 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEF-2026 FinMMEval Lab: Multilingual and Multimodal Evaluation of Financial AI Systems
Feb 11, 2026We present the setup and the tasks of the FinMMEval Lab at CLEF 2026, which introduces the first multilingual and multimodal evaluation framework for financial Large Language Models (LLMs). While recent advances in financial natural language processing have enabled automated analysis of market reports, regulatory documents, and investor communications, existing benchmarks remain largely monolingual, text-only, and limited to narrow subtasks. FinMMEval 2026 addresses this gap by offering three interconnected tasks that span financial understanding, reasoning, and decision-making: Financial Exam Question Answering, Multilingual Financial Question Answering (PolyFiQA), and Financial Decision Making. Together, these tasks provide a comprehensive evaluation suite that measures models' ability to reason, generalize, and act across diverse languages and modalities. The lab aims to promote the development of robust, transparent, and globally inclusive financial AI systems, with datasets and evaluation resources publicly released to support reproducible research.
Evaluate Bias without Manual Test Sets: A Concept Representation Perspective for LLMs
May 21, 2025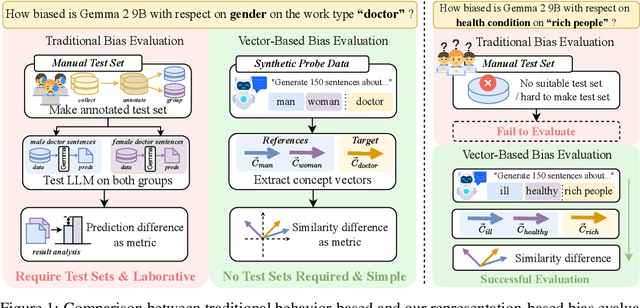
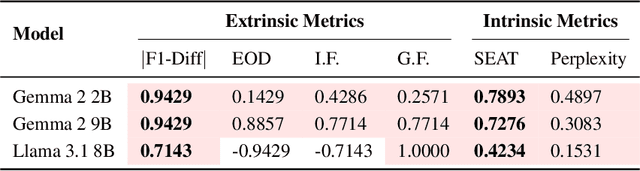
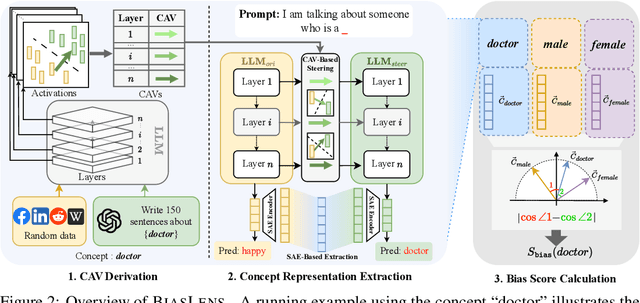
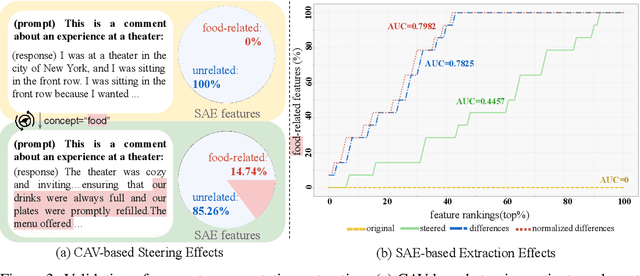
Bias in Large Language Models (LLMs) significantly undermines their reliability and fairness. We focus on a common form of bias: when two reference concepts in the model's concept space, such as sentiment polarities (e.g., "positive" and "negative"), are asymmetrically correlated with a third, target concept, such as a reviewing aspect, the model exhibits unintended bias. For instance, the understanding of "food" should not skew toward any particular sentiment. Existing bias evaluation methods assess behavioral differences of LLMs by constructing labeled data for different social groups and measuring model responses across them, a process that requires substantial human effort and captures only a limited set of social concepts. To overcome these limitations, we propose BiasLens, a test-set-free bias analysis framework based on the structure of the model's vector space. BiasLens combines Concept Activation Vectors (CAVs) with Sparse Autoencoders (SAEs) to extract interpretable concept representations, and quantifies bias by measuring the variation in representational similarity between the target concept and each of the reference concepts. Even without labeled data, BiasLens shows strong agreement with traditional bias evaluation metrics (Spearman correlation r > 0.85). Moreover, BiasLens reveals forms of bias that are difficult to detect using existing methods. For example, in simulated clinical scenarios, a patient's insurance status can cause the LLM to produce biased diagnostic assessments. Overall, BiasLens offers a scalable, interpretable, and efficient paradigm for bias discovery, paving the way for improving fairness and transparency in LLMs.
Towards A Unified View of Sparse Feed-Forward Network in Pretraining Large Language Model
May 23, 2023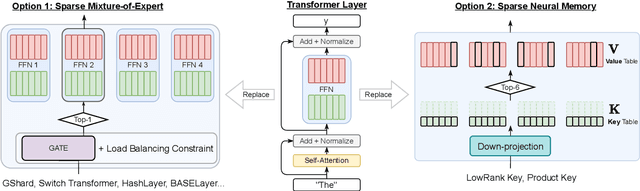
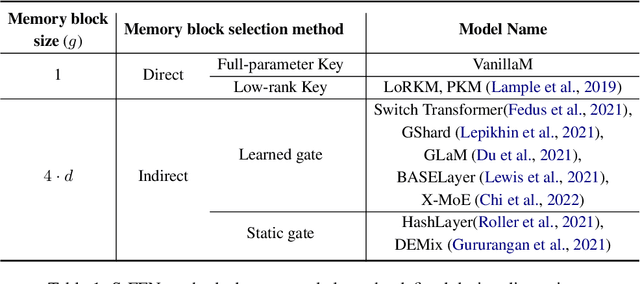

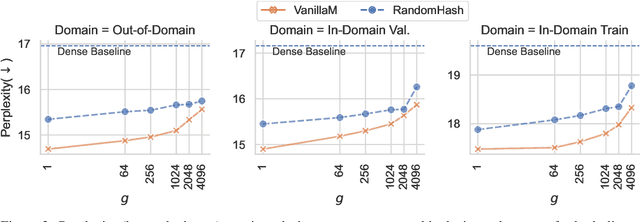
Large and sparse feed-forward networks (S-FFN) such as Mixture-of-Experts (MoE) have demonstrated to be an efficient approach for scaling up Transformers model size for pretraining large language models. By only activating part of the FFN parameters conditioning on input, S-FFN improves generalization performance while keeping training and inference costs (in FLOPs) fixed. In this work, we analyzed the two major design choices of S-FFN: the memory block (or expert) size and the memory block selection method under a general conceptual framework of sparse neural memory. Using this unified framework, we compare several S-FFN architectures for language modeling and provide insights into their relative efficacy and efficiency. From our analysis results, we found a simpler selection method -- Avg-K that selects blocks through their mean aggregated hidden states, achieves lower perplexity in language modeling pretraining compared to existing MoE architectures.
Improving In-Context Few-Shot Learning via Self-Supervised Training
May 03, 2022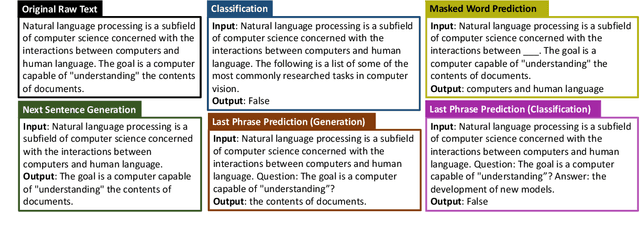

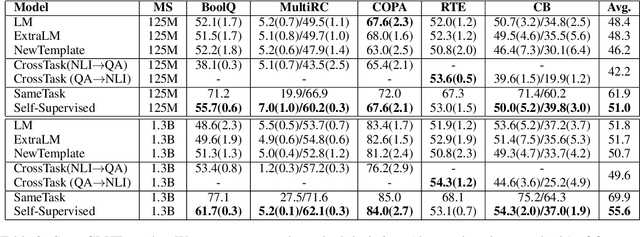

Self-supervised pretraining has made few-shot learning possible for many NLP tasks. But the pretraining objectives are not typically adapted specifically for in-context few-shot learning. In this paper, we propose to use self-supervision in an intermediate training stage between pretraining and downstream few-shot usage with the goal to teach the model to perform in-context few shot learning. We propose and evaluate four self-supervised objectives on two benchmarks. We find that the intermediate self-supervision stage produces models that outperform strong baselines. Ablation study shows that several factors affect the downstream performance, such as the amount of training data and the diversity of the self-supervised objectives. Human-annotated cross-task supervision and self-supervision are complementary. Qualitative analysis suggests that the self-supervised-trained models are better at following task requirements.
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
Apr 03, 2022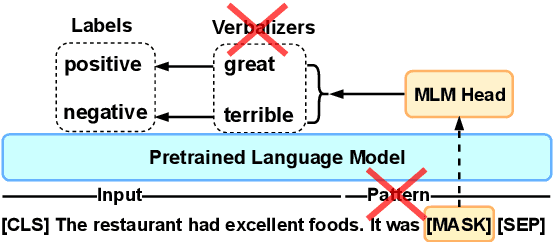
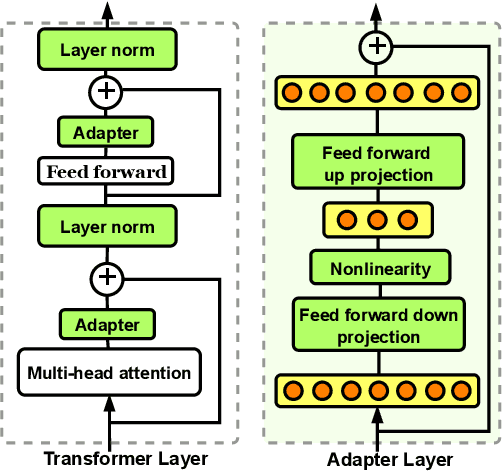
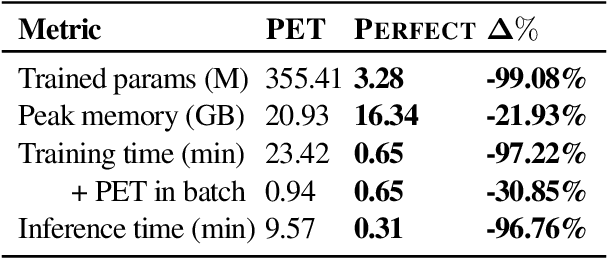
Current methods for few-shot fine-tuning of pretrained masked language models (PLMs) require carefully engineered prompts and verbalizers for each new task to convert examples into a cloze-format that the PLM can score. In this work, we propose PERFECT, a simple and efficient method for few-shot fine-tuning of PLMs without relying on any such handcrafting, which is highly effective given as few as 32 data points. PERFECT makes two key design choices: First, we show that manually engineered task prompts can be replaced with task-specific adapters that enable sample-efficient fine-tuning and reduce memory and storage costs by roughly factors of 5 and 100, respectively. Second, instead of using handcrafted verbalizers, we learn new multi-token label embeddings during fine-tuning, which are not tied to the model vocabulary and which allow us to avoid complex auto-regressive decoding. These embeddings are not only learnable from limited data but also enable nearly 100x faster training and inference. Experiments on a wide range of few-shot NLP tasks demonstrate that PERFECT, while being simple and efficient, also outperforms existing state-of-the-art few-shot learning methods. Our code is publicly available at https://github.com/rabeehk/perfect.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021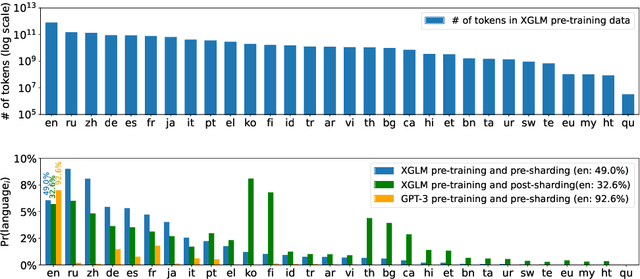
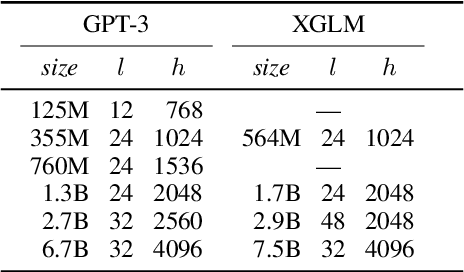
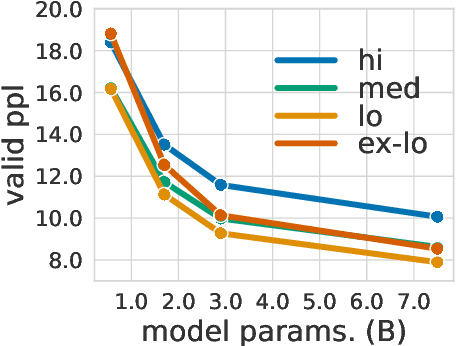

Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
Nov 26, 2021

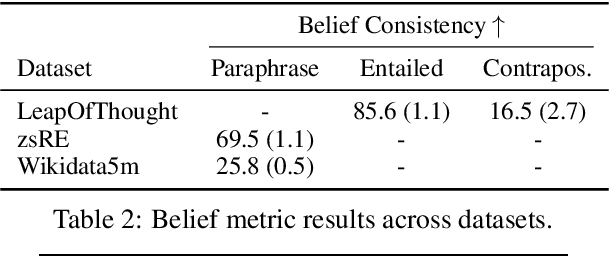
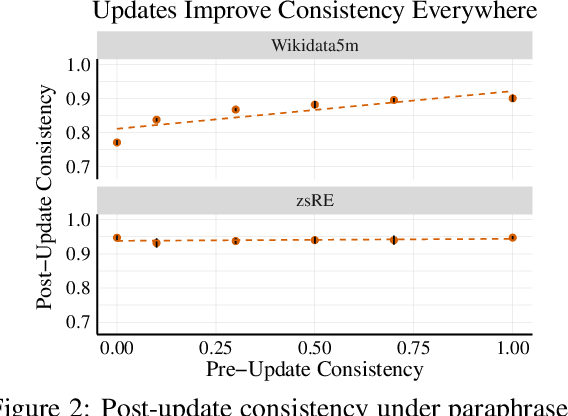
Do language models have beliefs about the world? Dennett (1995) famously argues that even thermostats have beliefs, on the view that a belief is simply an informational state decoupled from any motivational state. In this paper, we discuss approaches to detecting when models have beliefs about the world, and we improve on methods for updating model beliefs to be more truthful, with a focus on methods based on learned optimizers or hypernetworks. Our main contributions include: (1) new metrics for evaluating belief-updating methods that focus on the logical consistency of beliefs, (2) a training objective for Sequential, Local, and Generalizing model updates (SLAG) that improves the performance of learned optimizers, and (3) the introduction of the belief graph, which is a new form of interface with language models that shows the interdependencies between model beliefs. Our experiments suggest that models possess belief-like qualities to only a limited extent, but update methods can both fix incorrect model beliefs and greatly improve their consistency. Although off-the-shelf optimizers are surprisingly strong belief-updating baselines, our learned optimizers can outperform them in more difficult settings than have been considered in past work. Code is available at https://github.com/peterbhase/SLAG-Belief-Updating
Multi-task Retrieval for Knowledge-Intensive Tasks
Jan 01, 2021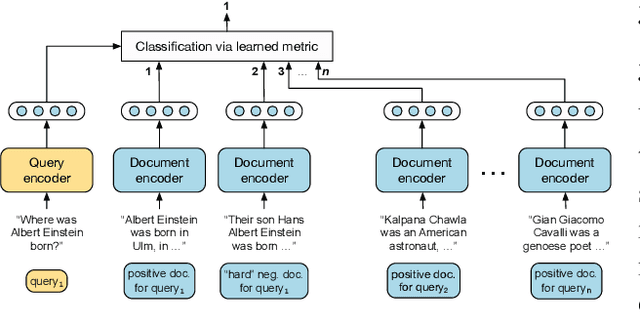

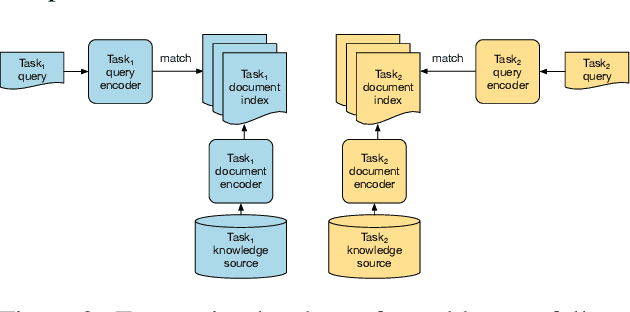
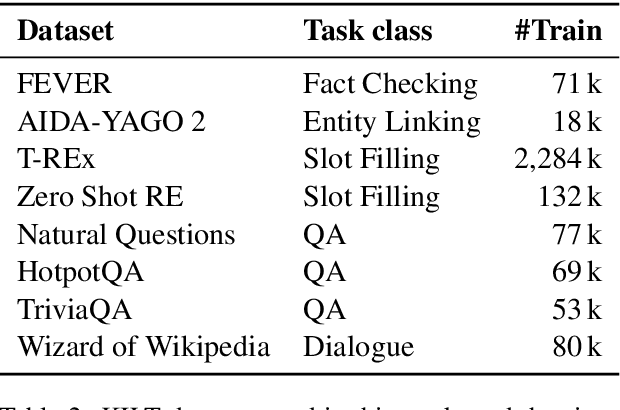
Retrieving relevant contexts from a large corpus is a crucial step for tasks such as open-domain question answering and fact checking. Although neural retrieval outperforms traditional methods like tf-idf and BM25, its performance degrades considerably when applied to out-of-domain data. Driven by the question of whether a neural retrieval model can be universal and perform robustly on a wide variety of problems, we propose a multi-task trained model. Our approach not only outperforms previous methods in the few-shot setting, but also rivals specialised neural retrievers, even when in-domain training data is abundant. With the help of our retriever, we improve existing models for downstream tasks and closely match or improve the state of the art on multiple benchmarks.
General Purpose Text Embeddings from Pre-trained Language Models for Scalable Inference
Apr 29, 2020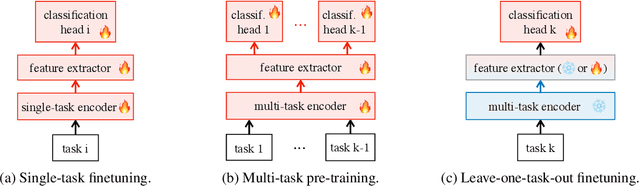
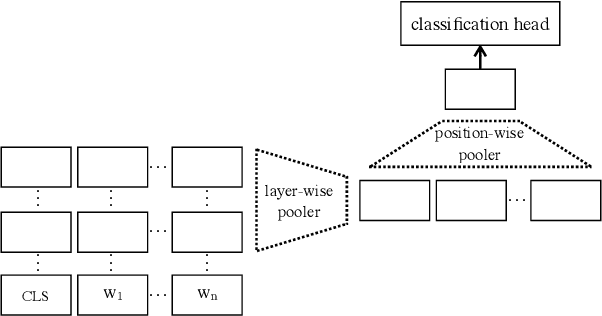
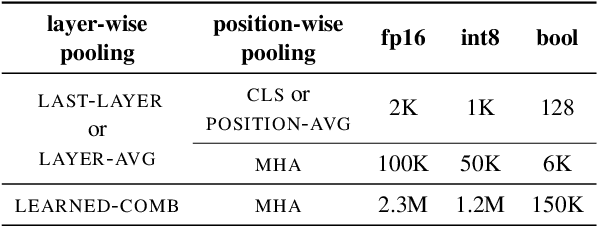
The state of the art on many NLP tasks is currently achieved by large pre-trained language models, which require a considerable amount of computation. We explore a setting where many different predictions are made on a single piece of text. In that case, some of the computational cost during inference can be amortized over the different tasks using a shared text encoder. We compare approaches for training such an encoder and show that encoders pre-trained over multiple tasks generalize well to unseen tasks. We also compare ways of extracting fixed- and limited-size representations from this encoder, including different ways of pooling features extracted from multiple layers or positions. Our best approach compares favorably to knowledge distillation, achieving higher accuracy and lower computational cost once the system is handling around 7 tasks. Further, we show that through binary quantization, we can reduce the size of the extracted representations by a factor of 16 making it feasible to store them for later use. The resulting method offers a compelling solution for using large-scale pre-trained models at a fraction of the computational cost when multiple tasks are performed on the same text.
Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
Dec 20, 2019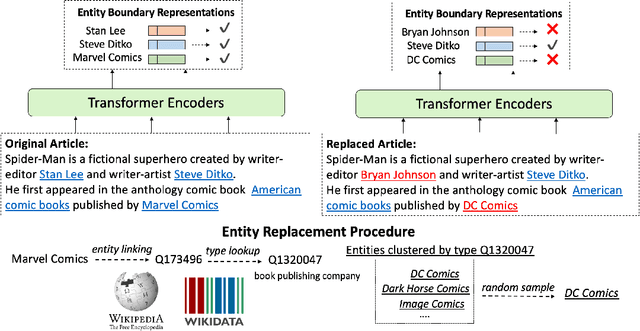
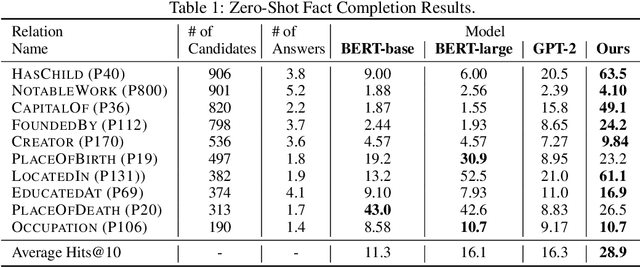

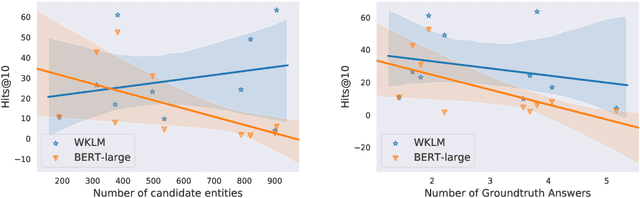
Recent breakthroughs of pretrained language models have shown the effectiveness of self-supervised learning for a wide range of natural language processing (NLP) tasks. In addition to standard syntactic and semantic NLP tasks, pretrained models achieve strong improvements on tasks that involve real-world knowledge, suggesting that large-scale language modeling could be an implicit method to capture knowledge. In this work, we further investigate the extent to which pretrained models such as BERT capture knowledge using a zero-shot fact completion task. Moreover, we propose a simple yet effective weakly supervised pretraining objective, which explicitly forces the model to incorporate knowledge about real-world entities. Models trained with our new objective yield significant improvements on the fact completion task. When applied to downstream tasks, our model consistently outperforms BERT on four entity-related question answering datasets (i.e., WebQuestions, TriviaQA, SearchQA and Quasar-T) with an average 2.7 F1 improvements and a standard fine-grained entity typing dataset (i.e., FIGER) with 5.7 accuracy gains.