 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
Aug 14, 2025Evaluating jailbreak attacks is challenging when prompts are not overtly harmful or fail to induce harmful outputs. Unfortunately, many existing red-teaming datasets contain such unsuitable prompts. To evaluate attacks accurately, these datasets need to be assessed and cleaned for maliciousness. However, existing malicious content detection methods rely on either manual annotation, which is labor-intensive, or large language models (LLMs), which have inconsistent accuracy in harmful types. To balance accuracy and efficiency, we propose a hybrid evaluation framework named MDH (Malicious content Detection based on LLMs with Human assistance) that combines LLM-based annotation with minimal human oversight, and apply it to dataset cleaning and detection of jailbroken responses. Furthermore, we find that well-crafted developer messages can significantly boost jailbreak success, leading us to propose two new strategies: D-Attack, which leverages context simulation, and DH-CoT, which incorporates hijacked chains of thought. The Codes, datasets, judgements, and detection results will be released in github repository: https://github.com/AlienZhang1996/DH-CoT.
Adversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Oct 31, 2024


Adversarial attacks, which manipulate input data to undermine model availability and integrity, pose significant security threats during machine learning inference. With the advent of Large Vision-Language Models (LVLMs), new attack vectors, such as cognitive bias, prompt injection, and jailbreak techniques, have emerged. Understanding these attacks is crucial for developing more robust systems and demystifying the inner workings of neural networks. However, existing reviews often focus on attack classifications and lack comprehensive, in-depth analysis. The research community currently needs: 1) unified insights into adversariality, transferability, and generalization; 2) detailed evaluations of existing methods; 3) motivation-driven attack categorizations; and 4) an integrated perspective on both traditional and LVLM attacks. This article addresses these gaps by offering a thorough summary of traditional and LVLM adversarial attacks, emphasizing their connections and distinctions, and providing actionable insights for future research.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
Distilling Text Style Transfer With Self-Explanation From LLMs
Mar 02, 2024



Text Style Transfer (TST) seeks to alter the style of text while retaining its core content. Given the constraints of limited parallel datasets for TST, we propose CoTeX, a framework that leverages large language models (LLMs) alongside chain-of-thought (CoT) prompting to facilitate TST. CoTeX distills the complex rewriting and reasoning capabilities of LLMs into more streamlined models capable of working with both non-parallel and parallel data. Through experimentation across four TST datasets, CoTeX is shown to surpass traditional supervised fine-tuning and knowledge distillation methods, particularly in low-resource settings. We conduct a comprehensive evaluation, comparing CoTeX against current unsupervised, supervised, in-context learning (ICL) techniques, and instruction-tuned LLMs. Furthermore, CoTeX distinguishes itself by offering transparent explanations for its style transfer process.
SPAR: Personalized Content-Based Recommendation via Long Engagement Attention
Feb 16, 2024



Leveraging users' long engagement histories is essential for personalized content recommendations. The success of pretrained language models (PLMs) in NLP has led to their use in encoding user histories and candidate items, framing content recommendations as textual semantic matching tasks. However, existing works still struggle with processing very long user historical text and insufficient user-item interaction. In this paper, we introduce a content-based recommendation framework, SPAR, which effectively tackles the challenges of holistic user interest extraction from the long user engagement history. It achieves so by leveraging PLM, poly-attention layers and attention sparsity mechanisms to encode user's history in a session-based manner. The user and item side features are sufficiently fused for engagement prediction while maintaining standalone representations for both sides, which is efficient for practical model deployment. Moreover, we enhance user profiling by exploiting large language model (LLM) to extract global interests from user engagement history. Extensive experiments on two benchmark datasets demonstrate that our framework outperforms existing state-of-the-art (SoTA) methods.
Understanding the Instruction Mixture for Large Language Model Fine-tuning
Dec 19, 2023While instructions fine-tuning of large language models (LLMs) has been proven to enhance performance across various applications, the influence of the instruction dataset mixture on LLMs has not been thoroughly explored. In this study, we classify instructions into three main types: NLP downstream tasks, coding, and general chatting, and investigate their impact on LLMs. Our findings reveal that specific types of instructions are more beneficial for particular uses, while it may cause harms to other aspects, emphasizing the importance of meticulously designing the instruction mixture to maximize model performance. This study sheds light on the instruction mixture and paves the way for future research.
NADI 2023: The Fourth Nuanced Arabic Dialect Identification Shared Task
Oct 24, 2023

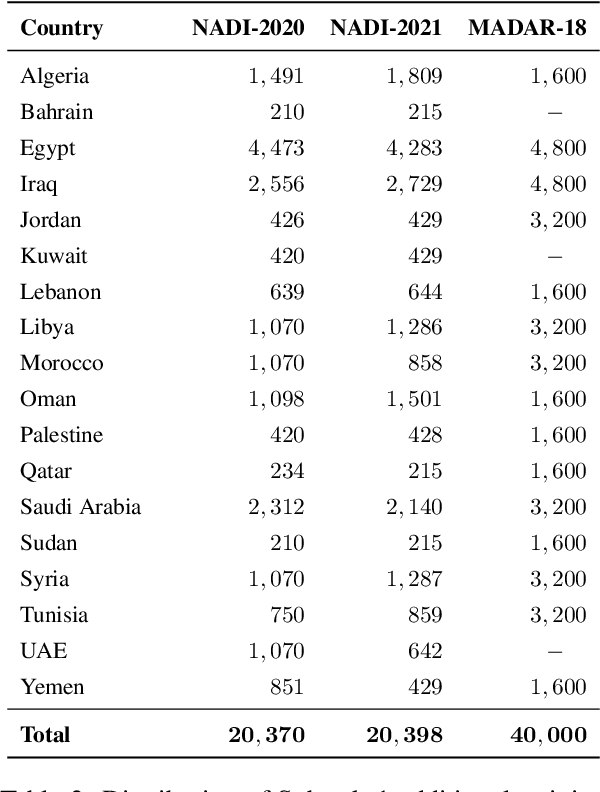
We describe the findings of the fourth Nuanced Arabic Dialect Identification Shared Task (NADI 2023). The objective of NADI is to help advance state-of-the-art Arabic NLP by creating opportunities for teams of researchers to collaboratively compete under standardized conditions. It does so with a focus on Arabic dialects, offering novel datasets and defining subtasks that allow for meaningful comparisons between different approaches. NADI 2023 targeted both dialect identification (Subtask 1) and dialect-to-MSA machine translation (Subtask 2 and Subtask 3). A total of 58 unique teams registered for the shared task, of whom 18 teams have participated (with 76 valid submissions during test phase). Among these, 16 teams participated in Subtask 1, 5 participated in Subtask 2, and 3 participated in Subtask 3. The winning teams achieved 87.27 F1 on Subtask 1, 14.76 Bleu in Subtask 2, and 21.10 Bleu in Subtask 3, respectively. Results show that all three subtasks remain challenging, thereby motivating future work in this area. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
The Skipped Beat: A Study of Sociopragmatic Understanding in LLMs for 64 Languages
Oct 23, 2023Instruction tuned large language models (LLMs), such as ChatGPT, demonstrate remarkable performance in a wide range of tasks. Despite numerous recent studies that examine the performance of instruction-tuned LLMs on various NLP benchmarks, there remains a lack of comprehensive investigation into their ability to understand cross-lingual sociopragmatic meaning (SM), i.e., meaning embedded within social and interactive contexts. This deficiency arises partly from SM not being adequately represented in any of the existing benchmarks. To address this gap, we present SPARROW, an extensive multilingual benchmark specifically designed for SM understanding. SPARROW comprises 169 datasets covering 13 task types across six primary categories (e.g., anti-social language detection, emotion recognition). SPARROW datasets encompass 64 different languages originating from 12 language families representing 16 writing scripts. We evaluate the performance of various multilingual pretrained language models (e.g., mT5) and instruction-tuned LLMs (e.g., BLOOMZ, ChatGPT) on SPARROW through fine-tuning, zero-shot, and/or few-shot learning. Our comprehensive analysis reveals that existing open-source instruction tuned LLMs still struggle to understand SM across various languages, performing close to a random baseline in some cases. We also find that although ChatGPT outperforms many LLMs, it still falls behind task-specific finetuned models with a gap of 12.19 SPARROW score. Our benchmark is available at: https://github.com/UBC-NLP/SPARROW
Detecting the Anomalies in LiDAR Pointcloud
Jul 31, 2023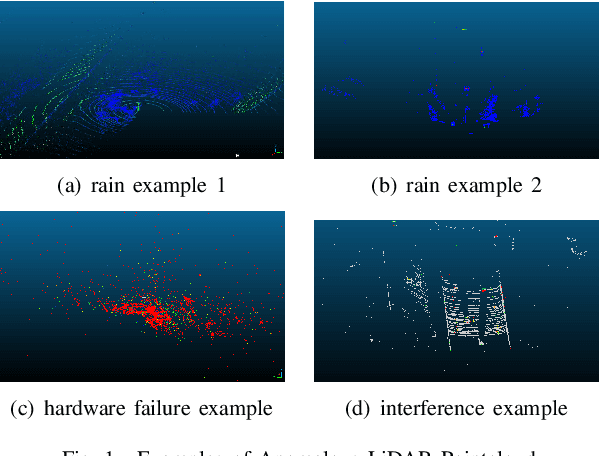
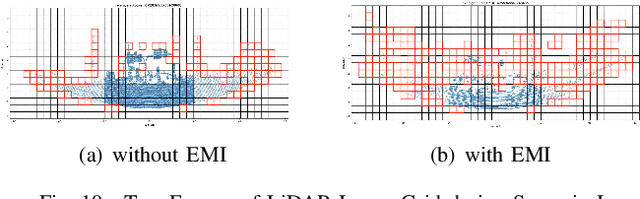

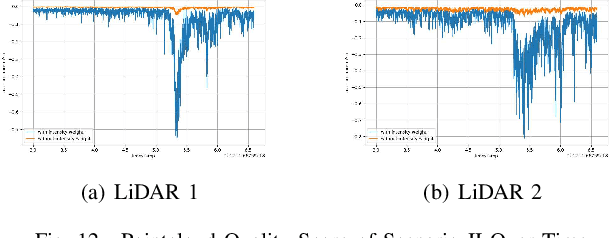
LiDAR sensors play an important role in the perception stack of modern autonomous driving systems. Adverse weather conditions such as rain, fog and dust, as well as some (occasional) LiDAR hardware fault may cause the LiDAR to produce pointcloud with abnormal patterns such as scattered noise points and uncommon intensity values. In this paper, we propose a novel approach to detect whether a LiDAR is generating anomalous pointcloud by analyzing the pointcloud characteristics. Specifically, we develop a pointcloud quality metric based on the LiDAR points' spatial and intensity distribution to characterize the noise level of the pointcloud, which relies on pure mathematical analysis and does not require any labeling or training as learning-based methods do. Therefore, the method is scalable and can be quickly deployed either online to improve the autonomy safety by monitoring anomalies in the LiDAR data or offline to perform in-depth study of the LiDAR behavior over large amount of data. The proposed approach is studied with extensive real public road data collected by LiDARs with different scanning mechanisms and laser spectrums, and is proven to be able to effectively handle various known and unknown sources of pointcloud anomaly.