Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Transfer and Domain Adaptation for Zero-Shot Question Answering
Paper and Code
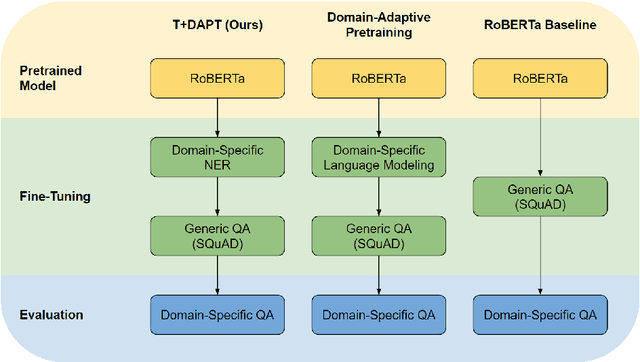

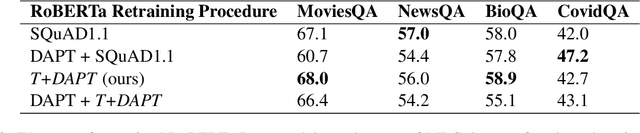

Pretrained language models have shown success in various areas of natural language processing, including reading comprehension tasks. However, when applying machine learning methods to new domains, labeled data may not always be available. To address this, we use supervised pretraining on source-domain data to reduce sample complexity on domain-specific downstream tasks. We evaluate zero-shot performance on domain-specific reading comprehension tasks by combining task transfer with domain adaptation to fine-tune a pretrained model with no labelled data from the target task. Our approach outperforms Domain-Adaptive Pretraining on downstream domain-specific reading comprehension tasks in 3 out of 4 domains.
* NAACL 2022 Deep Learning for Low-Resource NLP Workshop Paper
View paper on