 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language Models to Practical Self-Improving Computer Agents
Apr 18, 2024We develop a simple and straightforward methodology to create AI computer agents that can carry out diverse computer tasks and self-improve by developing tools and augmentations to enable themselves to solve increasingly complex tasks. As large language models (LLMs) have been shown to benefit from non-parametric augmentations, a significant body of recent work has focused on developing software that augments LLMs with various capabilities. Rather than manually developing static software to augment LLMs through human engineering effort, we propose that an LLM agent can systematically generate software to augment itself. We show, through a few case studies, that a minimal querying loop with appropriate prompt engineering allows an LLM to generate and use various augmentations, freely extending its own capabilities to carry out real-world computer tasks. Starting with only terminal access, we prompt an LLM agent to augment itself with retrieval, internet search, web navigation, and text editor capabilities. The agent effectively uses these various tools to solve problems including automated software development and web-based tasks.
Task Transfer and Domain Adaptation for Zero-Shot Question Answering
Jun 14, 2022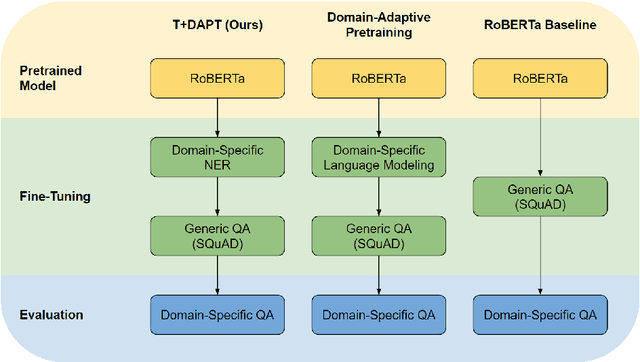

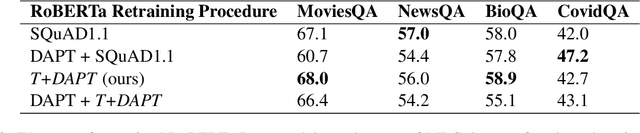

Pretrained language models have shown success in various areas of natural language processing, including reading comprehension tasks. However, when applying machine learning methods to new domains, labeled data may not always be available. To address this, we use supervised pretraining on source-domain data to reduce sample complexity on domain-specific downstream tasks. We evaluate zero-shot performance on domain-specific reading comprehension tasks by combining task transfer with domain adaptation to fine-tune a pretrained model with no labelled data from the target task. Our approach outperforms Domain-Adaptive Pretraining on downstream domain-specific reading comprehension tasks in 3 out of 4 domains.
An Initial Look at Self-Reprogramming Artificial Intelligence
Apr 30, 2022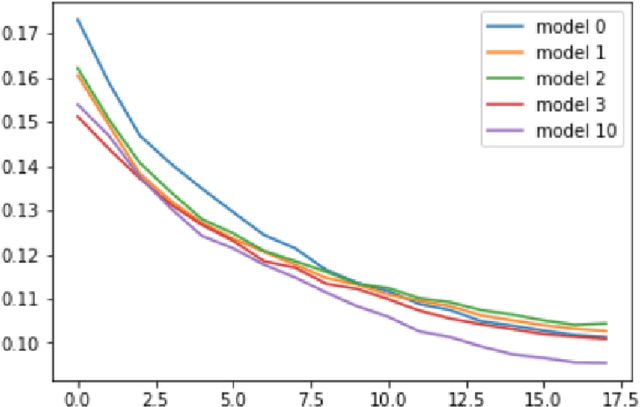
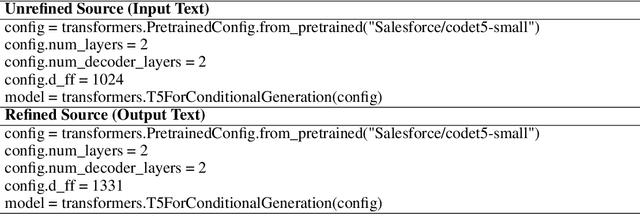
Rapid progress in deep learning research has greatly extended the capabilities of artificial intelligence technology. Conventional AI models are constrained to explicit human-designed algorithms, although a growing body of work in meta-learning, neural architecture search, and related approaches have explored algorithms that self-modify to some extent. In this paper, we develop and experimentally validate the first fully self-reprogramming AI system. Applying AI-based computer code generation to AI itself, we implement an algorithm with the ability to continuously modify and rewrite its own neural network source code.
Distributed Evolution Strategies Using TPUs for Meta-Learning
Jan 01, 2022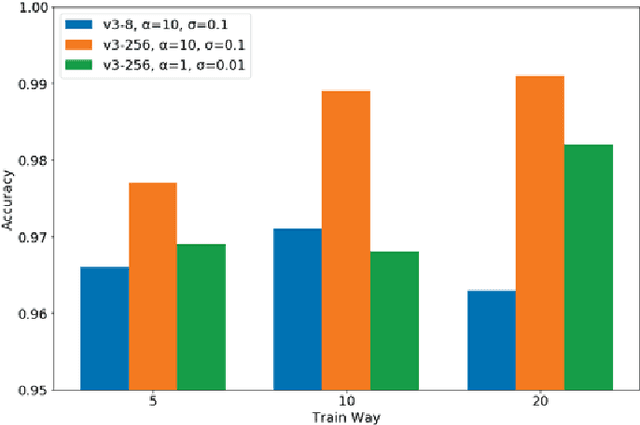
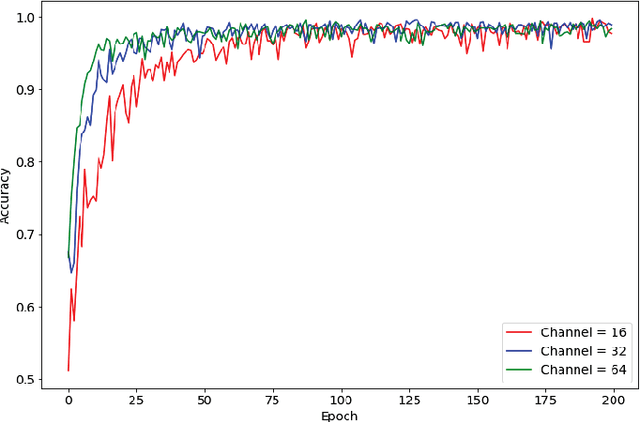
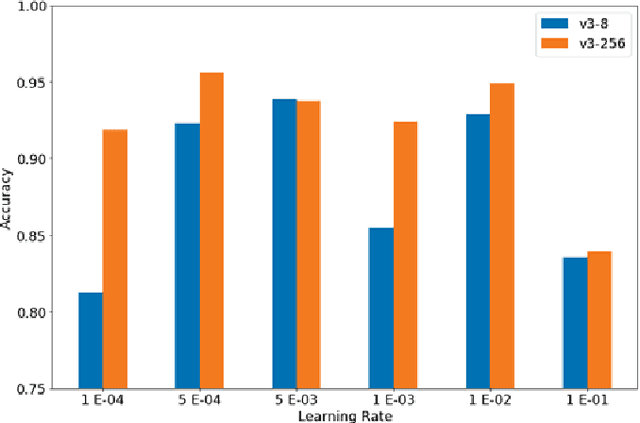
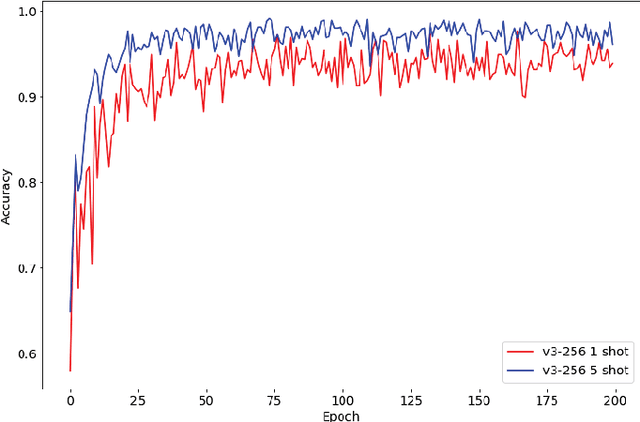
Meta-learning traditionally relies on backpropagation through entire tasks to iteratively improve a model's learning dynamics. However, this approach is computationally intractable when scaled to complex tasks. We propose a distributed evolutionary meta-learning strategy using Tensor Processing Units (TPUs) that is highly parallel and scalable to arbitrarily long tasks with no increase in memory cost. Using a Prototypical Network trained with evolution strategies on the Omniglot dataset, we achieved an accuracy of 98.4% on a 5-shot classification problem. Our algorithm used as much as 40 times less memory than automatic differentiation to compute the gradient, with the resulting model achieving accuracy within 1.3% of a backpropagation-trained equivalent (99.6%). We observed better classification accuracy as high as 99.1% with larger population configurations. We further experimentally validate the stability and performance of ES-ProtoNet across a variety of training conditions (varying population size, model size, number of workers, shot, way, ES hyperparameters, etc.). Our contributions are twofold: we provide the first assessment of evolutionary meta-learning in a supervised setting, and create a general framework for distributed evolution strategies on TPUs.
* Published in Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI)