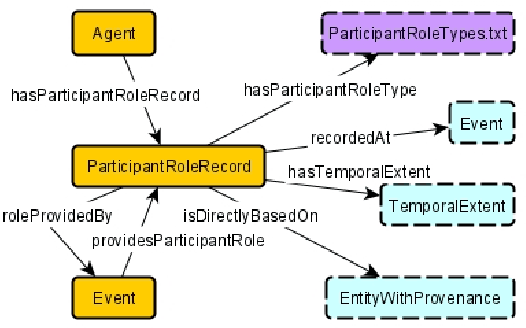
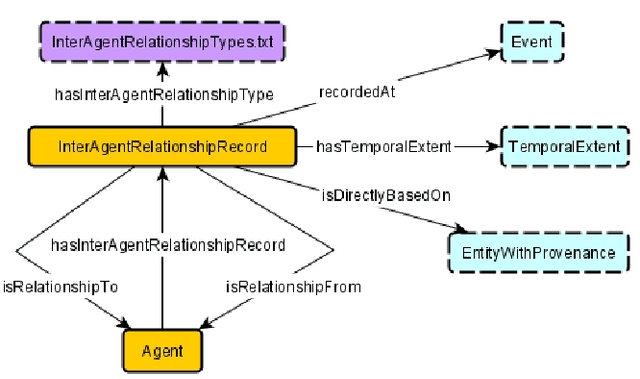
Wikibase -- which is the software underlying Wikidata -- is a powerful platform for knowledge graph creation and management. However, it has been developed with a crowd-sourced knowledge graph creation scenario in mind, which in particular means that it has not been designed for use case scenarios in which a tightly controlled high-quality schema, in the form of an ontology, is to be imposed, and indeed, independently developed ontologies do not necessarily map seamlessly to the Wikibase approach. In this paper, we provide the key ingredients needed in order to combine traditional ontology modeling with use of the Wikibase platform, namely a set of \emph{axiom} patterns that bridge the paradigm gap, together with usage instructions and a worked example for historical data.