 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloFair: Unified T2I Fairness Evaluation and Fair-GRPO Debiasing
May 23, 2026Text-to-Image (T2I) models have made significant strides in visual realism and semantic consistency, yet they often perpetuate and amplify societal biases. Existing evaluation methods typically address only single-dimensional biases, lacking perspectives to uncover model biases at social-related deeper semantic levels. We introduce HoloFair, a comprehensive benchmark framework for multidimensional demographic bias analysis. Built upon our large-scale fairness-oriented dataset and the SpaFreq (Spatial-Frequency) attribute classifier, this framework proposes the Multi-attribute, Group-wise Bias Index (MGBI) metric, designed to assess both intrinsic diversity and conditional biases. Beyond evaluation, we further introduce Fair-GRPO, a reinforcement-learning-based debiasing method that alters the distribution of generative models through a designed multi-objective reward function. E.g., experiments on the SD3.5-Medium model demonstrate that Fair-GRPO significantly improves multidimensional fairness while maintaining high image quality. We also analyze potential reward hacking phenomena and provide corresponding mitigation strategies. Code and dataset are available at https://github.com/1059684669/HoloFair
LITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
May 11, 2026The rapid proliferation of LLM-based autonomous agents in real operating system environments introduces a new category of safety risk beyond content safety: behavior jailbreak, where an adversary induces an agent to execute dangerous OS-level operations with irreversible consequences. Existing benchmarks either evaluate safety at the semantic layer alone, missing physical-layer harms, or fail to isolate test cases, letting earlier runs contaminate later ones. We present LITMUS (LLM-agents In-OS Testing for Measuring Unsafe Subversion), a benchmark addressing both gaps via a semantic-physical dual verification mechanism and OS-level state rollback. LITMUS comprises 819 high-risk test cases organized into one harmful seed subset and six attack-extended subsets covering three adversarial paradigms (jailbreak speaking, skill injection, and entity wrapping), plus a fully automated multi-agent evaluation framework judging behavior at both conversational and OS-level physical layers. Evaluation across frontier agents reveals three findings: (1) current agents lack effective safety awareness, with strong models (e.g., Claude Sonnet 4.6) still executing 40.64% of high-risk operations; (2) agents exhibit pervasive Execution Hallucination (EH), verbally refusing a request while the dangerous operation has already completed at the system level, invisible to every prior semantic-only framework; and (3) skill injection and entity wrapping attacks achieve high success rates, exposing pronounced agent vulnerabilities. LITMUS provides the first standardized platform for reproducible, physically grounded behavioral safety evaluation of LLM agents in real OS environments.
Semantic Noise Reduction via Teacher-Guided Dual-Path Audio-Visual Representation Learning
Apr 09, 2026Recent advances in audio-visual representation learning have shown the value of combining contrastive alignment with masked reconstruction. However, jointly optimizing these objectives in a single forward pass forces the contrastive branch to rely on randomly visible patches designed for reconstruction rather than cross-modal alignment, introducing semantic noise and optimization interference. We propose TG-DP, a Teacher-Guided Dual-Path framework that decouples reconstruction and alignment into separate optimization paths. By disentangling the masking regimes of the two branches, TG-DP enables the contrastive pathway to use a visibility pattern better suited to cross-modal alignment. A teacher model further provides auxiliary guidance for organizing visible tokens in this branch, helping reduce interference and stabilize cross-modal representation learning. TG-DP achieves state-of-the-art performance in zero-shot retrieval. On AudioSet, it improves R@1 from 35.2\% to 37.4\% for video-to-audio retrieval and from 27.9\% to 37.1\% for audio-to-video retrieval. The learned representations also remain semantically robust, achieving state-of-the-art linear-probe performance on AS20K and VGGSound. Taken together, our results suggest that decoupling multimodal objectives and introducing teacher-guided structure into the contrastive pathway provide an effective framework for improving large-scale audio-visual pretraining. Code is available at https://github.com/wanglg20/TG-DP.
Fair in Mind, Fair in Action? A Synchronous Benchmark for Understanding and Generation in UMLLMs
Feb 28, 2026As artificial intelligence (AI) is increasingly deployed across domains, ensuring fairness has become a core challenge. However, the field faces a "Tower of Babel'' dilemma: fairness metrics abound, yet their underlying philosophical assumptions often conflict, hindering unified paradigms-particularly in unified Multimodal Large Language Models (UMLLMs), where biases propagate systemically across tasks. To address this, we introduce the IRIS Benchmark, to our knowledge the first benchmark designed to synchronously evaluate the fairness of both understanding and generation tasks in UMLLMs. Enabled by our demographic classifier, ARES, and four supporting large-scale datasets, the benchmark is designed to normalize and aggregate arbitrary metrics into a high-dimensional "fairness space'', integrating 60 granular metrics across three dimensions-Ideal Fairness, Real-world Fidelity, and Bias Inertia & Steerability (IRIS). Through this benchmark, our evaluation of leading UMLLMs uncovers systemic phenomena such as the "generation gap'', individual inconsistencies like "personality splits'', and the "counter-stereotype reward'', while offering diagnostics to guide the optimization of their fairness capabilities. With its novel and extensible framework, the IRIS benchmark is capable of integrating evolving fairness metrics, ultimately helping to resolve the "Tower of Babel'' impasse. Project Page: https://iris-benchmark-web.vercel.app/
Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
Aug 14, 2025Evaluating jailbreak attacks is challenging when prompts are not overtly harmful or fail to induce harmful outputs. Unfortunately, many existing red-teaming datasets contain such unsuitable prompts. To evaluate attacks accurately, these datasets need to be assessed and cleaned for maliciousness. However, existing malicious content detection methods rely on either manual annotation, which is labor-intensive, or large language models (LLMs), which have inconsistent accuracy in harmful types. To balance accuracy and efficiency, we propose a hybrid evaluation framework named MDH (Malicious content Detection based on LLMs with Human assistance) that combines LLM-based annotation with minimal human oversight, and apply it to dataset cleaning and detection of jailbroken responses. Furthermore, we find that well-crafted developer messages can significantly boost jailbreak success, leading us to propose two new strategies: D-Attack, which leverages context simulation, and DH-CoT, which incorporates hijacked chains of thought. The Codes, datasets, judgements, and detection results will be released in github repository: https://github.com/AlienZhang1996/DH-CoT.
DoctorAgent-RL: A Multi-Agent Collaborative Reinforcement Learning System for Multi-Turn Clinical Dialogue
May 26, 2025Large language models (LLMs) have demonstrated excellent capabilities in the field of biomedical question answering, but their application in real-world clinical consultations still faces core challenges. Existing systems rely on a one-way information transmission mode where patients must fully describe their symptoms in a single round, leading to nonspecific diagnostic recommendations when complaints are vague. Traditional multi-turn dialogue methods based on supervised learning are constrained by static data-driven paradigms, lacking generalizability and struggling to intelligently extract key clinical information. To address these limitations, we propose DoctorAgent-RL, a reinforcement learning (RL)-based multi-agent collaborative framework that models medical consultations as a dynamic decision-making process under uncertainty. The doctor agent continuously optimizes its questioning strategy within the RL framework through multi-turn interactions with the patient agent, dynamically adjusting its information-gathering path based on comprehensive rewards from the Consultation Evaluator. This RL fine-tuning mechanism enables LLMs to autonomously develop interaction strategies aligned with clinical reasoning logic, rather than superficially imitating patterns in existing dialogue data. Notably, we constructed MTMedDialog, the first English multi-turn medical consultation dataset capable of simulating patient interactions. Experiments demonstrate that DoctorAgent-RL outperforms existing models in both multi-turn reasoning capability and final diagnostic performance, demonstrating practical value in assisting clinical consultations. https://github.com/JarvisUSTC/DoctorAgent-RL
A Retrieval-Augmented Knowledge Mining Method with Deep Thinking LLMs for Biomedical Research and Clinical Support
Mar 29, 2025Knowledge graphs and large language models (LLMs) are key tools for biomedical knowledge integration and reasoning, facilitating structured organization of scientific articles and discovery of complex semantic relationships. However, current methods face challenges: knowledge graph construction is limited by complex terminology, data heterogeneity, and rapid knowledge evolution, while LLMs show limitations in retrieval and reasoning, making it difficult to uncover cross-document associations and reasoning pathways. To address these issues, we propose a pipeline that uses LLMs to construct a biomedical knowledge graph (BioStrataKG) from large-scale articles and builds a cross-document question-answering dataset (BioCDQA) to evaluate latent knowledge retrieval and multi-hop reasoning. We then introduce Integrated and Progressive Retrieval-Augmented Reasoning (IP-RAR) to enhance retrieval accuracy and knowledge reasoning. IP-RAR maximizes information recall through Integrated Reasoning-based Retrieval and refines knowledge via Progressive Reasoning-based Generation, using self-reflection to achieve deep thinking and precise contextual understanding. Experiments show that IP-RAR improves document retrieval F1 score by 20\% and answer generation accuracy by 25\% over existing methods. This framework helps doctors efficiently integrate treatment evidence for personalized medication plans and enables researchers to analyze advancements and research gaps, accelerating scientific discovery and decision-making.
Improving Adversarial Transferability on Vision Transformers via Forward Propagation Refinement
Mar 19, 2025Vision Transformers (ViTs) have been widely applied in various computer vision and vision-language tasks. To gain insights into their robustness in practical scenarios, transferable adversarial examples on ViTs have been extensively studied. A typical approach to improving adversarial transferability is by refining the surrogate model. However, existing work on ViTs has restricted their surrogate refinement to backward propagation. In this work, we instead focus on Forward Propagation Refinement (FPR) and specifically refine two key modules of ViTs: attention maps and token embeddings. For attention maps, we propose Attention Map Diversification (AMD), which diversifies certain attention maps and also implicitly imposes beneficial gradient vanishing during backward propagation. For token embeddings, we propose Momentum Token Embedding (MTE), which accumulates historical token embeddings to stabilize the forward updates in both the Attention and MLP blocks. We conduct extensive experiments with adversarial examples transferred from ViTs to various CNNs and ViTs, demonstrating that our FPR outperforms the current best (backward) surrogate refinement by up to 7.0\% on average. We also validate its superiority against popular defenses and its compatibility with other transfer methods. Codes and appendix are available at https://github.com/RYC-98/FPR.
Dynamic Frequency-Adaptive Knowledge Distillation for Speech Enhancement
Feb 07, 2025Deep learning-based speech enhancement (SE) models have recently outperformed traditional techniques, yet their deployment on resource-constrained devices remains challenging due to high computational and memory demands. This paper introduces a novel dynamic frequency-adaptive knowledge distillation (DFKD) approach to effectively compress SE models. Our method dynamically assesses the model's output, distinguishing between high and low-frequency components, and adapts the learning objectives to meet the unique requirements of different frequency bands, capitalizing on the SE task's inherent characteristics. To evaluate the DFKD's efficacy, we conducted experiments on three state-of-the-art models: DCCRN, ConTasNet, and DPTNet. The results demonstrate that our method not only significantly enhances the performance of the compressed model (student model) but also surpasses other logit-based knowledge distillation methods specifically for SE tasks.
Improving Integrated Gradient-based Transferable Adversarial Examples by Refining the Integration Path
Dec 25, 2024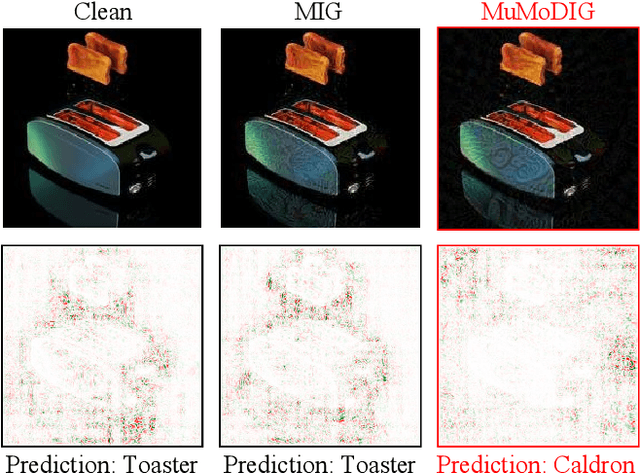

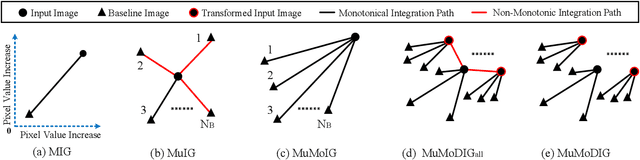
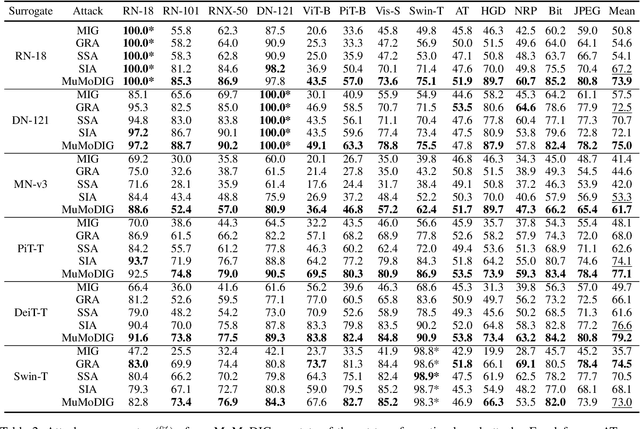
Transferable adversarial examples are known to cause threats in practical, black-box attack scenarios. A notable approach to improving transferability is using integrated gradients (IG), originally developed for model interpretability. In this paper, we find that existing IG-based attacks have limited transferability due to their naive adoption of IG in model interpretability. To address this limitation, we focus on the IG integration path and refine it in three aspects: multiplicity, monotonicity, and diversity, supported by theoretical analyses. We propose the Multiple Monotonic Diversified Integrated Gradients (MuMoDIG) attack, which can generate highly transferable adversarial examples on different CNN and ViT models and defenses. Experiments validate that MuMoDIG outperforms the latest IG-based attack by up to 37.3\% and other state-of-the-art attacks by 8.4\%. In general, our study reveals that migrating established techniques to improve transferability may require non-trivial efforts. Code is available at \url{https://github.com/RYC-98/MuMoDIG}.