 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Paper and Code
Oct 31, 2024
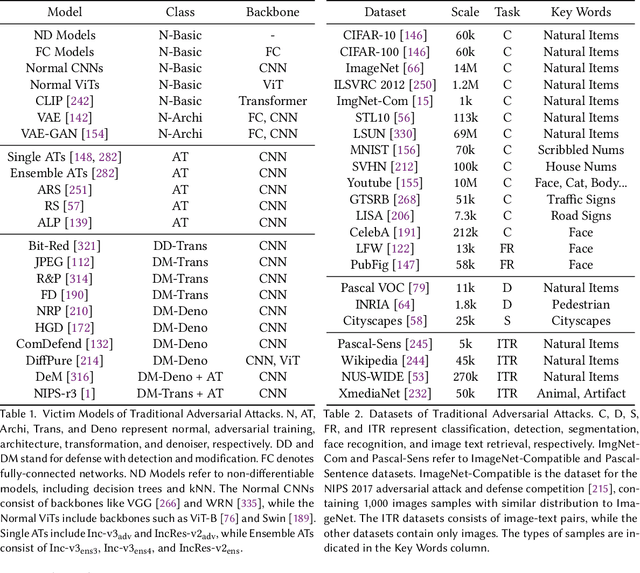


Adversarial attacks, which manipulate input data to undermine model availability and integrity, pose significant security threats during machine learning inference. With the advent of Large Vision-Language Models (LVLMs), new attack vectors, such as cognitive bias, prompt injection, and jailbreak techniques, have emerged. Understanding these attacks is crucial for developing more robust systems and demystifying the inner workings of neural networks. However, existing reviews often focus on attack classifications and lack comprehensive, in-depth analysis. The research community currently needs: 1) unified insights into adversariality, transferability, and generalization; 2) detailed evaluations of existing methods; 3) motivation-driven attack categorizations; and 4) an integrated perspective on both traditional and LVLM attacks. This article addresses these gaps by offering a thorough summary of traditional and LVLM adversarial attacks, emphasizing their connections and distinctions, and providing actionable insights for future research.