 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition
Paper and Code
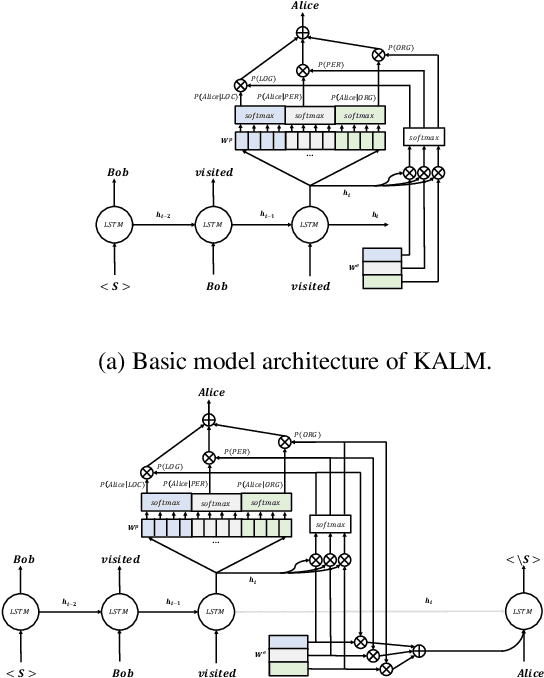
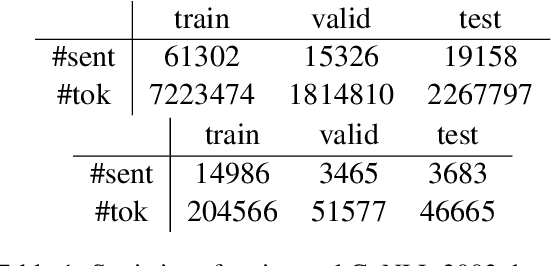
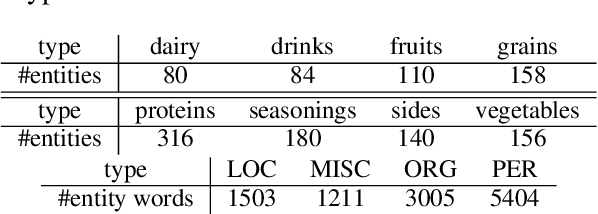
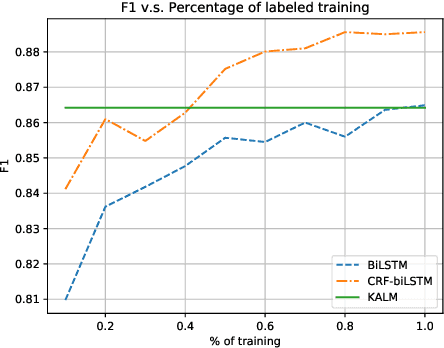
Traditional language models are unable to efficiently model entity names observed in text. All but the most popular named entities appear infrequently in text providing insufficient context. Recent efforts have recognized that context can be generalized between entity names that share the same type (e.g., \emph{person} or \emph{location}) and have equipped language models with access to an external knowledge base (KB). Our Knowledge-Augmented Language Model (KALM) continues this line of work by augmenting a traditional model with a KB. Unlike previous methods, however, we train with an end-to-end predictive objective optimizing the perplexity of text. We do not require any additional information such as named entity tags. In addition to improving language modeling performance, KALM learns to recognize named entities in an entirely unsupervised way by using entity type information latent in the model. On a Named Entity Recognition (NER) task, KALM achieves performance comparable with state-of-the-art supervised models. Our work demonstrates that named entities (and possibly other types of world knowledge) can be modeled successfully using predictive learning and training on large corpora of text without any additional information.