 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition
Apr 09, 2019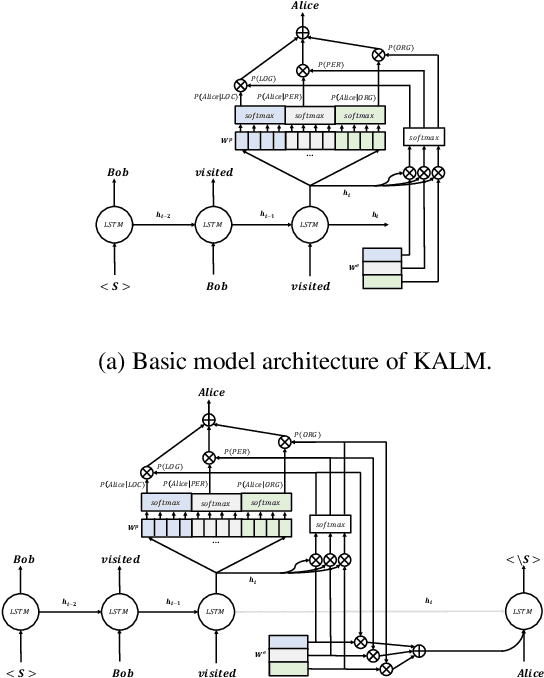
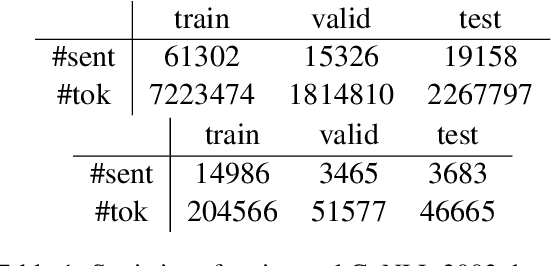
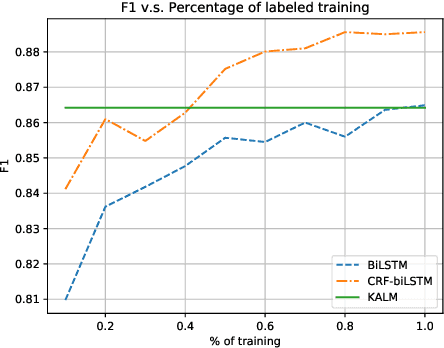
Traditional language models are unable to efficiently model entity names observed in text. All but the most popular named entities appear infrequently in text providing insufficient context. Recent efforts have recognized that context can be generalized between entity names that share the same type (e.g., \emph{person} or \emph{location}) and have equipped language models with access to an external knowledge base (KB). Our Knowledge-Augmented Language Model (KALM) continues this line of work by augmenting a traditional model with a KB. Unlike previous methods, however, we train with an end-to-end predictive objective optimizing the perplexity of text. We do not require any additional information such as named entity tags. In addition to improving language modeling performance, KALM learns to recognize named entities in an entirely unsupervised way by using entity type information latent in the model. On a Named Entity Recognition (NER) task, KALM achieves performance comparable with state-of-the-art supervised models. Our work demonstrates that named entities (and possibly other types of world knowledge) can be modeled successfully using predictive learning and training on large corpora of text without any additional information.
Context Models for OOV Word Translation in Low-Resource Languages
Jan 26, 2018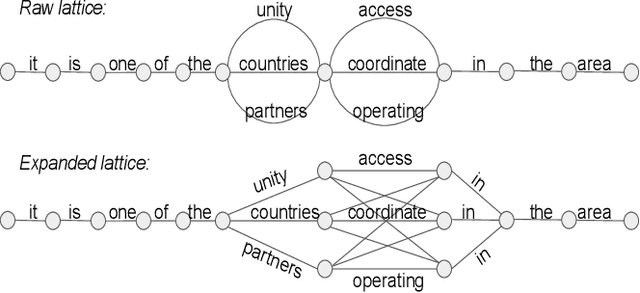
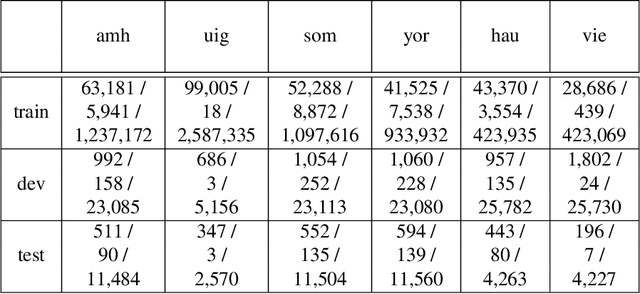
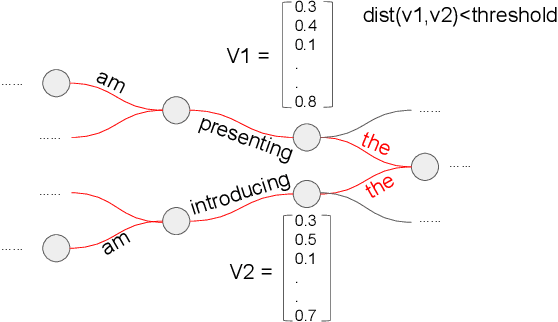
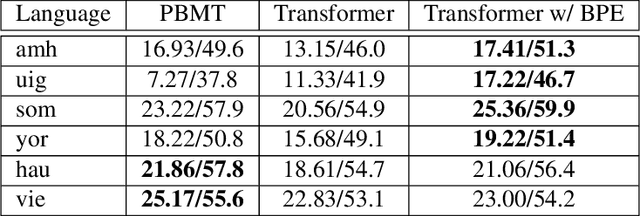
Out-of-vocabulary word translation is a major problem for the translation of low-resource languages that suffer from a lack of parallel training data. This paper evaluates the contributions of target-language context models towards the translation of OOV words, specifically in those cases where OOV translations are derived from external knowledge sources, such as dictionaries. We develop both neural and non-neural context models and evaluate them within both phrase-based and self-attention based neural machine translation systems. Our results show that neural language models that integrate additional context beyond the current sentence are the most effective in disambiguating possible OOV word translations. We present an efficient second-pass lattice-rescoring method for wide-context neural language models and demonstrate performance improvements over state-of-the-art self-attention based neural MT systems in five out of six low-resource language pairs.