 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAFITE: Generative Regression Analysis Framework for Issue Tracking and Evaluation
Mar 18, 2026Large language models (LLMs) are largely motivated by their performance on popular topics and benchmarks at the time of their release. However, over time, contamination occurs due to significant exposure of benchmark data during training. This poses a risk of model performance inflation if testing is not carefully executed. To address this challenge, we present GRAFITE, a continuous LLM evaluation platform through a comprehensive system for maintaining and evaluating model issues. Our approach enables building a repository of model problems based on user feedback over time and offers a pipeline for assessing LLMs against these issues through quality assurance (QA) tests using LLM-as-a-judge. The platform enables side-by-side comparison of multiple models, facilitating regression detection across different releases. The platform is available at https://github.com/IBM/grafite. The demo video is available at www.youtube.com/watch?v=XFZyoleN56k.
MTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations
Feb 26, 2026We present MTRAG-UN, a benchmark for exploring open challenges in multi-turn retrieval augmented generation, a popular use of large language models. We release a benchmark of 666 tasks containing over 2,800 conversation turns across 6 domains with accompanying corpora. Our experiments show that retrieval and generation models continue to struggle on conversations with UNanswerable, UNderspecified, and NONstandalone questions and UNclear responses. Our benchmark is available at https://github.com/IBM/mt-rag-benchmark
Granite Embedding Models
Feb 27, 2025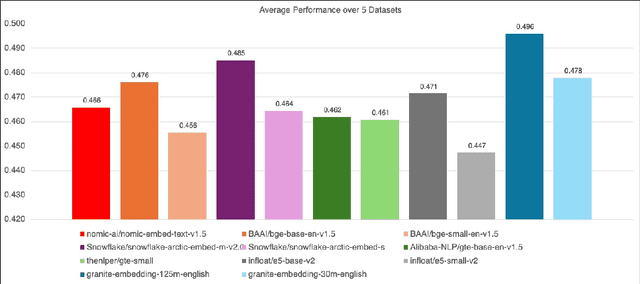



We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems
Apr 02, 2024Retrieval Augmented Generation (RAG) has become a popular application for large language models. It is preferable that successful RAG systems provide accurate answers that are supported by being grounded in a passage without any hallucinations. While considerable work is required for building a full RAG pipeline, being able to benchmark performance is also necessary. We present ClapNQ, a benchmark Long-form Question Answering dataset for the full RAG pipeline. ClapNQ includes long answers with grounded gold passages from Natural Questions (NQ) and a corpus to perform either retrieval, generation, or the full RAG pipeline. The ClapNQ answers are concise, 3x smaller than the full passage, and cohesive, with multiple pieces of the passage that are not contiguous. RAG models must adapt to these properties to be successful at ClapNQ. We present baseline experiments and analysis for ClapNQ that highlight areas where there is still significant room for improvement in grounded RAG. CLAPNQ is publicly available at https://github.com/primeqa/clapnq
Muted: Multilingual Targeted Offensive Speech Identification and Visualization
Dec 18, 2023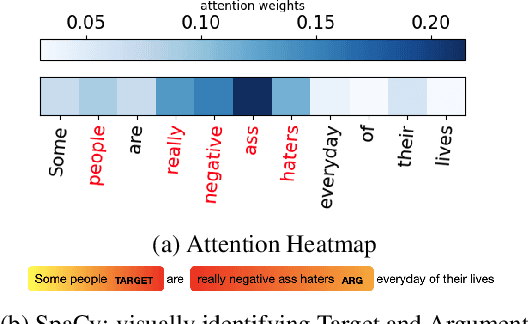

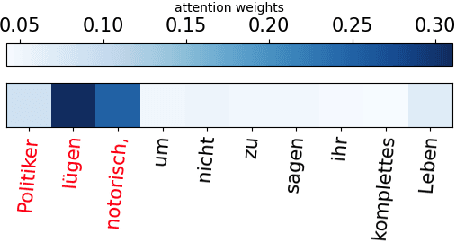

Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022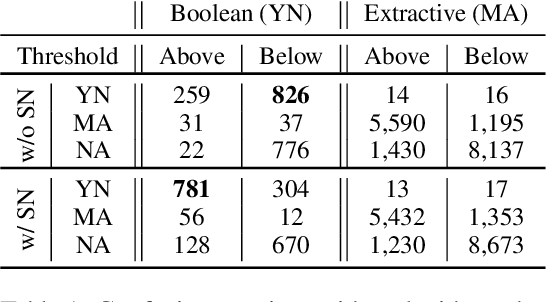
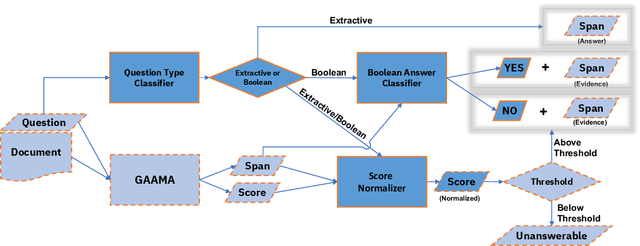


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Task Transfer and Domain Adaptation for Zero-Shot Question Answering
Jun 14, 2022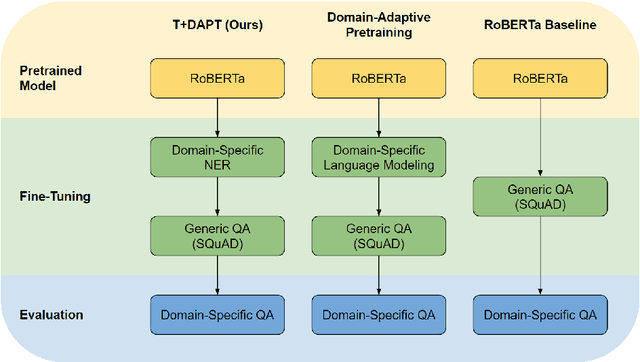

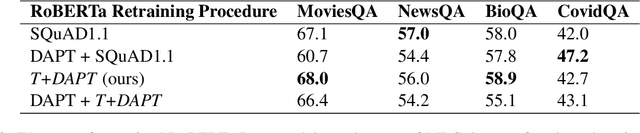

Pretrained language models have shown success in various areas of natural language processing, including reading comprehension tasks. However, when applying machine learning methods to new domains, labeled data may not always be available. To address this, we use supervised pretraining on source-domain data to reduce sample complexity on domain-specific downstream tasks. We evaluate zero-shot performance on domain-specific reading comprehension tasks by combining task transfer with domain adaptation to fine-tune a pretrained model with no labelled data from the target task. Our approach outperforms Domain-Adaptive Pretraining on downstream domain-specific reading comprehension tasks in 3 out of 4 domains.
Do Answers to Boolean Questions Need Explanations? Yes
Dec 14, 2021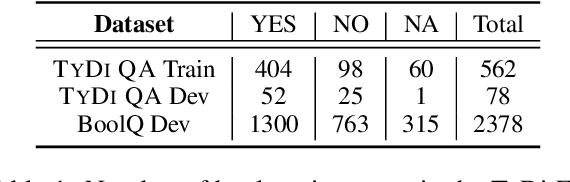


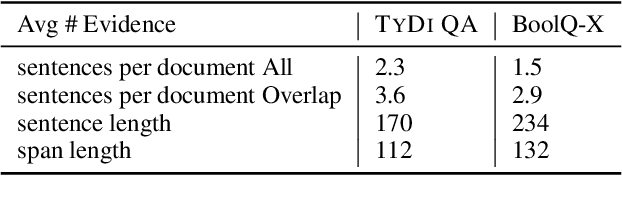
Existing datasets that contain boolean questions, such as BoolQ and TYDI QA , provide the user with a YES/NO response to the question. However, a one word response is not sufficient for an explainable system. We promote explainability by releasing a new set of annotations marking the evidence in existing TyDi QA and BoolQ datasets. We show that our annotations can be used to train a model that extracts improved evidence spans compared to models that rely on existing resources. We confirm our findings with a user study which shows that our extracted evidence spans enhance the user experience. We also provide further insight into the challenges of answering boolean questions, such as passages containing conflicting YES and NO answers, and varying degrees of relevance of the predicted evidence.